 gitanat
commented
5 years ago
gitanat
commented
5 years ago I'm not sure where the "q" are coming from, but in terms of the order of segments you might have to tune the parameters in SegmentOrderer ({"max_line_height": 20, "max_line_width": 10000})
Can you please attach the code you're using for the OCR and grounding and the commit you're at?
 Jambon1510
Jambon1510











 Result:
OCRed text:
3051792684
Result:
OCRed text:
3051792684
current behavior Some of image which needs to be detected have zone detection appearing in different orders than what we see (from left to right and top to bottom) Let's take this example below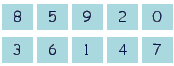
The number 3 will arrive in the results before 7 whereas it should appear before 6
When I try the grounding on this particular picture we can indeed see that 3 detection comes in the same order as the result above
expected behavior Have the below result