 networkimprov
commented
4 years ago
networkimprov
commented
4 years ago Also discussed in #27266
And there are some interesting suggestions in https://news.ycombinator.com/item?id=21907144
Open robpike opened 4 years ago
networkimprov
commented
4 years ago Also discussed in #27266
And there are some interesting suggestions in https://news.ycombinator.com/item?id=21907144
 josharian
commented
4 years ago
josharian
commented
4 years ago I spent some time looking at this earlier this year (see e.g. CLs 172079 and 171820), and then stalled. The major impediment was the inscrutability of the linker. I hope that the new linker will open doors.
There is definitely lots more room for improvement. I have had private conversations with a few Go team members about improving the string encoding in pclntab. Most strings in the pclntab never actually get used by the program, and thus could be materialized lazily, perhaps from traditional compression or from a trie-ish encoding. This isn't trivial but you could do something like: Set up an appropriately-sized bss symbol with known offsets for all materialized strings, and when you need to materialize a string, decompress/assemble it into the correct spot for all other future users (atomically or with locks somehow). I did a very rough calculation and estimated that this could shrink pclntab by about 10%.
 thanm
commented
4 years ago
thanm
commented
4 years ago @jeremyfaller has also been brainstorming about this.
The concern I would have about such a scheme (putting on my devil's advocate hat) is that rodata can be shared across multiple instances of an executable across a given system, whereas if you go the BSS route, each process has to have it's own chunk of virtual memory.
On the other hand, it's not at all clear whether people care about that (who out there is running many instances of the same Go program on the same machine?).
 heschi
commented
4 years ago
heschi
commented
4 years ago I think there's some confusion in the blog post. Sorry if I'm the one confused instead.
The blog post talks about runtime.pclntab, but that symbol actually contains many tables, correct? ld.(*Link).pclntab() writes the pcfile and pcline tables, which are roughly in line with what you'd expect to be in a symbol named pclntab, but it also writes the pcsp and pcdata tables, which are quite different.
Has anyone checked which tables are actually the problem? I think all the commentary above is discussing the file/line tables.
josharian
commented
4 years ago Speaking for myself, I've looked at all of them; see CL 171760 for a recent tweak. I think the most attention is going to the file/line tables because that's where the most obvious inefficiencies are. (A few years ago I experimented with using a nybble-based instead of byte-based varint encoding for pc/value pairs. It helped, but not very much.) But all that doesn't foreclose the possibility of me being confused. :)
 cherrymui
commented
4 years ago
cherrymui
commented
4 years ago Yes, as @heschik said, there are several tables in pclntab.
Here is a breakdown:
hello world cmd/compile
.text 589993 10072652
pclntab 461293 5254373
func table 28364 166220
_func structs 145376 879432
pcsp 18305 175053
psfile 13466 208905
pcline 80049 1339649
pcdata 108492 1947840
strings 56025 496601
file table 11216 40673The strings are not large portion of the pclntab.
I have another confusion: the "growth" is growing over time, or the output size grows as the input size grows? I.e. are CockroachDB v19.1 and v1.0 built with same version of Go?
For the former, there are some growth over time, as we added more kinds of tables including e.g. inline tables, stack objects, and register maps, as mentioned in #27266.
For the latter, it seems growing linearly, at least from the table above.
 aclements
commented
4 years ago
aclements
commented
4 years ago As @thanm mentioned, @jeremyfaller has been looking at this problem recently and has done some preliminary analysis. He'll be back Thursday. He was going to prototype splitting the strings into two or three components (e.g., package+type+symbol), so each component can be deduped. I'm not sure what the current state of that is. As @cherrymui points out, the strings aren't a whole lot of the pclntab, but that also seems like low-hanging fruit. @jeremyfaller has also been looking at more typical binaries that have much longer package paths than cmd/compile, and hence more string data.
@cherrymui, what tool did you use to generate that breakdown? It would be good to also see the further breakdown of "pcdata", since there are several tables in that.
An important misconception in the blog post is that pclntab only contains traceback symbolization data. It also contains a lot of critical data for the garbage collector.
I did some experiments a while back with compressing stack maps. At the time, I noted that Huffman-coding the PCDATA delta stream roughly halved the size of the stack maps. However, that depended on the linker generating an optimal Huffman table for the whole binary, which would increase link time. Here's the code for those experiments, though it's probably bitrotted.
cherrymui
commented
4 years ago @aclements I just added print statements in the linker. I can do that for the pcdata tables.
 jeremyfaller
commented
4 years ago
jeremyfaller
commented
4 years ago As @thanm mentions, I was taking a look at starting to better encode pclntab. His tradeoffs are accurate -- trading some read-only-mappable memory for BSS. I was pulled to thinking about it because of internal Google binaries, where path names are quite long, and some experimentation showed that as much as 50% of pcln was used for strings. I started a design encoding paths by stripping common roots, and for function names, stripping module and type names. It's still early days, but I thought we'd see reductions in binary size > 5%. As @cherrymui points out, that gain will be minimal for the majority of users.
Right now, I was writing that document, and a change to cmd/objdump to generate stats to help us figure out where we need to focus our efforts.
aclements
commented
4 years ago The title of this bug (as well as the blog post) claims that pclntab grows super-linearly in the number of functions in the binary, but it's completely unclear to me what that claim is based on. It seems that they're varying both the Cockroach version and the Go version, so not only did Cockroach get bigger, but we also added more pclntab tables for the garbage collector since Go 1.2. That aside, the table in the blog post that compares Cockroach in 2017 to 2019 has exactly two data points in it, with the rest "projected", so I don't know how you get any non-linear projection from that.
The pclntab is large, a significant fraction of Go binaries, and its size is starting to cause issues for cutting-edge users, so this is worth working on. I just don't understand the basis for the super-linear growth claim.
cherrymui
commented
4 years ago @aclements here is a breakdown of the pcdata:
hello world cmd/compile
.text 589993 10072652
pclntab 461293 5254373
func table 28364 166220
_func structs 145376 879432
pcsp 18305 175053
psfile 13466 208905
pcline 80049 1339649
pcdata 108492 1947840
[0] 56055 1211541
[1] 35454 465937
[2] 16983 270362
strings 56025 496601
file table 11216 40673The register maps are the most of them.
aclements
commented
4 years ago The register maps are the most of them.
Great. I'm planning on getting rid of those. :)
Of all the pc tables, the pcline is actually the biggest. I wonder if that's because of instruction interleaving and inlining. I bet that's also wasting a lot of bits writing down very small deltas. Since we only use that table for symbolization, it doesn't have to be extremely efficient to decode, so we could imagine using a more compact encoding of it.
josharian
commented
4 years ago I bet that's also wasting a lot of bits writing down very small deltas.
That's what I was hinting at with a "nybble-based varint encoding" above.
In case it helps, here are my notes on this topic, from Feb 2016 (some things may have changed since then!):
pc/value pairs in the go1.2 symtab are encoded using varint encoding. But most values are very small, so I thought I'd try using nibble-at-a-time style varint encoding instead of byte-at-a-time varint encoding. You lose 1/4 bits to continuation markers instead of 1/8, but with small values it doesn't matter.
This only works because there are value pairs. The precise encoding is: first four bits are value, second four bits are pc. First bit of each nibble is a continuation bit. If both continuation bits are set, continue as before. If neither continuation bit is set, we're done. If one continuation bit is set but not the other, switch to byte-at-a-time varint encoding for the outstanding pc/value.
This actually does prove to be a more space-efficient encoding, just not enough of an improvement to warrant changing the symtab, since there are many consumers of it.
Results on the Go binary, which seems fairly typical:
binary size: 12190860 total pcln symbol size: 1469269 pcsp={current:114151 nibbles:109005} pcfile={current:32212 nibbles:30761} pcln={current:220683 nibbles:198681} pctotal={current:367046 nibbles:338447}
So a total of 28k of savings, or 0.23%.
Results are similar on the SSA branch.
This is all simulations based on parsing and replaying the symtab, not actually implementing the new encoding. There's an open question about the performance of a nibble-based encoding. (Better because memory efficient? Worse because more bit twiddling?)
josharian
commented
4 years ago I just don't understand the basis for the super-linear growth claim.
Here's some evidence against that claim.
I ran these commands in my GOROOT/pkg/tool/darwin_amd64 at master (8adc1e00aa1a92a85b9d6f3526419d49dd7859dd):
$ go tool nm -size * | grep runtime.pclntab | awk '{print $3"\t"$1}'
$ ls -l | awk '{print $5"\t"$9}'
I dropped the results in a spreadsheet and plotted "% of binary that is pclntab" (y-axis) vs "binary size" (x-axis). Results:
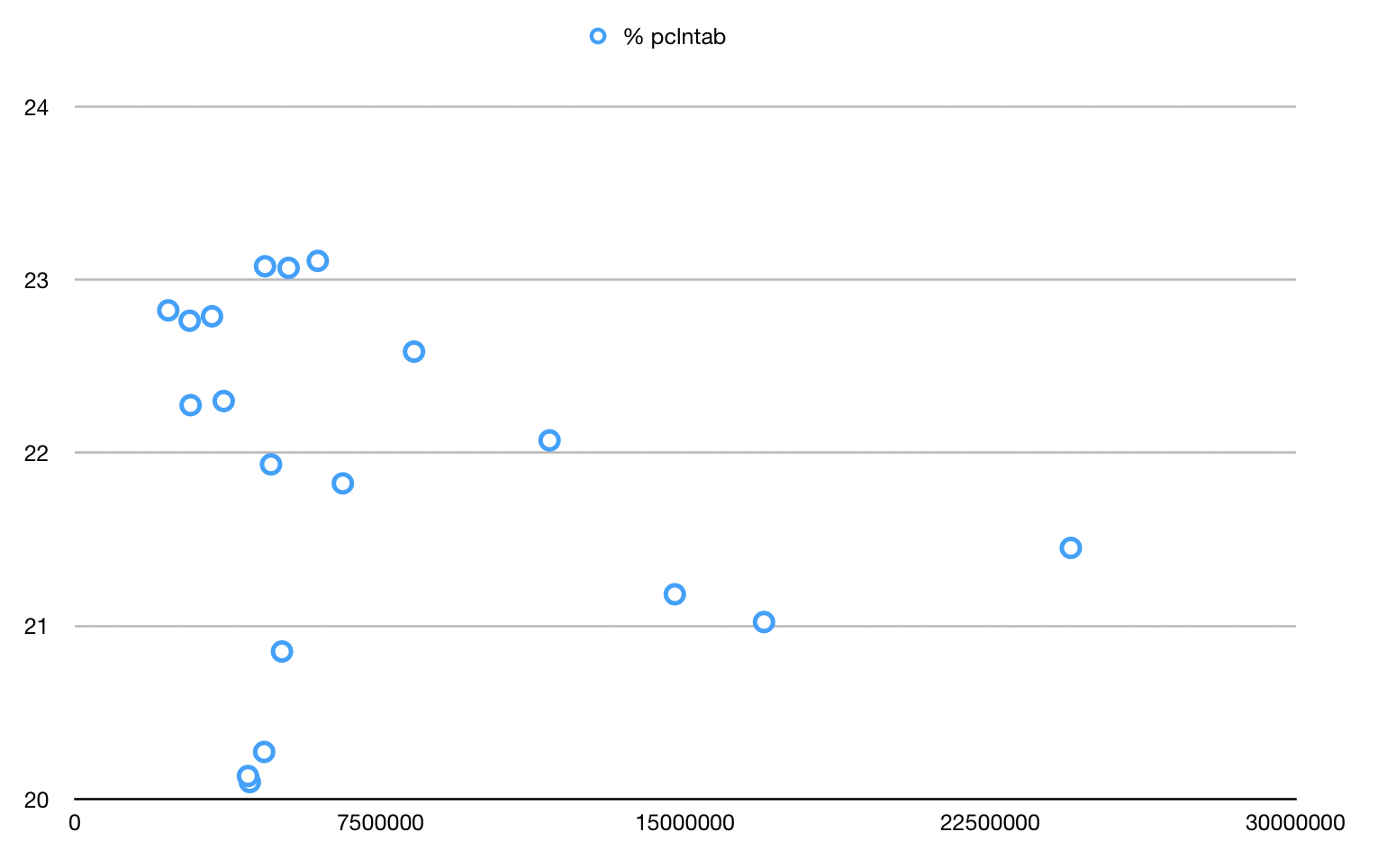
Looks pretty non-superlinear to me. So now we can get back to the task of shrinking it. :)
aclements
commented
4 years ago That's what I was hinting at with a "nybble-based varint encoding" above.
Thanks for sending your notes on that.
I was thinking of more compact but harder-to-decode formats for pcline in particular, such as Huffman coding (probably with a fixed table we generate from some corpus; maybe a per-package table generated by the compiler) or possibly Golomb-Rice coding (since pcline in particular is probably roughly geometrically distributed, though this wouldn't extend well to other tables).
Looks pretty non-superlinear to me. So now we can get back to the task of shrinking it. :)
Awesome. Thanks for running that experiment!
 beoran
commented
4 years ago
beoran
commented
4 years ago One interesting point mentioned on ycombinator is that there are platform-specific ways in which the pclntab could be stored, such as in DWARF format on ELF based OS, or, possibly externally, in .pdb files on Windows. In case this information is not available because it was stripped, the pclntab information needed could be calculated at run time. I don't know how feasible this idea would be for go, though, but I consider it worth mentioning.
 typeless
commented
4 years ago
typeless
commented
4 years ago If I understand correctly, the dead code elimination pass of the linker is quite conservative about removing methods implementing interfaces. It keeps the methods if their name matches any method of an interface. If the average per-function overhead of the GC metadata is low (like ~5% ), it's probably worth investigating how those redundant symbols would cost. I imagine it helps for projects like GUI toolkits where big interfaces are implemented by many widgets, while only a small set would actually be used by the user application.
jeremyfaller
commented
4 years ago So, I finally got a chance to put together a CL (cl/213830) that breaks pclntab up, looking at the sizes of each individual piece. It slightly overcounts (as there's deduplication in most of the pcln table in the linker). Sizes (percentage of pcln) for each section of all go tools for darwin are:
| 16 | PCLNTAB | _func structs: | pcsp: | pcfile: | pcln: | pcdata: | [0]: | [1]: | [2]: | Strings: | func names: | files: |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| addr2line | 843891 | 30.35% | 5.40% | 3.34% | 17.04% | 27.90% | 15.81% | 8.52% | 3.57% | 14.92% | 13.14% | 1.78% |
| api | 1347760 | 30.13% | 4.93% | 3.88% | 16.68% | 30.45% | 17.59% | 8.86% | 4.00% | 12.02% | 10.71% | 1.31% |
| asm | 1026665 | 24.64% | 4.87% | 3.29% | 20.97% | 32.58% | 17.60% | 8.85% | 6.13% | 11.84% | 10.34% | 1.50% |
| buildid | 614042 | 32.18% | 5.01% | 3.54% | 17.59% | 25.88% | 13.62% | 8.42% | 3.84% | 14.11% | 12.20% | 1.91% |
| cgo | 1032405 | 28.91% | 4.73% | 3.56% | 17.41% | 31.45% | 18.58% | 9.02% | 3.85% | 12.38% | 10.95% | 1.44% |
| compile | 5187539 | 17.01% | 4.67% | 4.54% | 25.85% | 43.97% | 27.56% | 10.90% | 5.51% | 10.19% | 9.59% | 0.60% |
| cover | 1183359 | 31.25% | 5.05% | 3.74% | 16.54% | 28.82% | 16.26% | 8.56% | 4.00% | 12.84% | 11.50% | 1.34% |
| dist | 791319 | 29.54% | 4.87% | 3.58% | 18.08% | 29.30% | 16.29% | 8.86% | 4.15% | 12.55% | 10.90% | 1.64% |
| doc | 1052734 | 30.77% | 4.88% | 3.60% | 17.25% | 29.08% | 16.48% | 8.73% | 3.88% | 12.32% | 10.96% | 1.36% |
| fix | 746928 | 30.83% | 4.73% | 3.53% | 17.46% | 28.17% | 15.66% | 8.72% | 3.79% | 13.10% | 11.43% | 1.68% |
| link | 1363392 | 26.18% | 4.61% | 4.04% | 18.29% | 32.74% | 19.56% | 8.77% | 4.41% | 12.45% | 11.00% | 1.45% |
| nm | 836271 | 30.49% | 5.39% | 3.35% | 16.96% | 27.79% | 15.72% | 8.49% | 3.58% | 14.95% | 13.16% | 1.79% |
| objdump | 926432 | 29.64% | 5.35% | 3.27% | 17.37% | 28.56% | 16.27% | 8.58% | 3.71% | 14.57% | 12.87% | 1.70% |
| pack | 505351 | 32.55% | 4.82% | 3.46% | 18.02% | 24.77% | 12.47% | 8.36% | 3.94% | 14.12% | 12.25% | 1.87% |
| pprof | 3062176 | 28.06% | 5.19% | 3.84% | 15.89% | 31.96% | 19.28% | 8.85% | 3.84% | 14.65% | 13.36% | 1.29% |
| test2json | 622255 | 31.79% | 4.94% | 3.57% | 18.11% | 25.72% | 13.36% | 8.40% | 3.95% | 13.82% | 11.99% | 1.84% |
| trace | 2517671 | 28.74% | 5.14% | 3.99% | 16.41% | 31.14% | 18.36% | 8.68% | 4.10% | 13.59% | 12.29% | 1.30% |
| vet | 1844222 | 28.46% | 4.84% | 3.97% | 16.25% | 32.38% | 19.38% | 9.02% | 3.98% | 12.61% | 11.26% | 1.35% |
As previously suspected, the filenames aren't nearly the problem in typical code they've been seen to be in some Google binaries. From this data, and an offline discussion with @aclements, it seems to me that the course of action should be:
1) Eliminate register maps (pcdata[0]), moving to a different strategy for preemptive scanning and debug call injection. 2) Look at changing the encoding for the _func objects. (Although the _func objects have rarely changed, their outsized effect on pcln's size suggests revisiting the design.) It's likely we could use variable width offset encoding for a number of lookups, and save on space. 3) Other fruit for runtime.pclntab compression: 3a) Only save stack maps at safe points. 3b) Consider a different bitmap encoding scheme. Besides a constant factor that can likely be removed here (because many of the length variables for the bitmaps use large field widths), there's the possibility that a different encoding scheme would save here. 3c) Consider ropes (or some other) structure for strings. 3d) Encode the length of the [func|file]name instead of the null byte encoding we use now. (no savings, but likely runtime speed improvements when looking up these strings.)
 xaionaro
commented
4 years ago
xaionaro
commented
4 years ago 3c) Consider ropes (or some other) structure for strings.
It's also required to reduce the size of a binary even in a compressed state. For example sometimes it's required to add an application to an xz-compressed initrd on a very small storage (like 8MiB). So in my extremely humble opinion it would be more useful if the first there will be considered ways to reduce data instead of compressing it.
Moreover sometimes performance is not important at all and size is very important. It would be nice to have an ability to choose the priorities (like -Os-vs--O2/-O3 in terms of gcc). For example it would be nice to be able to choose (via a compiler/linker-flag) an extremely-KISS-y (and slow) garbage collector which does not require so much extra data and logic (which takes size, too). Or, sometimes, even remove GC and all related tables at all.
josharian
commented
4 years ago Look at changing the encoding for the _func objects. Consider ropes (or some other) structure for strings.
You probably know this, but one sticking point with these ideas is that there is public API that exposes some of these things as strings. For example, runtime.Frame has fields Function and File that are both strings. Using an encoding for strings that is non-contiguous/compressed/whatever means having to assemble these strings. This requires particular care to avoid allocation in sensitive parts of the runtime and/or in hot code. (Thus the discussion of a dedicaged BSS segment, above.)
jeremyfaller
commented
4 years ago @josharian Yeah. @thanm mentioned it above, and the idea was to decode these strings into a space allocated in BSSNOPTR. It should be a relatively simple matter of preallocating the BSSNOPTR space at load time, and copying them out when they're used. The problem (again as Than pointed out) is that this decreases binary size at the expense of BSS. (Probably not an issue for most binaries, but still a tradeoff we'd make.)
 bradfitz
commented
4 years ago
bradfitz
commented
4 years ago The problem (again as Than pointed out) is that this decreases binary size at the expense of BSS. (Probably not an issue for most binaries, but still a tradeoff we'd make.)
One group of people who really want small binaries are Go developers targetting iOS. In certain iOS contexts (Network Extensions, Notification Extensions at least), the OS limits you to 15 MiB of total disk + memory. (That is, your binary is pinned into memory and can't page in from flash). So small binaries are critical to having enough memory left over to actually use.
So any optimizations that reduce binary size don't help (or might hurt!) if they require too much runtime memory allocation to decompress data.
bradfitz
commented
4 years ago 3d) Encode the length of the [func|file]name instead of the null byte encoding we use now. (no savings, but likely runtime speed improvements when looking up these strings.)
FWIW, I see in one binary here that 10.28% of the bytes of func name strings are bytes found in the prefix of the lexicographically following func name. (sometimes funcs are named prefixes of each other... runtime.systemstack and runtime.systemstack_switch looking at a binary now. Or closures...
crypto/tls.(*clientHelloMsg).marshal.func1.1
crypto/tls.(*clientHelloMsg).marshal.func1.2
crypto/tls.(*clientHelloMsg).marshal.func1.3
crypto/tls.(*clientHelloMsg).marshal.func1.4.1.1.1
crypto/tls.(*clientHelloMsg).marshal.func1.4.1.1
crypto/tls.(*clientHelloMsg).marshal.func1.4.1
crypto/tls.(*clientHelloMsg).marshal.func1.4.2
...So with (ptr/offset, len) encoding, in this binary with 19378 redundant bytes of func prefixes, and with 5878 funcs, we could only win (barely) with a uint16 max string length. 19378 - (5878 * 2 byte uint16) = 7,622 bytes of savings.
Likely not worth it, at least with that representation.
But encoding closure names differently would help a lot:
sqlite> select sum(length(distinct(Func))) from Bin where Func like '%.func%';
103500(Btw, I'm using https://github.com/bradfitz/shotizam to analyze Go binary sizes, slurping their pcln tables into sqlite)
josharian
commented
4 years ago encoding closure names differently would help a lot
That’s easy enough to implement, if we can settle on an encoding. The current one has the virtue of making it easy to know where to find the closure; I’ve used that a fair amount.
Want to suggest an alternative? (A counter per package?)
bradfitz
commented
4 years ago Want to suggest an alternative? (A counter per package?)
Sorry, I meant if we went with something like ropes (mentioned above) or were otherwise fine allocating at runtime for https://golang.org/pkg/runtime/#Func.Name then we could encode the same user-visible name in a much more compact form.
 embeddedgo
commented
3 years ago
embeddedgo
commented
3 years ago I've just reached the limit of 1 MiB Flash in STM32L476RG.
pclntab is 345 KiB (34%)
$ nm --size-sort -S shell.elf|tail -5 08050104 00000fd4 T time.Time.AppendFormat 08059f98 00001444 T fmt.(*pp).printValue 200024e8 00001a74 B runtime.mheap_ 08040ce0 00003728 T unicode.init 080a89c0 000565ac r runtime.pclntab
In my case I can't trade any RAM for smaller pclntab. The above STM32L476RG MCU has only 128 KiB of RAM. The most popular STM32F405/7 has "huge" 192 KiB RAM.
 emanuelpalm
commented
3 years ago
emanuelpalm
commented
3 years ago @embeddedgo Would it be possible to add a compiler flag that would generate a separate registry file, and then have pclntab only contain references into the registry file? In other words, it would not contain any kinds of strings. It would make interpreting log output harder, as it would require looking up log entries in the registry. In the case of IoT and other embedded scenarios, I would argue that could be well worth the reduction in binary size, however.
embeddedgo
commented
3 years ago I'm working on merging go1.16 changes to Embedded Go which is more about porting my noos/thumb and noos/riscv64 targets to this new Go version.
Thre are a lot of chanegs in 1.16 pclntab code. One of my use cases relies on smaller pclntab so I need to preserve this feature. I'll keep your proposal in mind while working.
 knz
commented
3 years ago
knz
commented
3 years ago Here's the 2021 update for the original link: https://dr-knz.net/go-executable-size-visualization-with-d3-2021.html
In summary, the bytes previously in pclntab are now stored elsewhere in the executable, but there's no net reduction in file size. In fact, it's getting worse.
 ww9
commented
3 years ago
ww9
commented
3 years ago An update on the article that originated this issue was posted recently: https://www.cockroachlabs.com/blog/go-file-size-update/
Archive link: https://web.archive.org/web/20210414213416/https://www.cockroachlabs.com/blog/go-file-size-update/
 rsc
commented
3 years ago
rsc
commented
3 years ago This followup article is generating more heat than light. Locking this issue to collaborators only.
This article contains results from applying a visualization tool: https://www.cockroachlabs.com/blog/go-file-size/ If the analysis is correct, pclntab needs a major redesign.
Separated from #6853 to keep the conversation focused.