 m4rrc0
commented
6 years ago
m4rrc0
commented
6 years ago Thanks a lot for the research @pieh . Maybe I am completely off road here but couldn't we use schema stitching to add missing fields? But maybe it could not solve the issue 1 you raise (conflicting types on a field) and it probably is a weaker solution overall on the long run...? I love your idea about live preview refresh! That would be a super solid feature to add to Gatsby IMHO. To be honest my main concern is the time such a refactor will take...
 pieh
pieh KyleAMathews
KyleAMathews jlengstorf
jlengstorf i8ramin
i8ramin niklasravnsborg
niklasravnsborg calcsam
calcsam stefanprobst
stefanprobst freiksenet
freiksenet rexxars
rexxars
Who will own this?
What Area of Responsibility does this fall into? Who will own the work, and who needs to be aware of the work?
Area of Responsibility:
Select the Area of Responsibility most impacted by this Epic
[ ] Sales
Summary
Make graphql schema generation code more maintainable and easier to add new features like allowing user specified types on fields instead of automatic inferring.
How will this impact Gatsby?
Domains
List the impacted domains here
Components
List the impacted Components here
Goals
What are the top 3 goals you want to accomplish with this epic? All goals should be specific, measurable, actionable, realistic, and timebound.
How will we know this epic is a success?
What changes must we see, or what must be created for us to know the project was a success. How will we know when the project is done? How will we measure success?
User Can Statement
Metrics to Measure Success
Additional Description
In a few sentences, describe the current status of the epic, what we know, and what's already been done.
What are the risks to the epic?
In a few sentences, describe what high-level questions we still need to answer about the project. How could this go wrong? What are the trade-offs? Do we need to close a door to go through this one?
What questions do we still need to answer, or what resources do we need?
Is there research to be done? Are there things we don’t know? Are there documents we need access to? Is there contact info we need? Add those questions as bullet points here.
How will we complete the epic?
What are the steps involved in taking this from idea through to reality?
How else could we accomplish the same goal?
Are there other ways to accomplish the goals you listed above? How else could we do the same thing?
--- This is stub epic - need to convert old description to new format
Main issue im trying to solve is that type inferring will not create fields/types for source data that:
My approach to handle that is to allow defining field types by
Filenodes will always have same data structure)Problem:
Current implementation of schema creation looks something like this:
Input/output type creation is not abstracted and implementation has to be duplicated for each source of information.
In my proof of concept ( repository ) I added another source (graphql schema definition language) and just implemented subset of functionality:
As testing ground I used this barebones repository. Things to look for:
Implementing it way this way is fine for proof of concept but it’s unmaintainable in long term. So I want to introduce common middleman interface: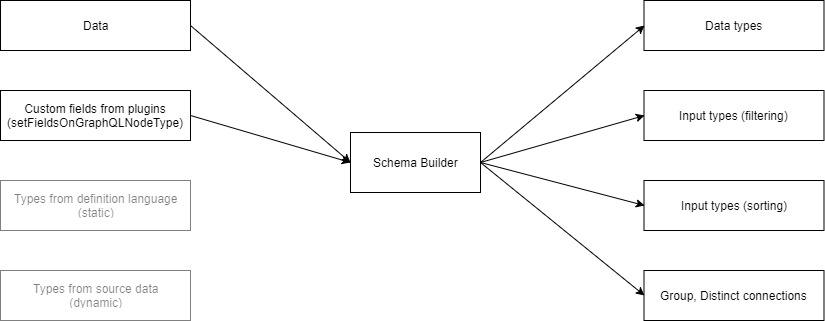
Goals:
Questions:
developmode but it can refresh data (builtin refresh for filesystem source +__refreshhook to refresh all source data) - it might be worth looking to be able to refresh schema too?markdownetc and then we have fields from github graphql apirepository- if there’s no connection between them then then this would be out of scope for this RFC), but if we would like to add connection - for example allow linking frontmatter field to github repository then this would need to be thought out ahead of time. I was looking atgraphql-toolsschema stitching and it does have some nice tooling for merging schemas and option to add resolvers between schemas - is this something that was planned to be used for that?