 metemaddar
commented
1 year ago
metemaddar
commented
1 year ago An initial solution process for this data flow would be like:
- backup the Edge table data that has link to WayModified to a new table (EdgeBackup)
- Duplicate the way_modified.edge_id ---> way_modified.backup_edge_id
- Wipe edge table
- Insert new edges to edge table
- search to match way_modified.edge_id to the new inserted ones.
In this scenario we should not reset the sequence counter of Edge table. Because in several data movement, the IDs will change and we may have duplicated BackupEdge.
Then if we could link the way_modified to the new inserted edge we have 3 connected objects:
graph TD;
WayModified-->Edge;
WayModified-->BackupEdge;We can compare the BackupEdge and Edge and show the user what have been changed so that they can accept the change or do needed modifications to the WayModified.
 EPajares
EPajares
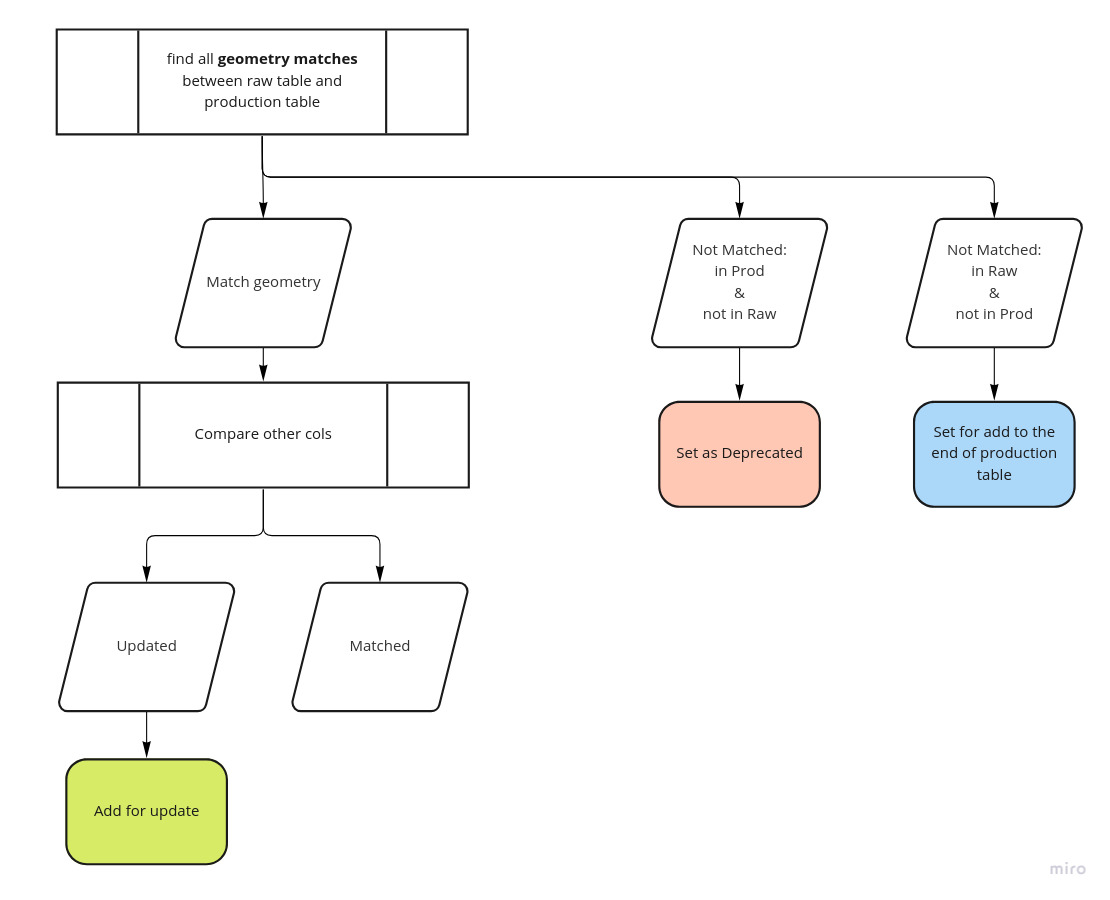
We first collect the data (called raw data) and we need to transfer it to the production database. While transferring we have some issues that we need to handle:
Example situation (Edge table)
To find a solution for this issue, we can work on a sample data flow for Edge data. The user produces WayModified objects that are connected to Edges.
Issues
Summary
In this issue we find a data flow to create concrete task for updating data from RawData to Production. So that we can: