 mknyszek
commented
3 years ago
mknyszek
commented
3 years ago Thanks for the really detailed report! I think your analysis of the situation makes a lot of sense. Maybe we can do something more clever about flushing mcaches. Honestly, forEachP seems somewhat overkill in this situation. One simple idea I have is a much more simple loop that just preempts each P directly without holding sched.lock.
~Another (and I like this one better) is to do the idle Ps here and then tell each P to do it when it next calls back into the scheduler (actively allocating Ps will already flush parts of it themselves). There's a chance we miss a P (e.g. a P transitions from active to idle and stays that way when we set the mark) because it'll be racy, but we can double-check in sweep termination. Missing a P should be unlikely.~ EDIT: This is already (almost) what forEachP does, minus the races. :)
This must happen before the next GC cycle; we can delay the whole process until sweep termination but then that just pushes the problem somewhere else.
CC @prattmic
 gopherbot
gopherbot rhysh
rhysh prattmic
prattmic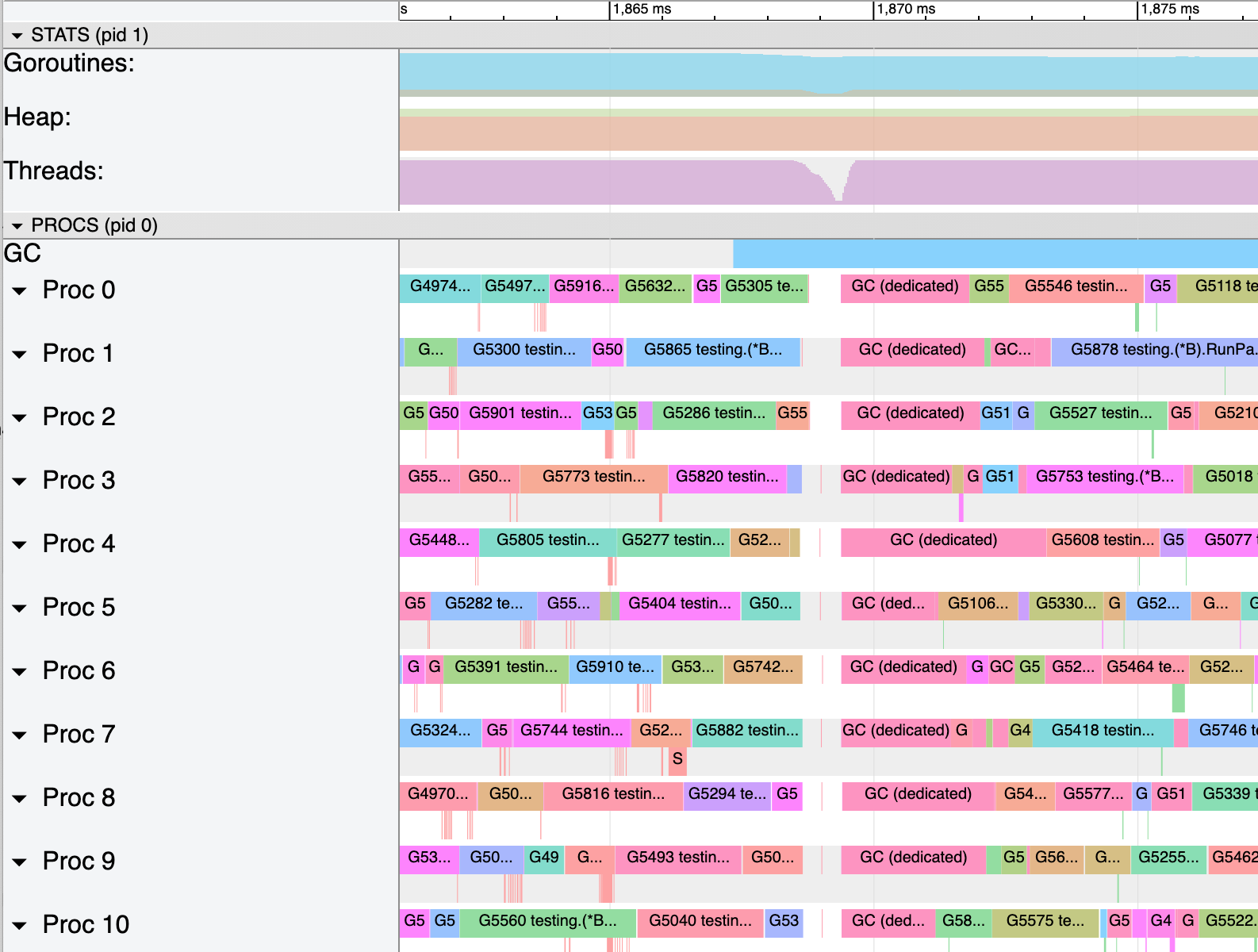







What version of Go are you using (
go version)?Most of the data I have is from
go1.15.6.Does this issue reproduce with the latest release?
Yes, I have seen the same effect (as viewed from execution traces) in an app that uses
go1.16.3.What operating system and processor architecture are you using (
go env)?GOOS=linux and GOARCH=amd64
What did you do?
I have an app that uses
go1.15.6on machines with 96 hyperthreads (GOMAXPROCS=96), and an app that usesgo1.16.3on machines with 36 hyperthreads (GOMAXPROCS=36).What did you expect to see?
I expected the app's goroutines to resume work immediately after the runtime declares end of the mark termination stop-the-world phase. I expected processors to resume work one at a time, staggered by at most a few tens of microseconds, with dozens of threads resuming useful work every millisecond.
What did you see instead?
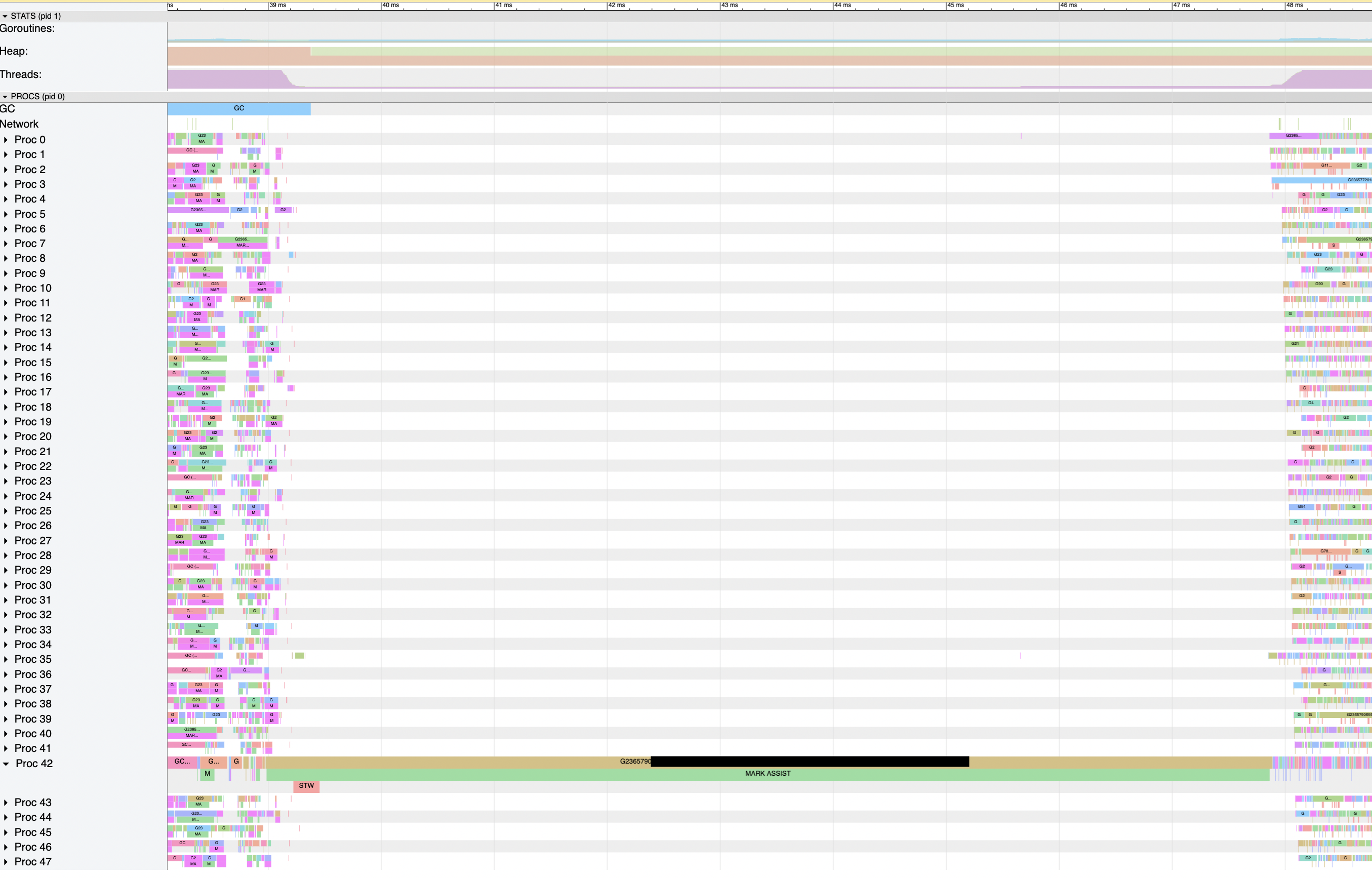
I see in execution traces that these applications are slow to resume useful work at the end of the garbage collector's mark phase. The application using Go 1.15 and 96-hyperthread machines has a particularly low latency goal (tail of a few milliseconds), and the slow resumption of work introduces about 5 to 10ms of extra idle time during each GC run.
My read of the traces, of profiles from
perf, and the runtime source is that althoughruntime.gcMarkDoneprepares goroutines to run (in large part by injecting the Gs that were blocked on assist credit into the global run queue) andruntime.gcMarkTerminationrestarts the world (so Ps can pick up and execute Gs), thegcMarkTerminationfunction follows that up immediately by usingruntime.forEachPto callruntime.mcache.prepareForSweep.When the goroutine that's finishing up the mark phase calls
runtime.forEachP, it has only recently allowed the world to restart, so most Ps are still idle. That function obtainsruntime.sched.lockand holds onto it while iterating the list of idle Ps, and calling the provided function for each one. My understanding ofsched.lockis that it guards access to the global goroutine run queue (among other things) -- and that in the two applications where I've seen this effect, nearly every goroutine in the program that would be runnable is sitting in the global run queue since nearly all of them became blocked on assist credit during the mark phase.I've included some screenshots from
go tool traceand contiguous section of the output ofgo tool trace -dbelow the fold, all from a single execution trace of the Go 1.15 app on a 96-hyperthread machine (during a load test, so it's especially busy). I'll walk through my understanding of how the events it shows line up with the code inruntime.gcMarkDoneand its callees.runtime.gcMarkTermination, https://github.com/golang/go/blob/go1.15.6/src/runtime/mgc.go#L1691runtime.startTheWorldWithSema, called fromruntime.gcMarkTermination, https://github.com/golang/go/blob/go1.15.6/src/runtime/mgc.go#L1752runtime.forEachP(probably a delayed acknowledgement of the first attempt, https://github.com/golang/go/blob/go1.15.6/src/runtime/proc.go#L1333)What I see in the
perfprofiles (collected with-Tfor timestamps,-gfor full call stacks, and-F 997for about 1ms per sample) is that the process does very little work at times (only one or two CPUs worth of samples, rather than dozens), and when I see what work it's doing during those times it is inside calls fromruntime.gcMarkDonetoruntime.systemstacktoruntime.gcMarkTermination.func4toruntime.forEachPfor several samples in a row.CC @aclements @mknyszek