 mm4tt
commented
5 years ago
mm4tt
commented
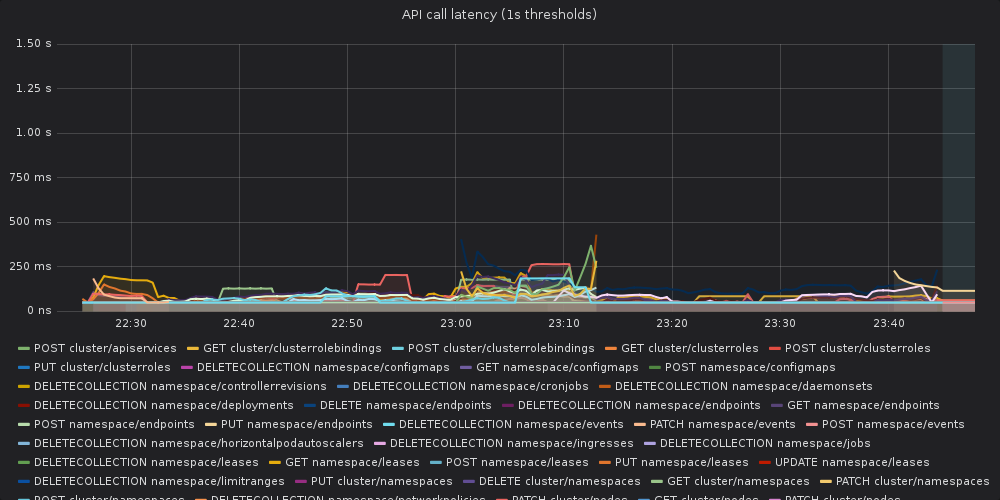
5 years ago As asked by @mknyszek, we re-run the tests from golang head with patched https://go-review.googlesource.com/c/go/+/183857 Unfortunately, it didn't help much, the api-call latency was still visibly higher than in the baseline.

 ianlancetaylor
ianlancetaylor mknyszek
mknyszek








 gopherbot
gopherbot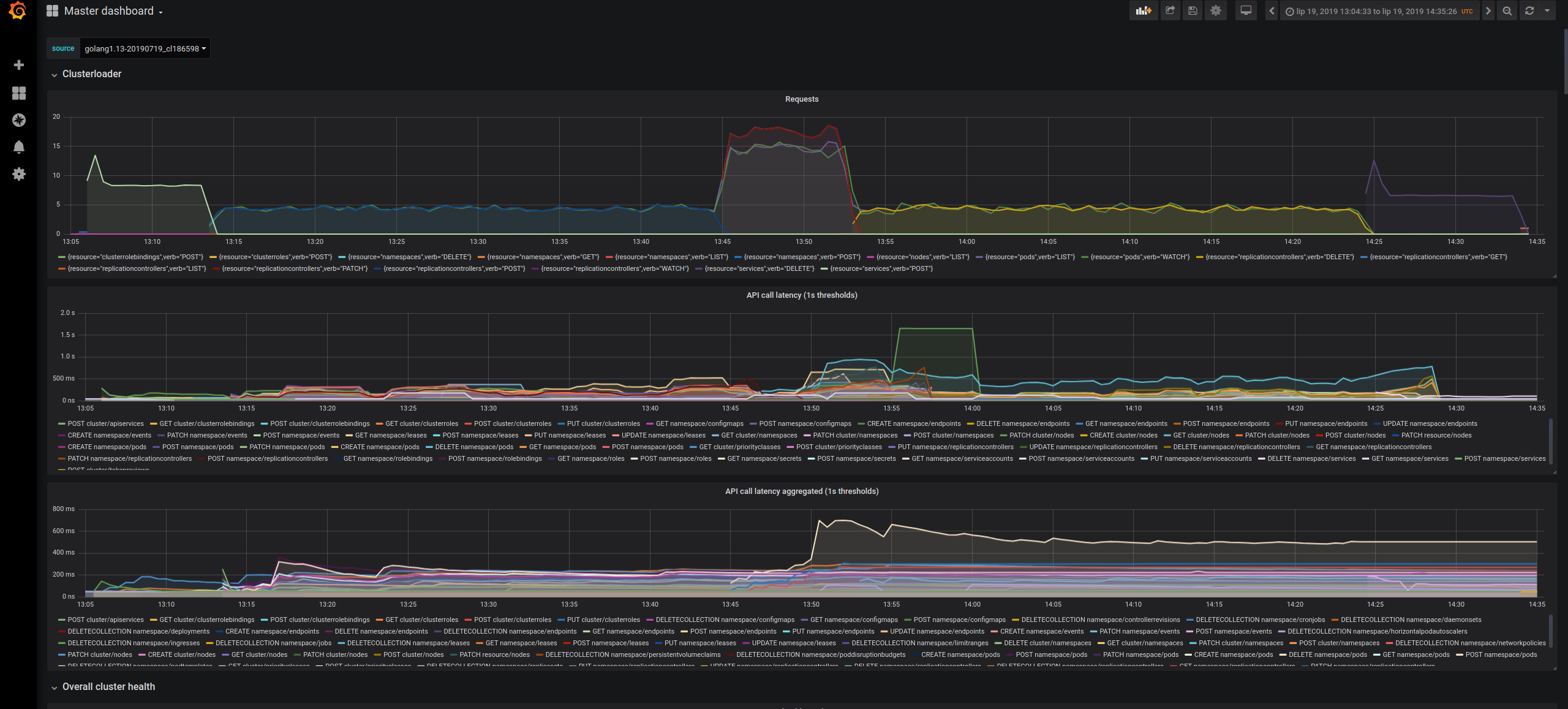






 aclements
aclements oxddr
oxddr
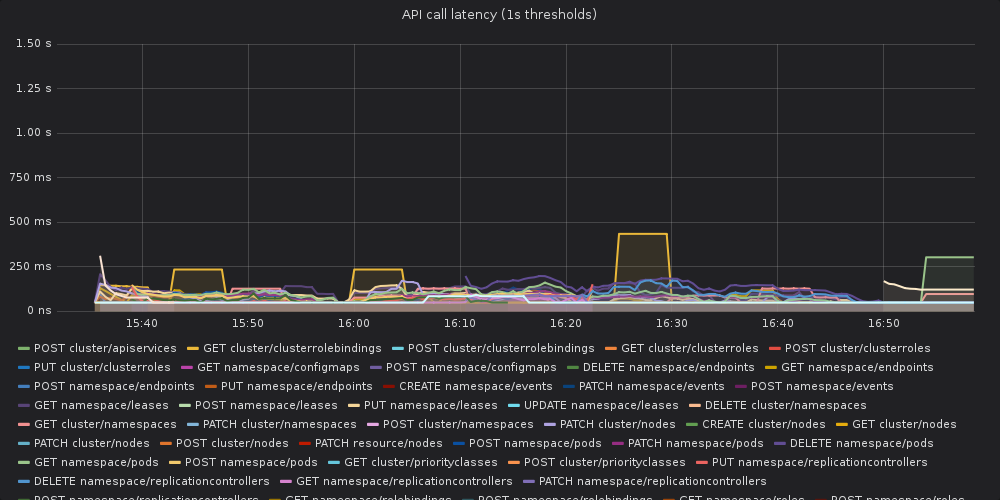




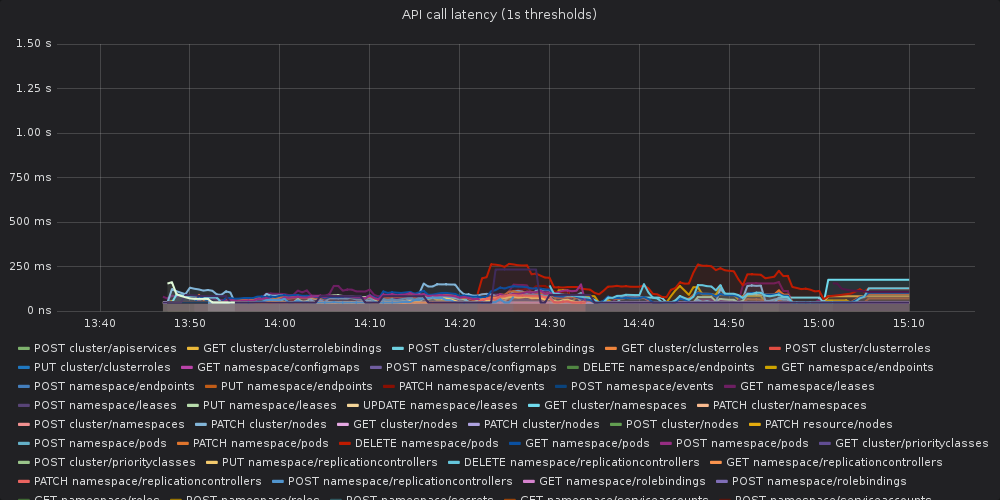
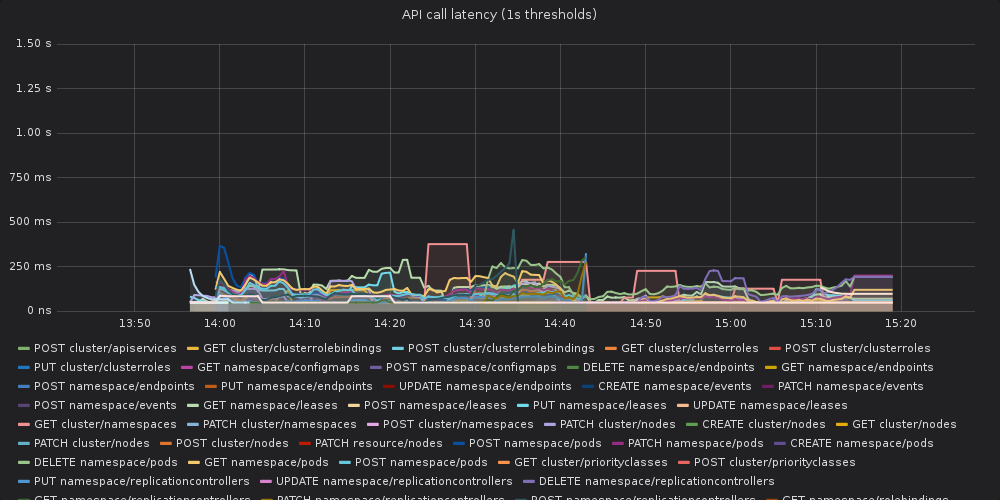
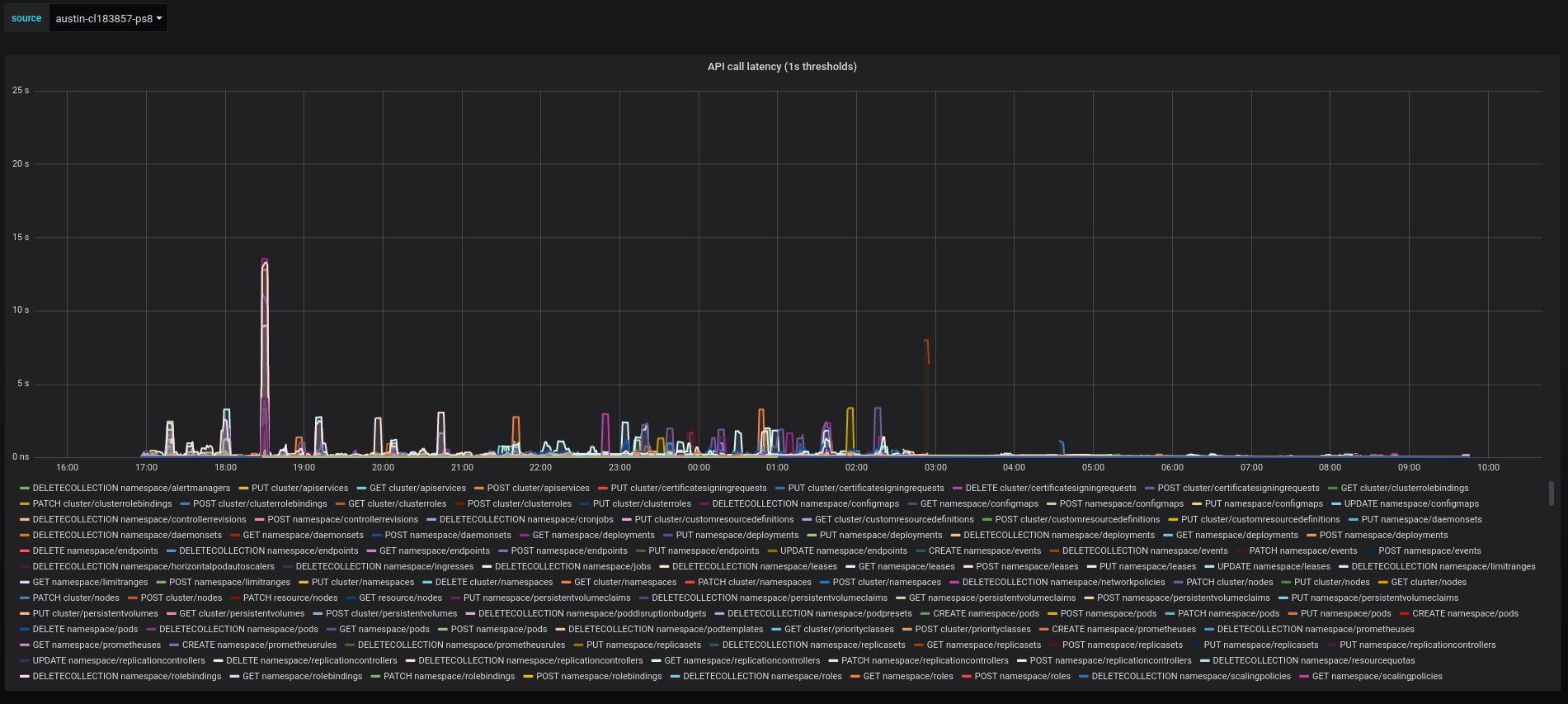
Together with golang team, we, kubernetes sig-scalability, are testing not-yet-released golang1.13 against kubernetes scale tests.
What version of Go are you using (
go version)?Does this issue reproduce with the latest release?
Yes, it reproduces with golang head.
What did you do?
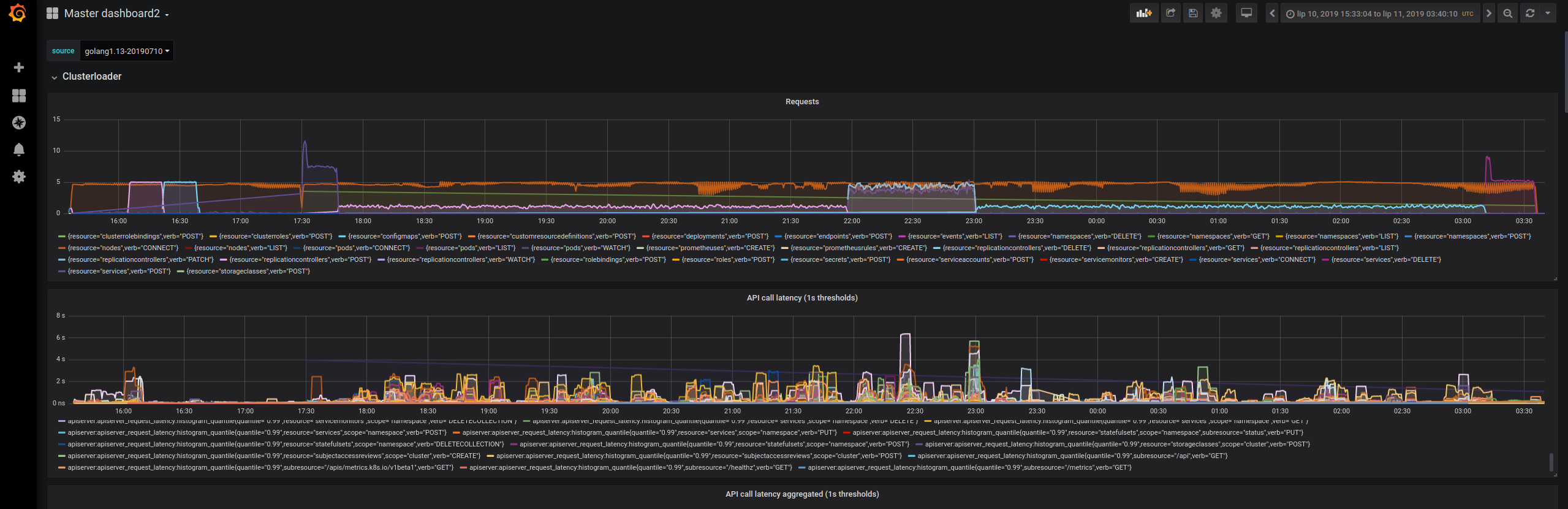
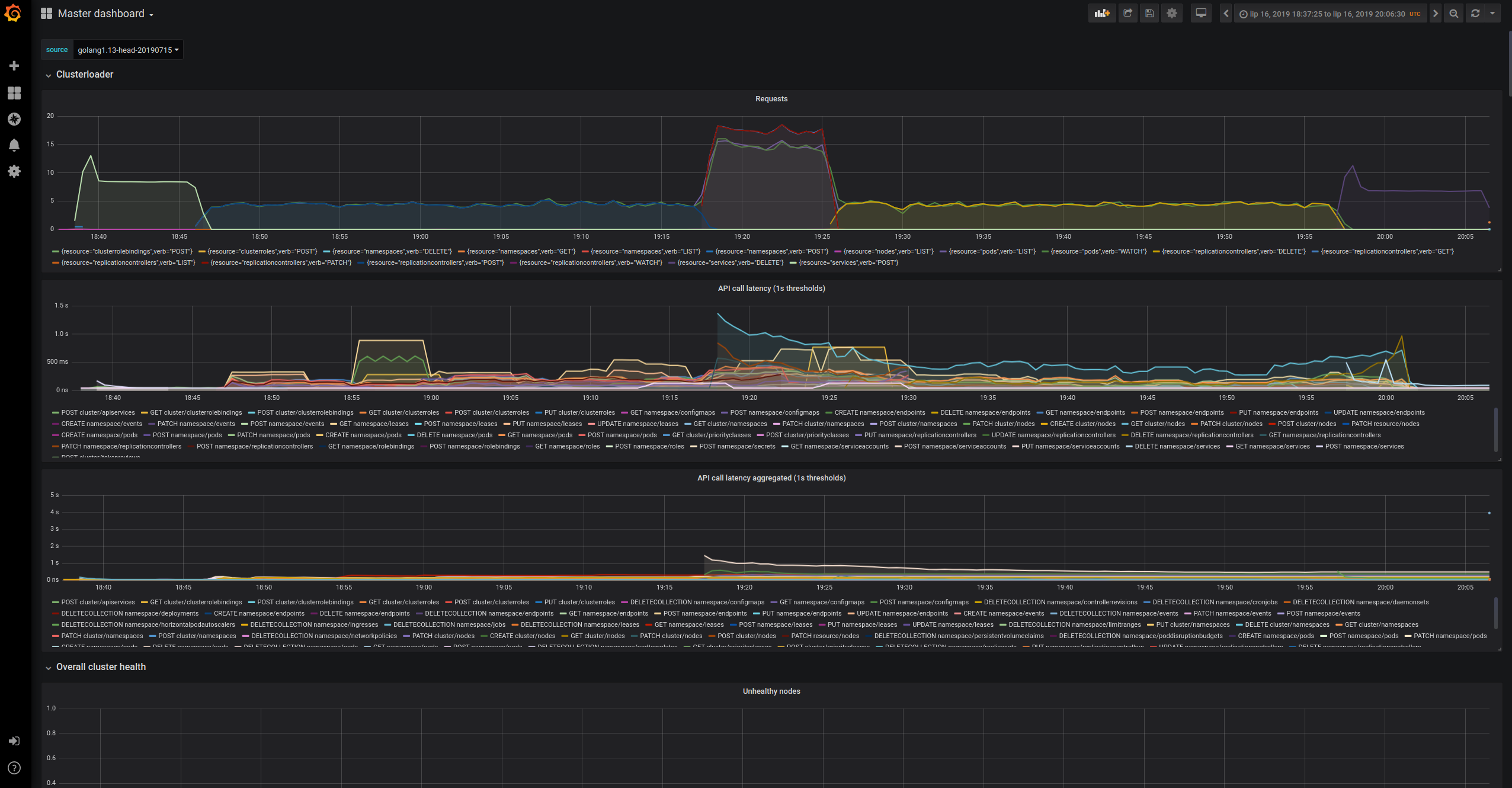
We've run k8s scale tests with kubernetes compiled with go1.13. There is a visible increase in 99th percentile of api call latency when compared to the same version of kubernetes compiled against go1.12.5.
What did you expect to see?
We expected similar api-call latency as in the baseline run compiled with go1.12.5
What did you see instead?
The api-call latency was visibly worse in the run compiled with golang1.13