 mafiesto4
commented
5 years ago
mafiesto4
commented
5 years ago Who needs performance? :trollface:
Closed vblanco20-1 closed 5 years ago
mafiesto4
commented
5 years ago Who needs performance? :trollface:
 ghost
commented
5 years ago
ghost
commented
5 years ago Curious to see what you measure.
 Ranoller
commented
5 years ago
Ranoller
commented
5 years ago So this can explain why a simple Light2D node in Godot can burn your computer?
 CptPotato
commented
5 years ago
CptPotato
commented
5 years ago @Ranoller I don't think so. The bad lighting performance is most likely related to how Godot performs 2D lighting at the moment: Rendering every sprite n-times (with n being the number of lights that are affecting it).
Edit: see #23593
 vblanco20-1
commented
5 years ago
vblanco20-1
commented
5 years ago To clarify, this is about CPU side inefficiencies all over the code. This has nothing to do with godot features or godot GPU rendering itself.
 pgruenbacher
commented
5 years ago
pgruenbacher
commented
5 years ago @vblanco20-1 on a bit of a side-tangent, you and I had talked about the nodes being modeled as ECS entities instead. I wonder if the trick is to do a feature branch of godot with a new ent module that would gradually work side-by-side with the tree. like a get_tree() and get_registry(). the ent module would probably miss like 80% of the functionality of the tree/scene, but it could be useful for as a testbed, especially for stuff like composing large static levels with lots of objects (culling, streaming, batch rendering). Reduced functionality and flexibility but greater perfromance.
vblanco20-1
commented
5 years ago Before going full ECS (wich i might do) i want to work on some low hanging fruits as a experiment. I might try to go full data-oriented later down the line.
vblanco20-1
commented
5 years ago So, first updates:
update_dirty_instances : from 0.2-0.25 miliseconds to 0.1 milisecond octree_cull (the main view): from 0.35 miliseconds to 0.1 milisecond
The fun part? the replacement for octree cull is not using any acceleration structure, it just iterates over a dumb array with all the AABBs.
The even funnier part? The new culling is 10 lines of code. If i wanted to have it parallel, it would be a single change to the line.
Ill continue with implementing my new culling with the lights, to see how much the speedup accumulates.
pgruenbacher
commented
5 years ago we should probably get a google benchmark directory going too on the master branch. That may help with validating so people don't have to argue about it.
 bojidar-bg
commented
5 years ago
bojidar-bg
commented
5 years ago There is the godotengine/godot-tests repository, but not many people are using it yet.
vblanco20-1
commented
5 years ago New update:

Ive implemented a fairly dumb spatial acceleration structure, with 2 levels. Im just generating it every frame Further improvement could make it better and update it dynamically instead of remaking it.
In the image, the different rows are different scopes, and each of the colored block is a task/chunk of code. In that capture, im doing both the octree cull and my cull side by side to have a direct comparaison
It demonstrates that recreating the entire acceleration structure is faster than a single old octree cull. Also that further culls tend to be about half to one third of the current octree.
I havent found a single case where my dumb structure is slower than the current octree, other that the cost of the initial creation.
Another bonus is that its very multithread friendly, and can be scaled to whatever core count you want just with a parallel for.
It also checks the memory completely contigously, so it should be possible to make it do SIMD without much hassle.
Another important detail is that its vastly simpler than the current octree, with way less lines of code.
Ranoller
commented
5 years ago You are causing more hype that the end of game of thrones....
vblanco20-1
commented
5 years ago 
Modified the algos a bit so now they can use C++17 parallel algorythms, wich allows the programmer to just tell it to do a parallel for, or a parallel sort. Speedup of about x2 in the main frustrum cull, but for the lights is about same speed as before.
My culler is now 10 times faster than godot octree for the main view.
vblanco20-1
commented
5 years ago If you want to look at the changes, the main important thing is here: https://github.com/vblanco20-1/godot/blob/4ab733200faa20e0dadc9306e7cc93230ebc120a/servers/visual/visual_server_scene.cpp#L387 This is the new culling function. The acceleration structure is on the function right above it.
Ranoller
commented
5 years ago This should compile with VS2015? Console throws a bunch of errors about the files inside entt\
pgruenbacher
commented
5 years ago @Ranoller it's c++17 so make sure you're using newer compiler
 Zireael07
commented
5 years ago
Zireael07
commented
5 years ago Uh, I think Godot did not make the move to c++17 yet? At least I recall some discussions on the topic?
Ranoller
commented
5 years ago Godot is C++ 03. This move will be controversial. I recomend @vblanco20-1 to talk with Juan when he finish hollydays... this optimization will be great and we don't want an instantly "This Will Never Happend TM
 nem0
commented
5 years ago
nem0
commented
5 years ago @vblanco20-1
octree_cull (the main view): from 0.35 miliseconds to 0.1 milisecond
how many objects?
vblanco20-1
commented
5 years ago @nem0
@vblanco20-1
octree_cull (the main view): from 0.35 miliseconds to 0.1 milisecond
how many objects?
Around 2200. The godot octree performs better if the check is very small, because it early outs. The bigger the query, the slower godot octree is compared to my solution. If the godot octree cant early-out 90% of the scene, then its dreadfully slow, because its essentially iterating linked lists for every single object, while my system is structure of arrays where each cache line holds a good amount of AABBs, greatly reducing cache misses.
My system works by having 2 levels of AABBs, its an array of blocks, where every block can hold 128 instances.
The top level is mostly an array of AABBs + an array of Blocks. If the AABB check passes, then i iterate the block. The block is array of structure of AABBs, Mask, and a pointer to the instance. This way everything is faaaaast.
Right now, the generation of the top level data structure is done in a very dumb way. If it was better generated, its performance could be a lot bigger. Im performing some experiments with different block sizes other than 128.
vblanco20-1
commented
5 years ago Ive checked different numbers, and 128 per block seems to still be the sweetspot somehow.
By changing the algorythm to separate "big" objects from small objects, ive managed to get another 30% speed upgrade, mostly in the case where you are not looking into the center of the map. It works becouse that way the big objects dont bloat the block AABBs that also include small objects. I believe that 3 sizes would probably work the best.
Block generation is still not optimal at all. The big blocks only cull about 10 to 20% of the instances when looking at the center, and up to 50% when looking outside the map, so its performing a LOT of extra AABB checks than what it should need.
I think an improvement would probably be to reuse the current octree but "flatten" it.
There is now not a single case where my algorithm is equal or worse than the current octree, even without parallel execution.
 Faless
commented
5 years ago
Faless
commented
5 years ago @vblanco20-1 I assume you are doing your comparison with godot compiled in release mode (which uses -O3) and not the regular editor build in debug (which has no optimizations and is default) right?
Sorry if it's a silly question but I see no mention of that in the thread.
Nice work anyway :)
vblanco20-1
commented
5 years ago @Faless Its release_debug, wich does add some optimizations. I havent been able to test full "release" as i cant get it to open the game (game needs to be built too?)
Ive had an idea on how to improve the culling a lot more, removing the need to regenerate every frame, and creating better spatial optimization. Ill see what i can try. In theory such a thing could remove the regenerate, improve the perf of the main cull a bit, and have a specific mode for pointlights which would increase their cull performance by a huge amount, so much that they would have nearly 0 cost, because it will turn into a cheap O(1) to get the "objects in a radius".
Its inspired by how one of my experiments worked, where im doing 400.000 physics objects bouncing from each other.
vblanco20-1
commented
5 years ago 
New culling is implemented now. The block generation is now far smarter, resuling in a faster cull. The special case for lights is not implemented yet. Ive commited it to my fork
 LikeLakers2
commented
5 years ago
LikeLakers2
commented
5 years ago I am curious if you can run that benchmark tool (the one from your screenshots) on a build from the current master branch, to give us a reference point for how much performance your implementation is giving over the current implementation. I'm a dummy, woops.
 neikeq
commented
5 years ago
neikeq
commented
5 years ago @LikeLakers2 You can see both the current implementation and his implementation in the screenshot.
pgruenbacher
commented
5 years ago He ran this on a master fork
On Wednesday, December 12, 2018, MichiRecRoom notifications@github.com wrote:
@neikeq https://github.com/neikeq Explain? I thought the screenshots that have been posted were only of his implementation, given how the posts with screenshots have been worded thus far.
— You are receiving this because you commented. Reply to this email directly, view it on GitHub https://github.com/godotengine/godot/issues/23998#issuecomment-446831151, or mute the thread https://github.com/notifications/unsubscribe-auth/ADLZ9pRh9Lksse9KBfWV0z5GmHRXf5P2ks5u4crCgaJpZM4YziJp .
CptPotato
commented
5 years ago Are there any news on this topic?
vblanco20-1
commented
5 years ago Are there any news on this topic?
I talked with reduz. Is never going to get merged couse it doesnt fit the project. I went to do other experiments instead. Maybe i upgrade the culling later for 4.0
CptPotato
commented
5 years ago That's a shame, considering it looked really promising. Hopefully these issues will be worked on in time.
 aaronfranke
commented
5 years ago
aaronfranke
commented
5 years ago Perhaps this should be given the 4.0 milestone? Since Reduz is planning to work on Vulkan for 4.0, and this topic, while about performance, is focused on rendering, or at least OP is.
 Two-Tone
commented
5 years ago
Two-Tone
commented
5 years ago @vblanco20-1 Did he say how it doesn't fit? I'm assuming because of the move to c++17?
 starry-abyss
commented
5 years ago
starry-abyss
commented
5 years ago There is an other related issue on the milestone though: #25013
vblanco20-1
commented
5 years ago You might be interested. Ive been working on the fancy fork for quite a while. The current results are like this:
Captured on a big gaming laptop with an 4 core intel cpu and GTX 1070
Normal godot

My fork at https://github.com/vblanco20-1/godot/tree/ECS_Refactor
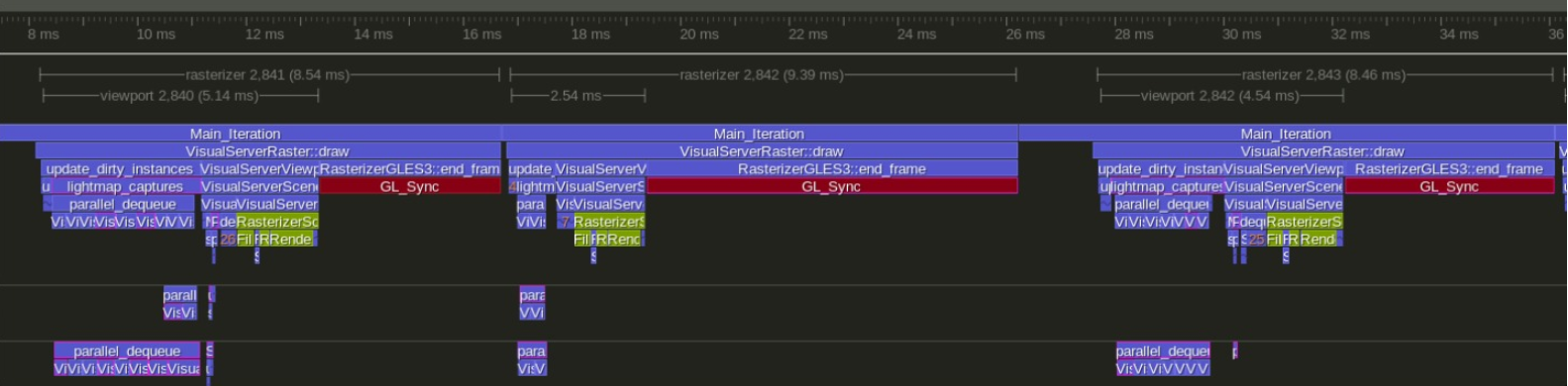
In both profiles, the Red is essentially "wait for GPU". Currently bottlenecked due to too many drawcalls on opengl. Cant really be solved without vulkan or rewriting the entire renderer.
On the CPU side, we go from 13 ms frames to 5 ms frames. "Fast" frames go from 5.5 ms to 2.5ms On the "total frame" side, we go from 13 ms to 8-9 ms ~75 FPS to ~115 FPS
Less CPU time = more time you can spend on gameplay. The current godot is bottlenecked on the CPU, so more time spent into gameplay will mean lower FPS, while my fork is GPU bound, so you can add a lot of more gameplay logic with the FPS untouched as the CPU is just "free" for quite a while every frame.
A LOT of these improvements are mergeable into godot, IF godot supported modern C++ and had a multithreading system that allow very cheap "small" tasks. The biggest gain is done by doing multithreaded shadows and multithreaded lightmap read on dynamic objects #25013. Both of those work in the same way. A lot of other parts of the renderer are multithreaded too. Other gains are a Octree that is from 10 to 20 times faster than godot one, and improvements on some of the flow of rendering, such as recording both depth-prepass and normal-pass render list at once, instead of iterating the cull list 2 times, and a significant change to how light->mesh connecction works (no linked list!)
Im currently looking for more test maps other than the TPS demo so i can have more metrics in other types of maps. Im also going to write a series of articles explaining how all of this works in detail.
 and3rson
commented
5 years ago
and3rson
commented
5 years ago @vblanco20-1 this is totally awesome. Thanks for sharing!
I also agree that even though Vulkan is cool, having a decent GLES3 performance would be an absolute win for Godot. Full Vulkan support will likely not land anytime soon while patching GLES3 is something that guys here proved to be fully doable right now.
My huge +1 for bringing more and more attention to this. I'd be the happiest person on Earth if Reduz agreed to allow community to improve GLES3. We're doing a very serious 3D project in Godot for 1.5 years now, and we are very supportive towards Godot (including donations), but the lack of solid 60 FPS really demotivates us and puts all our efforts under a huge risk.
It's really a shame this is not getting enough credits. If we won't have 60 FPS within the coming months with our current (pretty simple in terms of 3D) project, we will fail to deliver a playable game and thus all the effort will be wasted. :/
@vblanco20-1 honestly, I'm even considering using your fork as a base of our game in production.
P. S. Some thoughts: as a last resort, I think it would totally be possible to even have, say, 2 GLES3 rasterizers - GLES3 & GLES3-community.
 Calinou
commented
5 years ago
Calinou
commented
5 years ago P. S. Some thoughts: as a last resort, I think it would totally be possible to even have, say, 2 GLES3 rasterizers - GLES3 & GLES3-community.
That doesn't make sense to me; it's probably a better idea to get fixes and performance improvements directly into the GLES3 and GLES2 renderers (as long as they don't break rendering in major ways in existing projects).
Other gains are a Octree that is from 10 to 20 times faster than godot one, and improvements on some of the flow of rendering, such as recording both depth-prepass and normal-pass render list at once, instead of iterating the cull list 2 times, and a significant change to how light->mesh connecction works (no linked list!)
@vblanco20-1 Would it be possible to optimize the depth prepass while staying on C++03?
vblanco20-1
commented
5 years ago @Calinou the depth prepass stuff is one of the things that do not need anything and is very easily mergeable. Its main downside is that it will require the renderer to use extra memory. As it will now need 2 RenderList instead of only one. Other than the extra memory, there is pretty much no downside. The cost of building the renderlist for 1 pass or 2 is almost the same thanks to cpu caching, so it pretty much completely removes the cost of prepass fill_list()
vblanco20-1
commented
5 years ago @vblanco20-1 honestly, I'm even considering using your fork as a base of our game in production.
@and3rson please dont. This fork is purely a research project, and its not even fully stable. In fact it wont even compile outside of some very specific compilers due to the usage of parallel STL. The fork is mostly a testbed of random optimization ideas and practises.
 jknightdoeswork
commented
5 years ago
jknightdoeswork
commented
5 years ago What tools you using to profile Godot? Did you need to add Profiler.Begin and Profiler.End flags to the godot source to generate these samples?
vblanco20-1
commented
5 years ago What tools you using to profile Godot? Did you need to add Profiler.Begin and Profiler.End flags to the godot source to generate these samples?
Its using Tracy profiler, it has different types of scope profile mark, which i use here. For example ZoneScopedNC("Fill List", 0x123abc) adds a profile mark with that name and the hex color you want.
 HeadClot
commented
5 years ago
HeadClot
commented
5 years ago @vblanco20-1 - Will we be seeing some of these performance improvements brought over to the godot main branch?
vblanco20-1
commented
5 years ago @vblanco20-1 - Will we be seeing some of these performance improvements brought over to the godot main branch?
Maybe when C++11 is supported. But reduz doesnt really want more work on the renderer before vulkan happens, so might be never. Some of the findings from the optimziation work could be useful for the 4.0 renderer.
 swarnimarun
commented
5 years ago
swarnimarun
commented
5 years ago @vblanco20-1 mind sharing the compiler and environment details for the branch, I think I can figure most of it out but just don't to waste time figuring out issues if I don't have to.
Also can't we add the AABB change to Godot main without much cost?
vblanco20-1
commented
5 years ago @vblanco20-1 mind sharing the compiler and environment details for the branch, I think I can figure most of it out but just don't to waste time figuring out issues if I don't have to.
Also can't we add the AABB change to Godot main without much cost?
@swarnimarun Visual Studio 17 or 19, one of the later updates, works fine. (windows) The scons script got modified to add the cpp17 flag. Also, launching editor is broken right now. Im working on see if i can restore it.
Sadly the AABB change is one of the biggest things. Godot octree is intertwined with a LOT of things in the visual server. It not only keeps track of objects for culling, but it also connects objects to lights/reflection probes, with its own system for pairing them. Those pairs also depend on the linked list structure of the octree, so its almost impossible to adapt the current octree to be faster without changing quite a lot of the visual server. In fact i still havent been able to get rid of the normal godot octree in my fork for a couple objects types.
 mixedCase
commented
5 years ago
mixedCase
commented
5 years ago @vblanco20-1 Do you have a Patreon? I would put down some money towards a fork focused on performance and that doesn't restrict itself to ancient C++ and I'm probably not the only one. I would like to toy around with Godot for 3D projects but I'm losing hope it will become viable without a huge proof a concept that proves your approach to performance and usability to the core team.
aaronfranke
commented
5 years ago @mixedCase I would be extremely hesitant to support any kind of fork of Godot. Forking and fragmentation is often the death of open source projects.
The better scenario, and more likely now that it has been demonstrated that newer C++ allows for significant optimizations, is for Godot to officially upgrade to a newer version of C++. I would expect this to happen in Godot 4.0, to minimize the risk of breakages in 3.2, and in time for the new C++ features to be utilized with Vulkan being added to Godot 4.0. I also don't expect any significant changes to be made to the GLES 3 renderer, as reduz wants to delete it.
(But I don't speak for the Godot devs, this is just my speculation)
mixedCase
commented
5 years ago @aaronfranke I agree, I think that a permanent fork would not be ideal. But from what I've gathered from what he's said (please correct me if I'm wrong) is that @reduz believes these newer features should not be used because they do not bring anything significant enough to be worth learning the concepts and because he perceives some of them as making the code "unreadable" (at least for developers used to the "augmented C" that C++ was almost 10 years ago).
I believe Juan to be a very pragmatic person, so it would probably take a big proof of concept that demonstrates the benefits of using modern abstractions and more efficient data structures to convince him that the engineering trade offs are probably worth it. @vblanco20-1 has done amazing work so far so I personally would not hesitate to put down some money every month towards him if he would like to go for something like that.
 plabuda
commented
5 years ago
plabuda
commented
5 years ago I am perpetually amazed how Godot devs act like they are allergic to good ideas, performance, and progress. It's a shame this was not pulled in.
vblanco20-1
commented
5 years ago This is a piece from a series of articles im working on about the optimizations, precisely about the data structure usage.
Godot bans the STL containers, and its C++03. This means it does not have move operators in its containers, and its containers tend to be worse than the STL containers themselves. Here i have an overview of the godot data structures, and the problems with them.
Preallocated C++ array. Very common around the entire engine. Its sizes tend to be set by some configuration option. This is very common in the renderer, and a proper dynamic array class would work great here. Example of misuse: https://github.com/godotengine/godot/blob/master/servers/visual/visual_server_scene.h#L442 This arrays are wasting memory for no good reason, using a dynamic array would be a significantly better option here as it would make them only the size they need to be, instead of the maximum size by a compile constant. Each of the Instance* arrays using MAX_INSTANCE_CULL are using half a megabyte of memory
Vector ( vector.h) a std::vector dynamic array equivalent, but with a deep flaw. The vector is atomically refcounted with a copy-on-write implementation. When you do
Vector a = build_vector(); Vector b = a;
the refcount will go to 2. B and A now point to the same location in memory, and will copy the array once an edit is made to it. If you now modify vector A or B, it will trigger a vector copy.
Every time you write into a vector it will need to check the atomic refcount, slowing down every single write operation in the vector. It is estimated godot Vector is 5 times slower than std::vector, at minimum. Another issue is that vector will relocate automatically when you remove items from it, causing terrible uncontrollable performance issues.
PoolVector (pool_vector.h). More or less the same as a vector, but as a pool instead. It has the same pitfalls as Vector, with copy on write for no reason and automatic downsizing.
List ( list.h) a std::list equivalent. The list has 2 pointers (first and last) + a element count variable. Every node in the list is double linked, plus an extra pointer to the list container itself. The memory overhead for every node of the list is 24 bytes. It is horribly overused in godot due to Vector being not very good in general. Horribly misused over the entire engine.
Examples of big misuse: https://github.com/godotengine/godot/blob/master/servers/visual/visual_server_scene.h#L129 No reason whatsoever for this to be a list, should be a vector https://github.com/godotengine/godot/blob/master/servers/visual/visual_server_scene.h#L242 Every single of this cases is wrong. again, it should be vector or similar. This one can actually cause performance issues. The biggest mistake is using List in the octree used for culling. Ive already gone into detail about the godot octree in this thread.
SelfList(self_list.h) a intrusive list, similar to boost::intrusive_list. This one allways stores 32 bytes of overhead per node as it also points to self. Horribly misused over the entire engine. Examples: https://github.com/godotengine/godot/blob/master/servers/visual/visual_server_scene.h#L159 This one is specially bad. One of the worst in the entire engine. This is adding 8 pointers of fatness to every single renderable object in the engine for no reason whatsoever. There is no need for this to be a list. It, again, can be a slotmap or a vector, and that's what i’ve replaced it with.
Map(map.h) a red-black tree. Misused as a hashmap in pretty much all of its uses. Should be deleted from the engine in favor of OAHashmap or Hashmap, depending on usage. Every use of Map i saw was wrong. I cant find an example of a Map being used where it makes sense.
Hashmap ( hash_map.h) roughly equivalent to std::unordered_map, a closed adressing hashmap based on linked list buckets. It can rehash when removing elements.
OAHashMap( oa_hash_map.h) newly written fast open-adressing hashmap. uses robinhood hashing. Unlike hashmap, it will not resize when removing elements. Really well implemented structure, better than std::unordered_map.
CommandQueueMT(command_queue_mt.h) the command queue used for to communicate to the different Servers, such as the visual server. It works by having a hardcoded 250 kb array to act as allocator pool, and allocates every command as an object with a virtual call() and post() function. It uses mutexes to protect the push/pop operations. Locking mutexes is very expensive, i recommend using the moodycamel queue instead, which should be an order of magnitude faster. This is likely to become a bottleneck for games that perform a lot of operations with the visual server, like lots of moving objects.
These are pretty much the core set of data structures in godot. There is no proper std::vector equivalent. If you want the “dynamic array” data structure, you are stuck with Vector, and its drawbacks with the copy on write and downsizing. I think a DynamicArray data structure is the thing godot needs the most right now.
For my fork i use STL and other containers from external libraries. I avoid godot containers as they are worse than the STL for performance, with the exception of the 2 hashmaps.
Problems ive found on the vulkan implementation in 4.0. I know its work in progress, so there is still time to fix it.
Usage of Map in the render API. https://github.com/godotengine/godot/blob/vulkan/drivers/vulkan/rendering_device_vulkan.h#L350 As i commented, there is no good use of Map and no reason for it to exist. Should just be hashmap in those cases. Linked list overuse instead of just arrays or similar. https://github.com/godotengine/godot/blob/vulkan/drivers/vulkan/rendering_device_vulkan.h#L680 Luckily this is likely not on the fast loops, but its still an example of using List where it shouldnt be used
Using PoolVector and Vector in the render API. https://github.com/godotengine/godot/blob/vulkan/drivers/vulkan/rendering_device_vulkan.h#L747 There is no real good reason to use those 2 flawed structures as part of the render API abstraction. By using them, users are forced to use those 2, with their drawbacks, instead of being able to use any other data structure. A recommendation is to use pointer + size on those cases, and still have a version of the function that takes a Vector if neccesary.
An actual example where this API will harm an user is on the vertex buffer create functions. In the GLTF format, the vertex buffers will come packed in a binary file. With this API, the user will have to load the GLTF binary buffer into memory, create this structures copying the data for each buffer, and then use the API. If the API took pointer + size, or a Span<> struct, the user would be able to directly load the vertex data from the loaded binary buffer into the API, without having to perform a conversion.
This is specially important for people who deal with procedural vertex data, like a voxel engine. With this API, the developer is forced to use Vector for his vertex data, incurring a significant performance cost, or have to copy the data into a Vector, instead of just loading the vertex data directly from the internal structures that the developer uses.
If you are interested on knowing more about this topic, the best talk i know is this one from CppCon. https://www.youtube.com/watch?v=fHNmRkzxHWs Other great talks is this one: https://www.youtube.com/watch?v=-8UZhDjgeZU , where it explains a few data structures such as the slotmap that would be super useful for godot needs.
Ranoller
commented
5 years ago Godot have a great problem of performance... you would be a good adition to godot team, please considerate that!
MODERATOR NOTE: This issue is over five years old and discusses a reality that no longer matches the status quo of the codebase. For more information, scroll to this comment.
--
I was reviewing the code of godot, and i`ve found complete disregard for any kind of cpu side performance, down to the core data structures. Its using List everywhere, when a linked list is the slowest data structure you can use on modern PCs. Almost any other data structure would be faster, specially on small sized structures. Its specially egregious on things like the light list or reflection captures in renderables, where you are storing 3 pointers every time, instead of just giving it a stack array of 8 max lights (for example) + an extra for the cases where it would be more than that.
Same thing with RID_Owner being a tree where it could be a hash map, or a slotmap. Also the Octree implementation for culling has the exact same issue.
I want to ask about the design intention behind that total and absolute overuse of linked lists and dreadful performance pointer heavy data structures everywhere in the code. Is that for a specific reason? In most of the cases a "chunked" linked list, where you do a linked list of arrays would automatically bring performance gains on the same code.
The use of these data structures also prevents any kind of "easy" parallelism in a good chunk of the code and completely trashes the cache.
I am working on making a proof of concept implementation of refactoring some of the internals to use better data structures. At this moment i am working on a rewrite of the culling code which bypasses the current octree and just uses a flat array with optional parallelism. Ill use the tps-demo as benchmark and come back with results, which in fact i have benchmarked to go 25 levels deep on that octree...
On another more happy note, i am very impressed with the code style quality, everything is easy to follow and understand, and quite well commented.