 rcatlord
commented
5 years ago
rcatlord
commented
5 years ago Hi Robin - here's my entry to the 'best reproducible map' competition. The R code retrieves and plots allotments from OpenStreetMap for your chosen Local Authority.
library(sf) ; library(osmdata) ; library(tidyverse) ; library(tmap)
#> Linking to GEOS 3.6.1, GDAL 2.1.3, PROJ 4.9.3
#> Data (c) OpenStreetMap contributors, ODbL 1.0. http://www.openstreetmap.org/copyright
#> Warning: package 'tibble' was built under R version 3.5.2
#> Warning: package 'tidyr' was built under R version 3.5.2
#> Warning: package 'purrr' was built under R version 3.5.2
#> Warning: package 'dplyr' was built under R version 3.5.2
#> Warning: package 'stringr' was built under R version 3.5.2
#> Warning: package 'tmap' was built under R version 3.5.2
lad <- URLencode("Manchester")
boundary <- st_read(paste0("https://ons-inspire.esriuk.com/arcgis/rest/services/Administrative_Boundaries/Local_Authority_Districts_April_2019_Boundaries_UK_BGC/MapServer/0/query?where=lad19nm%20=%20%27", lad, "%27&outFields=lad19cd,lad19nm,long,lat&outSR=4326&f=geojson"))
#> Reading layer `OGRGeoJSON' from data source `https://ons-inspire.esriuk.com/arcgis/rest/services/Administrative_Boundaries/Local_Authority_Districts_April_2019_Boundaries_UK_BGC/MapServer/0/query?where=lad19nm%20=%20%27Manchester%27&outFields=lad19cd,lad19nm,long,lat&outSR=4326&f=geojson' using driver `GeoJSON'
#> Simple feature collection with 1 feature and 4 fields
#> geometry type: POLYGON
#> dimension: XY
#> bbox: xmin: -2.319919 ymin: 53.34012 xmax: -2.146828 ymax: 53.54461
#> epsg (SRID): 4326
#> proj4string: +proj=longlat +datum=WGS84 +no_defs
coords <- st_bbox(boundary) %>% as.vector()
osm <- opq(bbox = coords) %>%
add_osm_feature(key = "landuse", value = "allotments") %>%
osmdata_sf()
osm_polygons <- osm$osm_polygons
names(osm_polygons$geometry) <- NULL
feature <- osm_polygons %>%
st_transform(st_crs(boundary)) %>%
st_intersection(., boundary)
#> although coordinates are longitude/latitude, st_intersection assumes that they are planar
#> Warning: attribute variables are assumed to be spatially constant
#> throughout all geometries
tmap_mode("view")
#> tmap mode set to interactive viewing
tm_shape(boundary) +
tm_fill(
col = "#DDDDCC",
alpha = 0.5,
popup.vars = c("Name" = "lad19nm")
) +
tm_borders() +
tm_shape(feature) +
tm_fill(
col = "#7cfc00",
popup.vars = c("Name" = "name")
) +
tm_borders() +
tm_layout(title = paste0("Allotments in ", lad)) +
tm_basemap(server = "Esri.WorldGrayCanvas", alpha = 0.5)
Created on 2019-04-18 by the reprex package (v0.2.1)
 dataandcrowd
dataandcrowd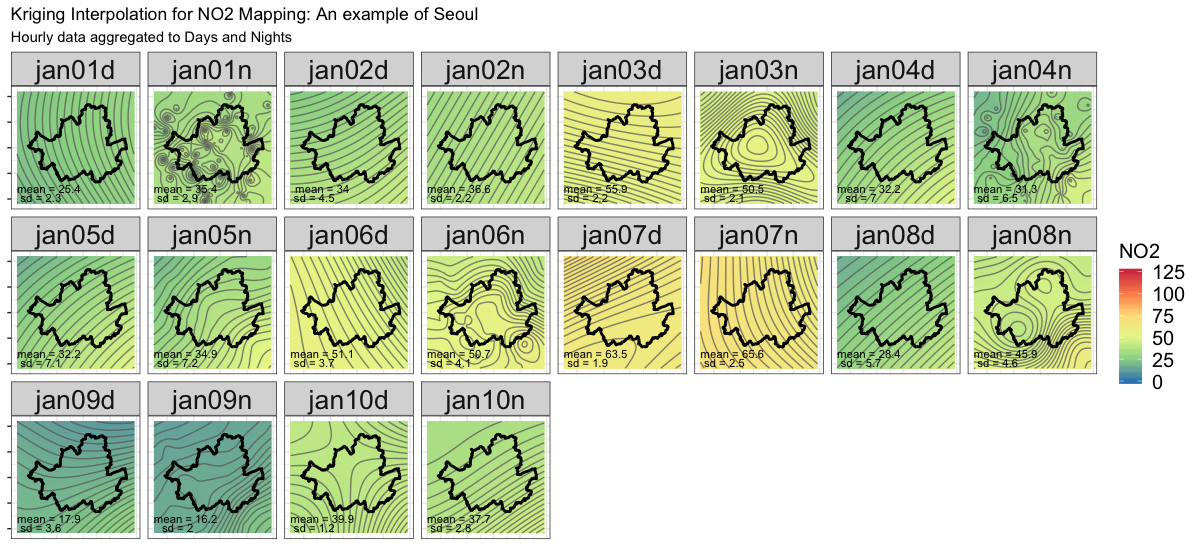
 agila5
agila5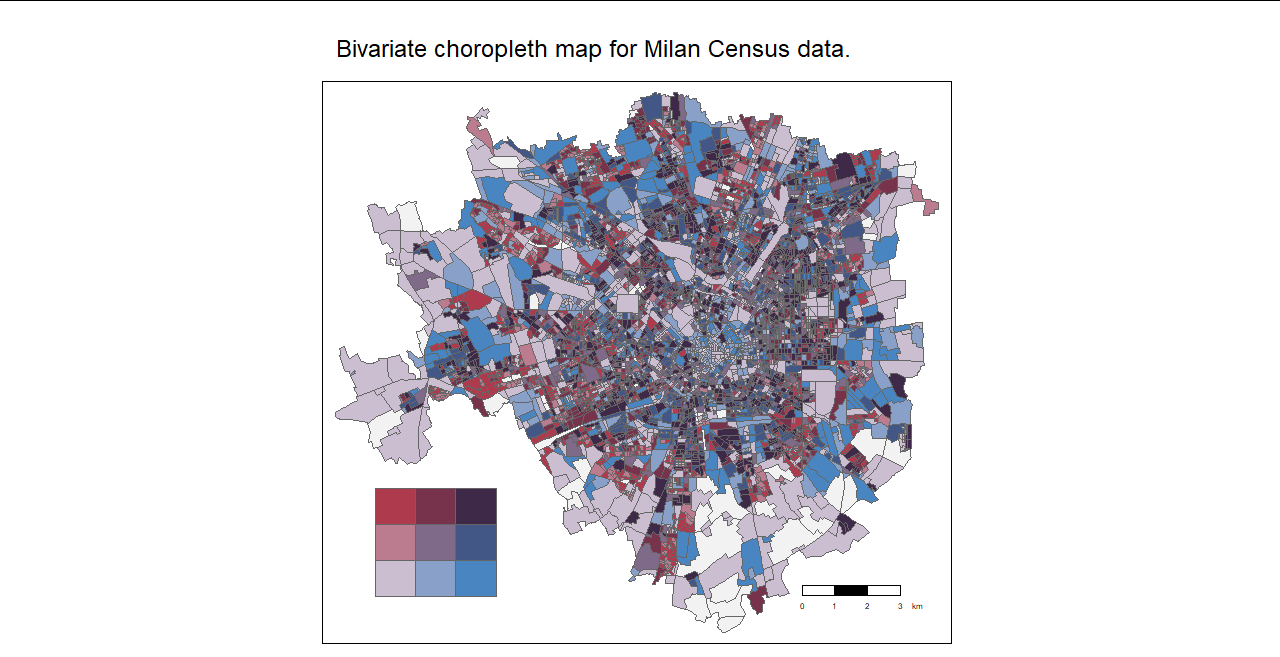
 kchastko
kchastko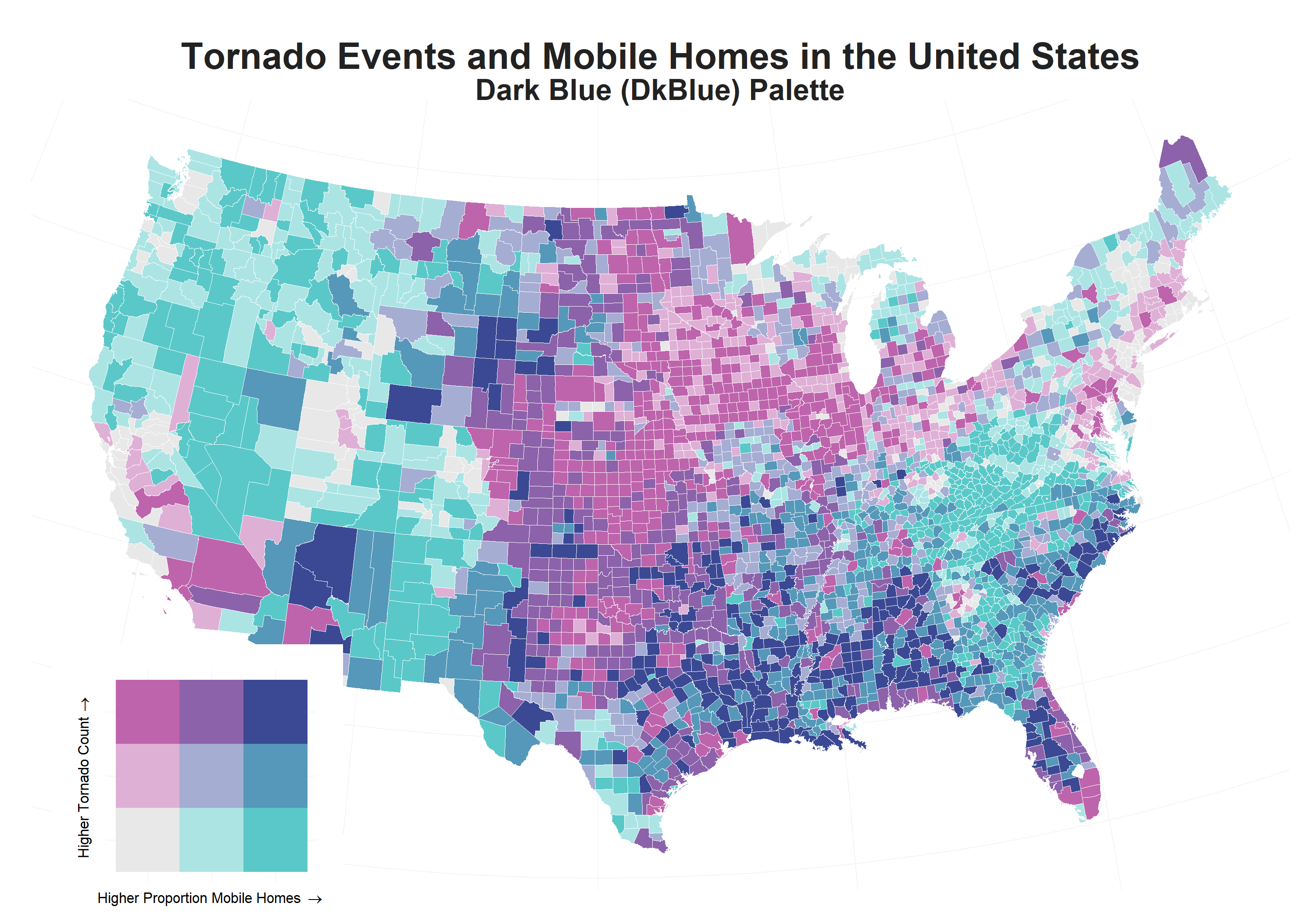
 Robinlovelace
Robinlovelace
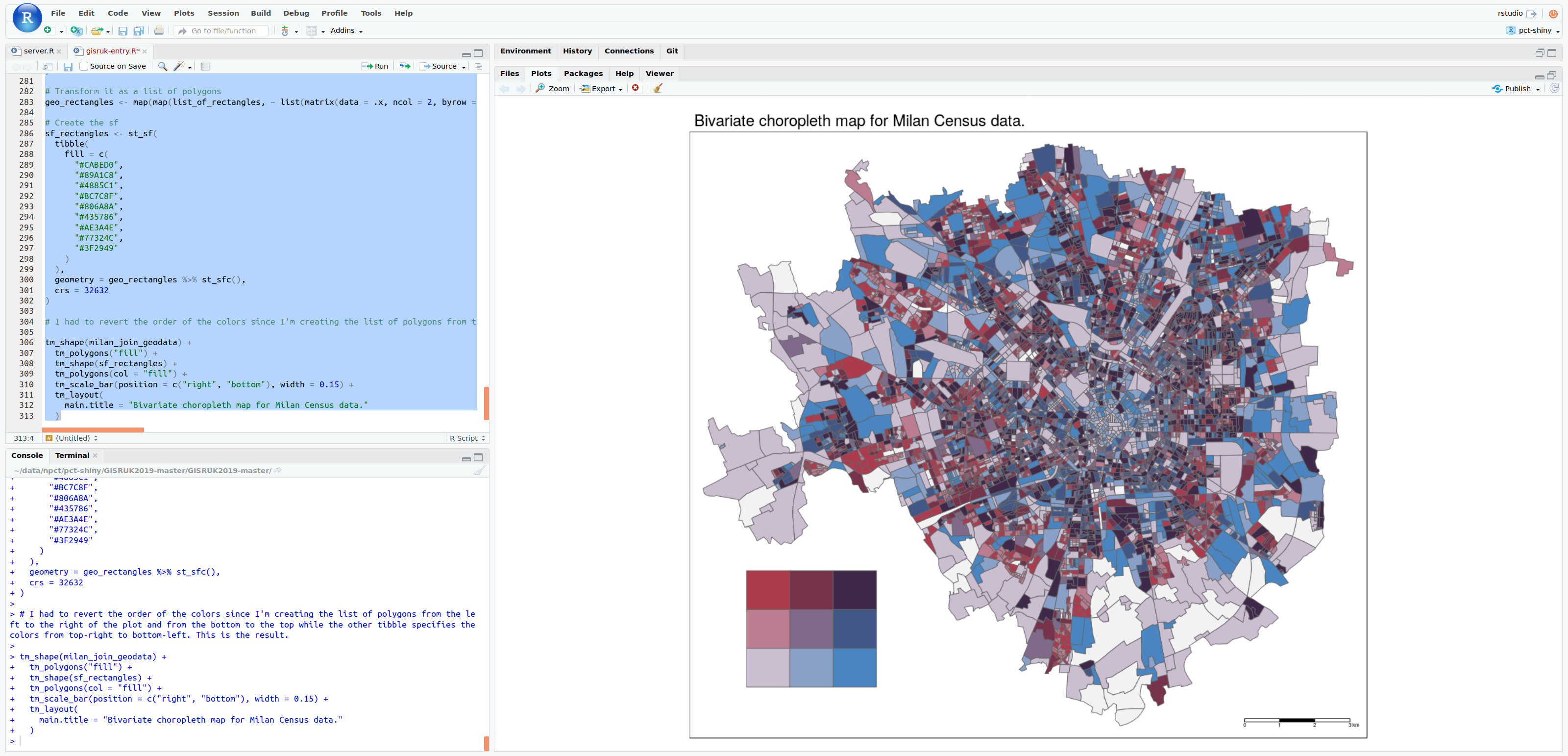


 paulopulgarin
paulopulgarin
Entries are welcome for 'best reproducible map' and 'most creative map'. This competition coincides with the GISRUK 2019 conference and at least 1 of the prizes will go to attendees of the R course we are teaching there based on the book.
Criteria for 'best map'
Criteria for 'most creative map'
Please paste your entries here, as with the previous competition #371