 toothrot
commented
4 years ago
toothrot
commented
4 years ago /cc @bradfitz @rsc
Open rs opened 4 years ago
toothrot
commented
4 years ago /cc @bradfitz @rsc
 smasher164
commented
4 years ago
smasher164
commented
4 years ago I wonder if it's possible to make use of strings.Builder and pre-allocating with Grow(valuesPreAllocSize), instead of depending on unsafe and only using the buffer when the value fits inside it.
 bradfitz
commented
4 years ago
bradfitz
commented
4 years ago We're not adding unsafe usage to textproto.
 rs
commented
4 years ago
rs
commented
4 years ago With or without strings.Builder, this trick won't work if you grow the slice, as a copy of the backing array will be performed, which would be a waste: the strings created before the grow would still point on the old backing array, copying data for nothing and wasting the first half of the new grown backing array.
I tried a slightly more complex implementation that would cover requests with arbitrary number header values, but it added no gain from my training set of real-life requests/responses.
We could still use strings.Builder to hide the use of unsafe, but I'm not sure to see the point.
rs
commented
4 years ago We're not adding unsafe usage to textproto.
@bradfitz would it be accepted if hidden by the use of strings.Builder?
EDIT: scratch that, this can't be implemented with strings.Buffer. So I guess it's a no-go.
rs
commented
4 years ago @bradfitz would you be open to adding the Slice(off, len int) string method to strings.Builder to allow implementation of such tricks without the need of unsafe?
 bcmills
commented
4 years ago
bcmills
commented
4 years ago @rs, could you write all of the values into the strings.Builder and record the offsets, then convert all of the offsets to slices of the final string result?
rs
commented
4 years ago That could work yes, but it would make the code slightly more complex. I would personally prefer the Slice method on strings.Builder, but I guess it will require some more convincing :)
 josharian
commented
4 years ago
josharian
commented
4 years ago Another option (which would also complicate the code) is to have a fixed size, stack-allocated buffer for pending values to record and for the bytes involved. When a new kv pair is available, append the bytes to the bytes buffer and indices in the bytes buffer to the k/v pairs buffer. When either buffer is too full, convert the byte buffer to a string and add slices of that string to the map. This could all be wrapped up methods in a separate type, for sanity. (This is similar to the strings.Builder idea, but without the extra strings.Builder layer, since a plain ol' byte slice should suffice.)
Also, if the keys are commonly re-used, string interning might help.
rs
commented
4 years ago Good point, you would still pay for one extra copy, but it's better than nothing. String interning might work for some very common header values, I guess it could save a couple alloc per request with common content types and accept header values for instance.
Before spending more time on this, I'd love to hear from @bradfitz about the strings.Builder.Slice idea and if not, what is the probability to having more complex implementation as suggested above accepted.
bcmills
commented
4 years ago @rs, strings.Builder.Slice seems too prone to misuse: much too easy to accidentally create multiple underlying strings (due to growth) when the user really only intended to retain slices of a single big string.
rs
commented
4 years ago Agreed but it would still be safe and you would still save allocations by creating those substring from a common buffer.
 kokizzu
commented
3 years ago
kokizzu
commented
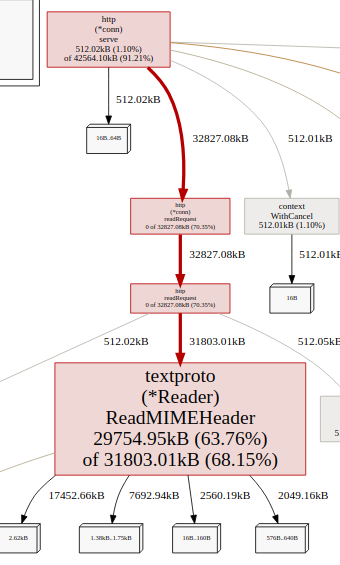
3 years ago Possibly related, this allocation grows to 200MB over a day or a week and cannot be reclaimed by GC:
 davecheney
commented
3 years ago
davecheney
commented
3 years ago Possibly related, this allocation grows to 200MB over a week and cannot be reclaimed by GC:
How are you asserting that this allocation cannot be garbage collected?
kokizzu
commented
3 years ago i run github.com/google/gops on the service:
$ gops pprof-heap 1
Profile dump saved to: /tmp/heap_profile363561508
$ gops gc 1 # force GC
$ gops pprof-heap 1
Profile dump saved to: /tmp/heap_profile269530696copy both heap_profile and compare, it doesn't decrease '__')
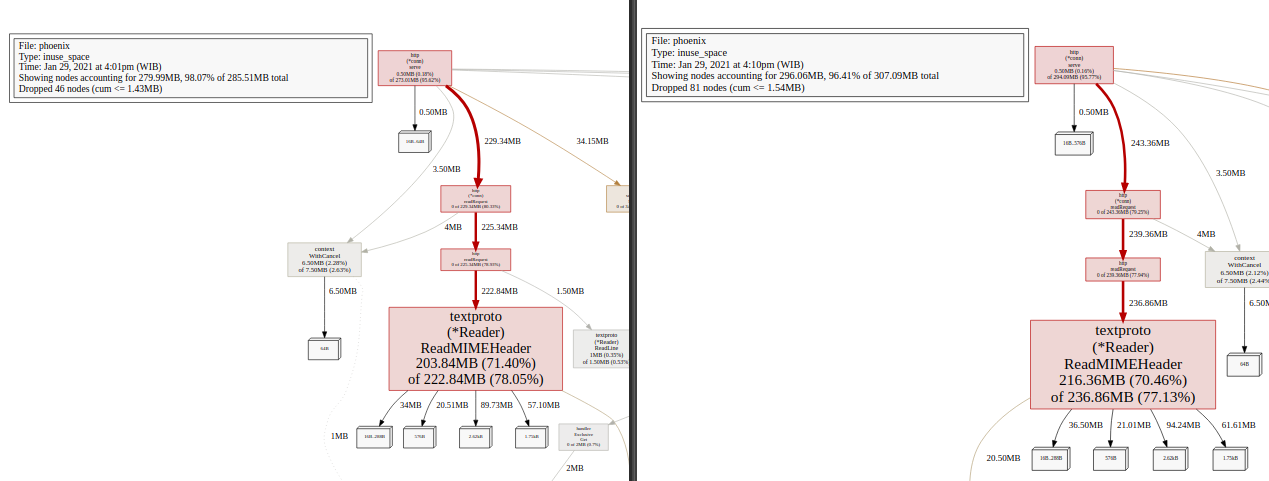
File: phoenix
Type: inuse_space
Time: Jan 29, 2021 at 4:10pm (WIB)
Showing nodes accounting for 296.06MB, 96.41% of 307.09MB total
Dropped 81 nodes (cum <= 1.54MB)
flat flat% sum% cum cum%
216.36MB 70.46% 70.46% 236.86MB 77.13% net/textproto.(*Reader).ReadMIMEHeader
20.50MB 6.68% 77.13% 20.50MB 6.68% net/textproto.canonicalMIMEHeaderKey
16.63MB 5.42% 82.55% 16.63MB 5.42% github.com/gorilla/context.Set
9.50MB 3.09% 85.64% 13MB 4.23% net/http.(*Request).WithContext
6.50MB 2.12% 87.76% 7.50MB 2.44% context.WithCancel
5MB 1.63% 89.39% 5MB 1.63% context.(*cancelCtx).Done
5MB 1.63% 91.02% 5MB 1.63% context.WithValue
4MB 1.30% 92.32% 4MB 1.30% syscall.anyToSockaddr
3.50MB 1.14% 93.46% 3.50MB 1.14% net/http.cloneURL
2.50MB 0.81% 94.27% 2.50MB 0.81% net/http.(*Server).newConn
2.50MB 0.81% 95.09% 2.50MB 0.81% net.newFD
2.01MB 0.65% 95.74% 2.01MB 0.65% bufio.NewReaderSize
1.55MB 0.5% 96.24% 1.55MB 0.5% regexp.(*bitState).reset
0.50MB 0.16% 96.41% 294.09MB 95.77% net/http.(*conn).serve
0 0% 96.41% 2.01MB 0.65% bufio.NewReader
0 0% 96.41% 5.03MB 1.64% github.com/kokizzu/phoenix/handler.Exclusive.Get
0 0% 96.41% 5.03MB 1.64% github.com/kokizzu/phoenix/handler.GetHandler
0 0% 96.41% 2.55MB 0.83% github.com/kokizzu/phoenix/router/authentication.JWT
0 0% 96.41% 25.22MB 8.21% github.com/kokizzu/phoenix/router/middleware.Exclusive.func1
0 0% 96.41% 25.22MB 8.21% github.com/go-chi/chi.(*Mux).Mount.func1
0 0% 96.41% 41.22MB 13.42% github.com/go-chi/chi.(*Mux).ServeHTTP
0 0% 96.41% 25.22MB 8.21% github.com/go-chi/chi.(*Mux).routeHTTP
0 0% 96.41% 39.72MB 12.93% github.com/go-chi/chi/middleware.Recoverer.func1
0 0% 96.41% 39.72MB 12.93% github.com/go-chi/chi/middleware.RequestID.func1
0 0% 96.41% 2.55MB 0.83% go.kokizzu.io/apinizer/v8/authorization.NewJWTAuthorization
0 0% 96.41% 2.55MB 0.83% go.kokizzu.io/apinizer/v8/authorization.getToken
0 0% 96.41% 10MB 3.26% main.main.func1
0 0% 96.41% 7.50MB 2.44% net.(*TCPListener).Accept
0 0% 96.41% 7.50MB 2.44% net.(*TCPListener).accept
0 0% 96.41% 7.50MB 2.44% net.(*netFD).accept
0 0% 96.41% 10MB 3.26% net/http.(*Server).ListenAndServe
0 0% 96.41% 10MB 3.26% net/http.(*Server).Serve
0 0% 96.41% 243.36MB 79.25% net/http.(*conn).readRequest
0 0% 96.41% 39.72MB 12.93% net/http.HandlerFunc.ServeHTTP
0 0% 96.41% 2.01MB 0.65% net/http.newBufioReader
0 0% 96.41% 239.36MB 77.94% net/http.readRequest
0 0% 96.41% 41.22MB 13.42% net/http.serverHandler.ServeHTTP
0 0% 96.41% 1.55MB 0.5% regexp.(*Regexp).MatchString
0 0% 96.41% 1.55MB 0.5% regexp.(*Regexp).backtrack
0 0% 96.41% 1.55MB 0.5% regexp.(*Regexp).doExecute
0 0% 96.41% 1.55MB 0.5% regexp.(*Regexp).doMatch
0 0% 96.41% 1.55MB 0.5% regexp.MatchString
0 0% 96.41% 2MB 0.65% sync.(*Once).Do
0 0% 96.41% 2MB 0.65% sync.(*Once).doSlow
0 0% 96.41% 2.50MB 0.81% syscall.Getsocknameor this caused by something else?
kokizzu
commented
3 years ago my friend found it https://rover.rocks/golang-memory-leak '__') probably it's gin-gonic/gin's context.Set that did the cache trashing that holds the allocation
 s-tokutake
commented
3 years ago
s-tokutake
commented
3 years ago We are facing the same problem as above. However, we does not use gin-gonic/gin.

josharian
commented
3 years ago Do you have any statistics about what the header values are? If there are a handful of very common values, perhaps we could hard-code some strings to re-use instead of allocate. (Like string interning, but hard-coded.)
 jonaz
commented
2 years ago
jonaz
commented
2 years ago We are also seeing a majority of the memory being used in ReadMIMEHeader in a simple proxy application. I have yet to investigate if clients send unusually large headers (for example many cookies).

Note that this is compiled with go 1.13. I've recompiled using go 1.17 now and will check if there are any improvements.
 CAFxX
commented
2 years ago
CAFxX
commented
2 years ago Spent a bit on this and, unfortunately, there does not seem to be a lot that can be done. The only approach I found that worked[^alt], given the constraints above, was interning (under the assumption that headers are not mostly unique) as that reduced both allocations and CPU usage, so this may be a good candidate for some form of string interning (not exposed to users):
I have pushed the poc here. If we think this may be useful I can try to refine it properly (the current interning logic is really crude).
If you have internal benchmarks it would be useful to run them on that poc to get a better sense of whether there are some workloads where this approach falls short.
While I haven't tested this on our production workloads yet, I can share that on one of our highest-traffic services ReadMIMEHeader accounts for ~2% of CPU time and ~2.5% of total allocations by bytes.
[^alt]: other attempts included adding more headers to the list of known headers, some form of single string allocation, and other similar micro-optimizations
What version of Go are you using (
go version)?What did you do?
For our use-case (a HTTP proxy)
textproto.ReadMIMEHeaderis in the top 3 in term of allocations. In order to ease the GC, we could pre-allocate 512 bytes to be used for small header values. This can reduce by half the number of allocations for this function.The patch is pretty small:
Please tell me if it's worth submitting a PR with this change.