 loewenheim
commented
2 weeks ago
loewenheim
commented
2 weeks ago I agree with adding retries. Making failure to check not count as unhealthy sounds dicey to me, on the other hand, for the reason you mention.
Open mwarkentin opened 2 weeks ago
loewenheim
commented
2 weeks ago I agree with adding retries. Making failure to check not count as unhealthy sounds dicey to me, on the other hand, for the reason you mention.
Environment
SaaS (https://sentry.io/)
Steps to Reproduce
Over the last 30 days, we've experienced ~265 instances where backpressure has been marked as unhealthy due to a connection timeout when checking the health of a redis or rabbitmq cluster: https://cloudlogging.app.goo.gl/KNZDAduqrHWQn5At7
Each of these come with a corresponding pause and delay in ingestion: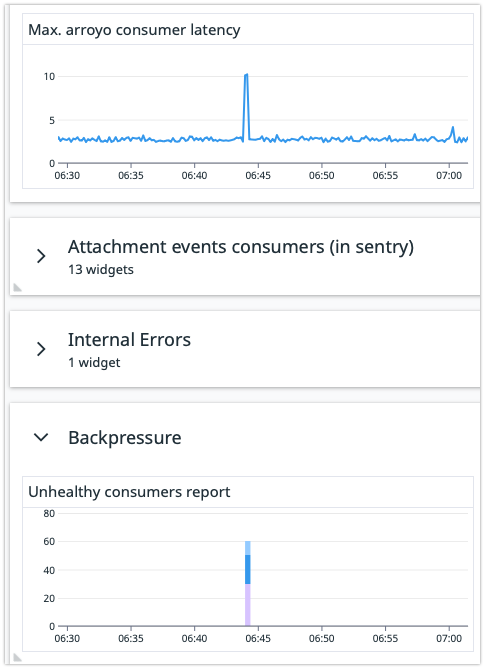
1 timeout seems to trigger about 15s of ingestion latency.
There can also be instances where multiple trigger in succession, which seems to be enough to trigger a backlog large enough that it may page SRE while it burns down the backlog:
Expected Result
Some possible improvements we can make:
I would probably start with adding retries on failure as it seems like the simplest thing that can work.
Actual Result
Backpressure pauses ingestion from a single failure.
Product Area
Ingestion and Filtering
Link
No response
DSN
No response
Version
No response