 TowerBR
commented
6 years ago
TowerBR
commented
6 years ago I think the Evernote database optimization simply changes so much of the database that there simply is not much of the old data that can be reused
I think the same, as everything is new, everything has to be sent again, there is nothing different that can be done. But I think about the impact of this on really big databases. I'm very curious about how Vertical Backup works.
The total number of chunks do not radically differ between branches (the graphs exaggerates by being relative)
I agree, in fact it is not because they are relative, but because the graph scale is small (2610-2710, a "100" range).
Any attempt to sort the files before processing can also be catastrophic, because you never know how the files are manipulated in a way that drastically affects how they are sorted.
Exact. We must think of the "cause" of the problem, and I do not think the order is the main cause. I think that would be more the "not knowing" of the "coming forward" in the file queue.
I have not yet studied the Duplicacy code like you do, so I do not know if what I'm going to say is correct and / or has already been implemented, but think of the file queue:

If file 3 has a small modification, I think what Duplicacy does today is to change the subsequent chunks until it finds an old chunk where the boundary fits, generating a new chunk 6, 7 and so on:

But if it could "see" that chunks 5 could be used, it would only generate chunk 6, to replace 4:
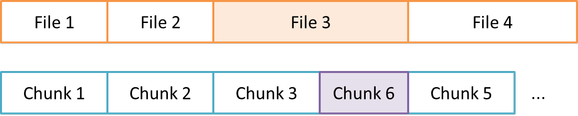
Is the current operation like this?
 fracai
fracai tophee
tophee kairisku
kairisku
 thrnz
thrnz
I think this may be related to issue #248 .
I noticed that backups of my active folders were growing in size significantly where I expected them to change very little. The best example I can give is my "Photos" folder/snapshot...
I regularly download my sd cards to a temporary named project folder under a "Backlog" subfolder. It can be days or months before I work on these images, but usually this will involve Renaming ALL the files and separating them into subfolders by Scene/Location or Purpose (print, portfolio, etc...). The project folder gets renamed too and the whole thing is then moved from out of "Backlog" to "Catalogued". None of the content of any of the files have physically changed during all this, file hashes should be the same.
The renaming and moving alone appears to be enough to make the backup double in size. Any image edits in theory shouldn't have an impact as typically the original file is untouched... The good thing about modern photo processing is edits are non destructive to the original image file. Instead and XML sidecar file is saved along side the image file with meta about the edits applied.
I'm yet to test the impact of making image edits but I suspect it may make things worse because each file gets another file added after it, and it seemed like file order made a difference to how the rolling hash was calculated.
Becomes...
This should be perfect for an incremental backup system, but it seems like duplicacy struggles under these circumstances. I figured the
-hashoption might help, but it didn't seem to.Am I doing something wrong or missing an option?
Is this a bug, or just a design decision?
Is there any possible way to improve this?
Although the above example may sound unique I find this happens in almost all my everyday folders. Design projects, website coding projects, Files and Folders are just often reorganized.
I'm guessing the only way to reclaim this space would be to prune the older snapshots where the files were named differently?