 CannibalVox
commented
1 year ago
CannibalVox
commented
1 year ago There's not really a whole lot of information here- you said you'd previously looked at it in pprof, what did you run with pprof, can you link the output? I'd also consider changing the package in the title to net - for all we know, cgo could be working directly but net is calling it too many times.
 lifenjoiner
lifenjoiner ianlancetaylor
ianlancetaylor thepudds
thepudds

 prattmic
prattmic qmuntal
qmuntal




 gopherbot
gopherbot
What version of Go are you using (
go version)?Does this issue reproduce with the latest release?
Yes. It is long standing.
What operating system and processor architecture are you using (
go env)?go envOutputWhat did you do?
I think this is a new case of https://github.com/golang/go/issues/19574, taking effect on higher level
Connand specific platform Windows. It is suggested to be a new issue.This is a long term user observation.
It is traced into
cgocallbypprof(high percentage): on Windows,ConnRead/Writefinally calls APIWSARecv/WSASendaccordingruntime.cgocall.It is a very basic functionality for web servers, proxies, and other network data transferring tools.
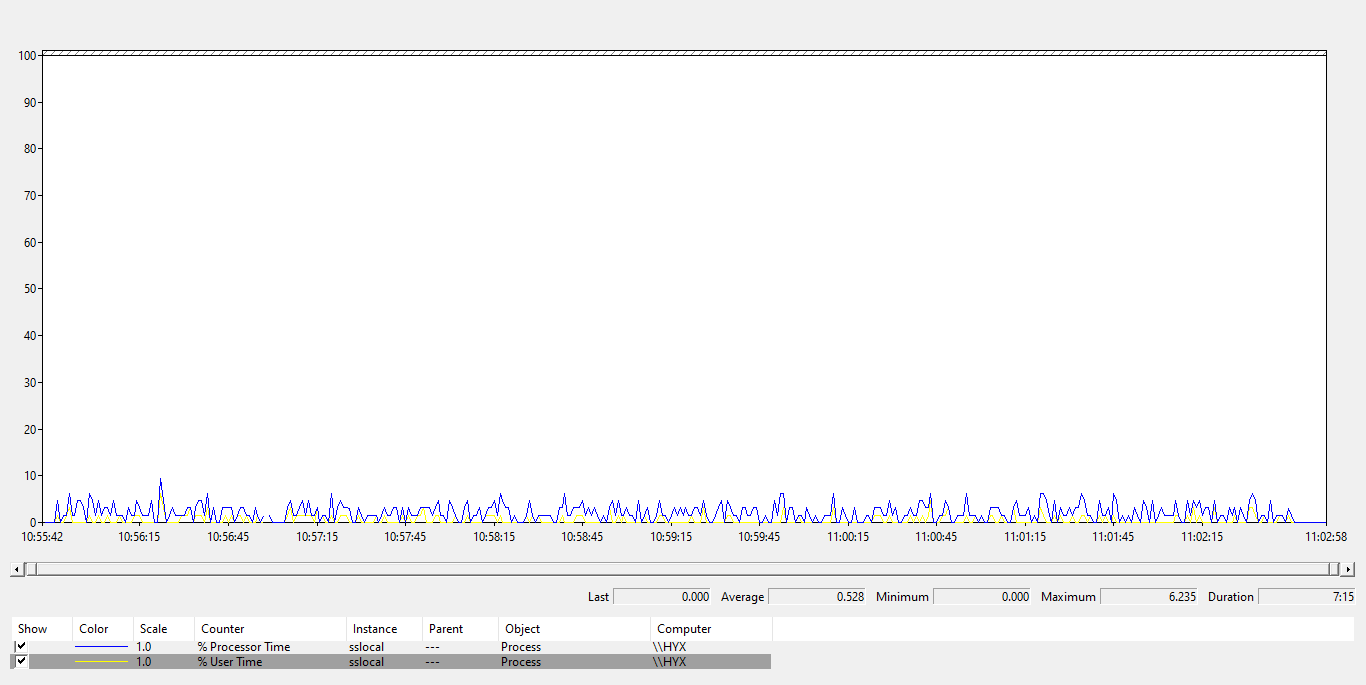
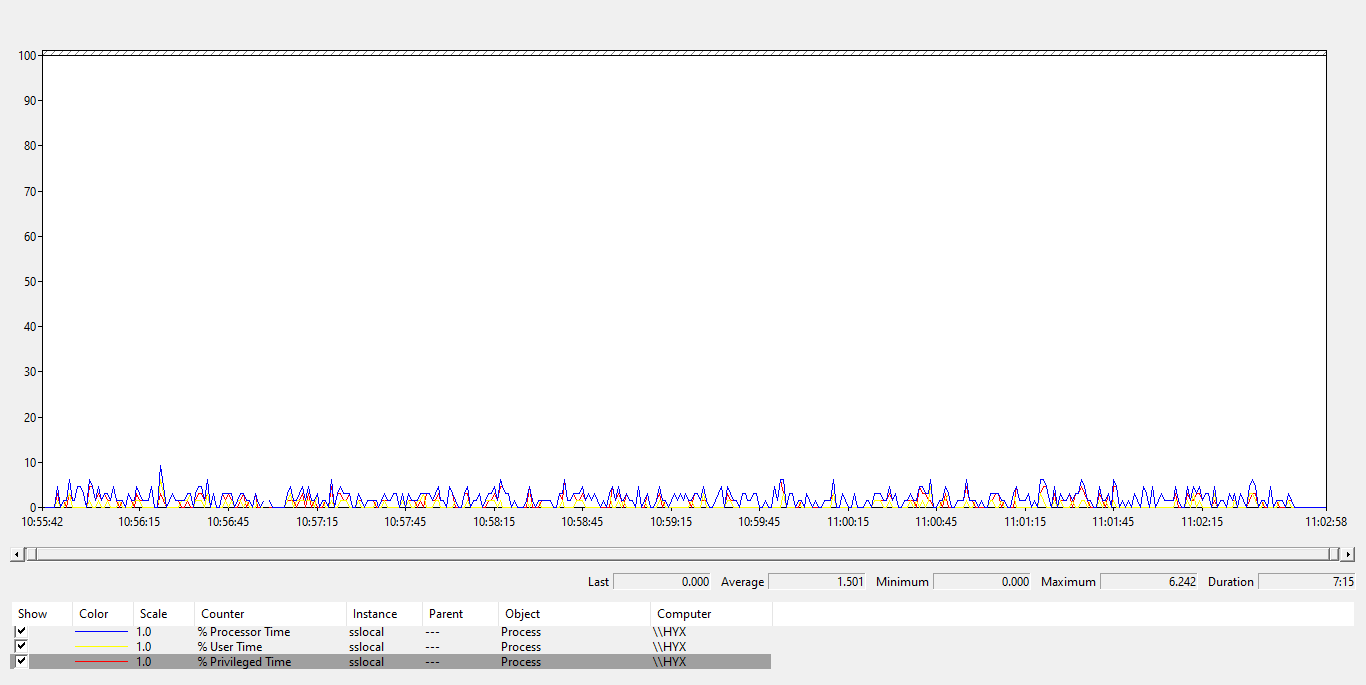
Low performance will pop up when there is a large amount of data, with high CPU usage (for example 10%+, task manager, OS level) which could be 10+ times than rust/c developed similar apps.
Since the scenario is network data transferring, I don't have a simple/short example that can reproduce the issue . Anyone who can generate it is appreciated.Proxies are the most typical case (both
Read/Write). My example is bellow in the reply.Test existing programs if you are interested
~~Maybe we can get started with some high rated open source proxies for now.~~ Here I used the client as a local proxy without any upstream proxies, and [wget](https://github.com/lifenjoiner/wget-for-windows/releases) (single thread) to download via it. **Attention**: downloading self hosted resources on the same machine doesn't help reproduce the difference. Loopback MSS = 65495 is adopted. go: [xray](https://github.com/XTLS/Xray-core/releases), [v2ray](https://github.com/v2fly/v2ray-core/releases), and [glider](https://github.com/nadoo/glider/releases). ``` xray.exe -config direct.json ``` ``` v2ray.exe run -config direct.json ``` ``` wget.exe -c -O nul -e https_proxy=127.0.0.1:5080Mitigation An alternative way to Read/Write directly is using a big enough buffer. By piling up packets data and then Read/Write in one time, it definitely reduces the context switching costs. But, it has disadvantages and does not 100% work:
My experimental local proxy with big buffer.
I have tried
ReadFrom, and observed 4k length packets are transferred on loopback interface, triggering high CPU usage.What did you expect to see?
Lower CPU usage. OS level.
What did you see instead?
High CPU usage.