 brunovollmer
commented
3 years ago
brunovollmer
commented
3 years ago The support would be awesome.
Open zldrobit opened 3 years ago
brunovollmer
commented
3 years ago The support would be awesome.
 Namburger
commented
3 years ago
Namburger
commented
3 years ago Hi folks, thanks for checking in! Previous experiments with yolo or any models requiring leakyrelu, we suggest changing the model architect to use normal relu activation (as suggested here). But it seems to me that at this point we should really push to have this activation functions be a part of our supported ops. Ill communicate with our teams to push for this. Thanks and regards
Namburger
commented
3 years ago Hi @zldrobit , @brunovollmer Okay!
In doing so your should have most ops mapped to the edgetpu for efficiency and still good accuracy and the compiler can supports these ops
 zldrobit
commented
3 years ago
zldrobit
commented
3 years ago @Namburger Thanks for your suggestion. After checking the PyTorch and TF documentation, I found that PReLU is actually identical to LeakyReLU. I could just substitute LeakyReLU with PReLU without any further modifications.
I have already implemented HardSwish with ReLU6 op in TensorFlow API (https://github.com/zldrobit/yolov5/blob/1f8499c047126d678f631b8ee73681c913c64995/models/tf.py#L82-L83)
elif isinstance(w.act, nn.Hardswish):
self.act = (lambda x: x * tf.nn.relu6(x+3) * 0.166666667) if act else tf.identityTensorFlow Hardswish op shown in Netron (from *.pb) is depicted as

After conversion from TensorFlow to TFLite, it seems that MLIR compiler translates
to Hardswish ops, as shown in netron (from *.tflite)

I think I have to disable some part of the translation process in MLIR tflite converter to keep ReLU6 ops instread of Hardswish ops.
Namburger
commented
3 years ago @zldrobit yes, PReLU is identical with an additional alpha parameter which you could default to 0.02(I believe) to keep it equivalent with LeakyReLU. Regarding HardSwish @Naveen-Dodda do you have some suggestions on how we were able to keep it as ReLU6?
 pirazor
commented
3 years ago
pirazor
commented
3 years ago @zldrobit and @Namburger, this is great discussion ! I know a lot of people trying to use YoloV5 on coral accelerator. It is really an amazing model. We are looking forward to hearing good news on this issue !
 PINTO0309
commented
3 years ago
PINTO0309
commented
3 years ago I have discussed this in my repository issues. https://github.com/PINTO0309/PINTO_model_zoo/issues/53
I haven't tried it yet to see if it works properly.

pirazor
commented
3 years ago @zldrobit, I was able to trick the MLIR by typing the Hardswish formula just slightly different such as x ReLU6(x+3) 0.16666671. Not sure it would impact the accuracy though. The problem is even though tflite converter now converts those ops as ReLU6 in the tflite quantized model, I don't see them in the Edge TPU compiled model.
@Namburger, I replaced the LeakyReLUs with PReLUs . But compiler did not map them on Edge TPU :(
Namburger
commented
3 years ago @pirazor Generally, "Operation is otherwise supported, but not mapped due to unspecified limitation" means that the input size are too large :( I would also love to hear about the impact of replacing Hardswish with Relu6 (interm of inference time and accuracy)
zldrobit
commented
3 years ago @Namburger I find a way to suppress HardSwish transformation in TFLite conversion. Just comment out TensorFlow v.2.4.0 code: https://github.com/tensorflow/tensorflow/blob/582c8d236cb079023657287c318ff26adb239002/tensorflow/compiler/mlir/lite/transforms/optimize_patterns.td#L247-L286 and build TensorFlow from source. Then, one can use this modified TensorFlow to convert models to TFLite format without HardSwish op.
| I tested TFLite models before/after the mentioned modification on Edge TPU: | model | correctness | inference time |
|---|---|---|---|
| yolov5s 320x320 w/ HardSwish | False | 370ms | |
| yolov5s 416x416 w/ HardSwish | False | 600ms | |
| yolov5s 320x320 w/o HardSwish | True | 100ms | |
| yolov5s 416x416 w/o HardSwish | True | 170ms |
The int8 quantized TFLite model is shown in Netron:

The log of Edge TPU compilation:

 glenn-jocher
commented
3 years ago
glenn-jocher
commented
3 years ago @zldrobit so it seems that hardswish op is a major cause of slowdown. Very interesting, nice work tracking this down!
We are currently preparing updated YOLOv5 models for a v4.0 release that use nn.SiLU() for all activations, replacing all instances of nn.Hardswish() and nn.LeakyReLU(0.1). These new models are slightly smaller and also slightly faster (on PyTorch GPU at least). I'm not sure what effect this will have on TFLite exports. Here's a link to the updated YOLOv5s: https://github.com/ultralytics/yolov5/releases/download/v3.1/yolov5s4.pt
I'm hoping nn.SiLU() can export directly to Swish layers in TF and TFLite, especially since Google has adopted the activation function in many of their own works like EfficientDet. The new v4.0 release should be live soon.
pirazor
commented
3 years ago @zldrobit, did you also resolve the leaky_relu to prelu conversion ? I think 8 more TPU operations will add some more speed.
glenn-jocher
commented
3 years ago @pirazor recent YOLOv5 v4.0 release replaces all nn.LeakyReLU() activations and nn.Hardswish() activations with nn.SiLU() activations. If the nn.SiLU() ops can be exported to run on TPU then most of the speed issues should be resolved.
zldrobit
commented
3 years ago @glenn-jocher @pirazor According to the updated YOLOv5 v4.0 release, I could convert all activation layers to Edge TPU. Inference time reduces from ~100ms (v3) to ~60ms (v4) for 320x320 input YOLOv5s model.

pirazor
commented
3 years ago @zldrobit, I've tested your tf-export script and was able to produce the same model. What I am curious is if we can also somehow map the resize nearest neighbor operations that are in the middle of the graph. The edgetpu will not have to split the graph again if they were supported. The compiler says the version is not supported, so maybe we can find a matching Tensorflow version. @Namburger do you know which version of Tensorflow we should use to support the resize nearest neighbor operations on Edge Tpu ?
glenn-jocher
commented
3 years ago @zldrobit that's great news! It seems I made the right change replacing Hardswish with SiLU.
@pirazor yes that's a good point. These are the two upscaling layers in YOLO that upscale from P3 to P4, and then from P4 to P5.
A second spot for improvement may be the STRIDED_SLICE layers. These are due to the very first YOLOv5 module called Focus(). This uses a method very similar Tensorflow space_to_depth: https://www.tensorflow.org/api_docs/python/tf/nn/space_to_depth
Perhaps in the next release I can try to align the two methods so that the TF space_to_depth can be used directly, perhaps improving export compatibility on the STRIDED_SLICE ops.
glenn-jocher
commented
3 years ago @pirazor the TF upsample op is here. Perhaps you can try alternative implementations (I see one is present but commented). https://github.com/zldrobit/yolov5/blob/c761637b51701565a9efbd585a05f093f8aa5f41/models/tf.py#L219-L228
glenn-jocher
commented
3 years ago @zldrobit the Focus() module that we might be able to replace with a space_to_depth layer is here. The problem is the current order of ops in the Focus() layer does not translate directly, so replacement is not possible in the v4.0 release models. I can try to work with the TF layer to create a compatible Focus() op for the next release. https://github.com/zldrobit/yolov5/blob/c761637b51701565a9efbd585a05f093f8aa5f41/models/tf.py#L78-L92
There is a prior feature request issue tracking this topic here: https://github.com/ultralytics/yolov5/issues/413
zldrobit
commented
3 years ago Plz check your CUDA version and your GPU model type.
Or try running models/tf.py again after rebooting your machine?
Actually, I didn't build TF with CUDA support because models/tf.py does not require CUDA for inference.
At 2021-01-11 20:25:13, "ngotra2710" notifications@github.com wrote:
@Namburger I find a way to suppress HardSwish transformation in TFLite conversion. Just comment out TensorFlow v.2.4.0 code: https://github.com/tensorflow/tensorflow/blob/582c8d236cb079023657287c318ff26adb239002/tensorflow/compiler/mlir/lite/transforms/optimize_patterns.td#L247-L286 and build TensorFlow from source. Then, one can use this modified TensorFlow to convert models to TFLite format without HardSwish op.
I try to do like this one. But got some error after I install tensorflow v2.4.0 from source. This is the error when I try python3 models/tf.py --weight ./runs/train/exp/weights/best.pt ....
E tensorflow/stream_executor/cuda/cuda_blas.cc:226] failed to create cublas handle: CUBLAS_STATUS_NOT_INITIALIZED W tensorflow/core/framework/op_kernel.cc:1763] OP_REQUIRES failed at conv_ops.cc:1106 : Not found: No algorithm worked! TensorFlow saved_model export failure: No algorithm worked! [Op:Conv2D]
@zldrobit Can you guide me how to install tensorflow from source properly?
This is the way I do:
git clone https://github.com/tensorflow/tensorflow.git cd tensorflow git checkout r2.4 Open optimize_patterns.td: delete everything from line 247 to 286 (HardSwishOp) ./configure (below is the configure, only yes in Cuda option)
You have bazel 3.1.0 installed. Please specify the location of python. [Default is /usr/bin/python3]:
Found possible Python library paths: /usr/lib/python3.6/dist-packages /usr/local/lib/python3.6/dist-packages /usr/lib/python3/dist-packages Please input the desired Python library path to use. Default is [/usr/lib/python3.6/dist-packages]
Do you wish to build TensorFlow with ROCm support? [y/N]: No ROCm support will be enabled for TensorFlow.
Do you wish to build TensorFlow with CUDA support? [y/N]: y CUDA support will be enabled for TensorFlow.
Do you wish to build TensorFlow with TensorRT support? [y/N]: No TensorRT support will be enabled for TensorFlow.
Found CUDA 11.1 in: /usr/local/cuda-11.1/targets/x86_64-linux/lib /usr/local/cuda-11.1/targets/x86_64-linux/include Found cuDNN 8 in: /usr/local/cuda-11.1/targets/x86_64-linux/lib /usr/local/cuda-11.1/targets/x86_64-linux/include
Please specify a list of comma-separated CUDA compute capabilities you want to build with. You can find the compute capability of your device at: https://developer.nvidia.com/cuda-gpus. Each capability can be specified as "x.y" or "compute_xy" to include both virtual and binary GPU code, or as "sm_xy" to only include the binary code. Please note that each additional compute capability significantly increases your build time and binary size, and that TensorFlow only supports compute capabilities >= 3.5 [Default is: 7.5]:
Do you want to use clang as CUDA compiler? [y/N]: nvcc will be used as CUDA compiler.
Please specify which gcc should be used by nvcc as the host compiler. [Default is /usr/bin/gcc]:
Please specify optimization flags to use during compilation when bazel option "--config=opt" is specified [Default is -Wno-sign-compare]:
Would you like to interactively configure ./WORKSPACE for Android builds? [y/N]: Not configuring the WORKSPACE for Android builds.
Preconfigured Bazel build configs. You can use any of the below by adding "--config=<>" to your build command. See .bazelrc for more details. --config=mkl # Build with MKL support. --config=mkl_aarch64 # Build with oneDNN support for Aarch64. --config=monolithic # Config for mostly static monolithic build. --config=ngraph # Build with Intel nGraph support. --config=numa # Build with NUMA support. --config=dynamic_kernels # (Experimental) Build kernels into separate shared objects. --config=v2 # Build TensorFlow 2.x instead of 1.x. Preconfigured Bazel build configs to DISABLE default on features: --config=noaws # Disable AWS S3 filesystem support. --config=nogcp # Disable GCP support. --config=nohdfs # Disable HDFS support. --config=nonccl # Disable NVIDIA NCCL support. Configuration finished
bazel build --config=cuda //tensorflow/tools/pip_package:build_pip_package pip3 install /tmp/tensorflow_pkg./tensorflow-2.4.0-cp36-cp36m-linux_x86_64.whl After that I check tensorflow lib, everything seem to be alright but I got the error that I mention above.
— You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub, or unsubscribe.
 Co2Link
commented
3 years ago
Co2Link
commented
3 years ago @zldrobit I've used your tf-android-tfl-detect script to get the edget tpu model. And it accuracy is way better than MobileNet SSD V2 from the offical site.
But as mentioned in #297 . I consistently encounter the following error after i switching from MobileNet SSD V2 to yolov5s.
F :859] transfer on tag 2 failed. Abort. Deadline exceeded: USB transfer error 2 [LibUsbDataOutCallback]
Can you test if you will encounter the same error when running for a long period of time(couple of hours) ?
zldrobit
commented
3 years ago @ling9601 Thanks. My colleague run YOLOv5 v4 320x320 on EdgeTPU for 24 hours yesterday without errors.
He uses dpkg libedgetpu1-max library.
We just plug Coral EdgeTPU to a USB dock on PC.
So, there should not be any power issues in our situation.
Co2Link
commented
3 years ago @zldrobit Thanks. I also run YOLOV5 on EdgeTPU for 48 hours on an ubuntu PC without errors. But error occur when runing on raspberrypi 4(Raspberry Pi OS) even with TPU plugged to a USB hub. so, it may be an os issue?
zldrobit
commented
3 years ago @ling9601 I agree with you, but I can't assure that since I haven't an RPI.
 pliablepixels
commented
3 years ago
pliablepixels
commented
3 years ago @zldrobit @glenn-jocher is there a repo that holds links to the latest compiled yolov5 weights specifically for edgeTPU? It looks like things are evolving reading the thread above. I develop open source for home security and a lot of my users use coral. We are limited to using mobiledet or mobilenet - both of which are terrible on accuracy (but good perf). If yolov5 is similar in accuracy to yolov4 it would be a big win for my users! Thanks
zldrobit
commented
3 years ago @pliablepixels You could export and test Edge TPU model with https://github.com/zldrobit/yolov5/tree/tf-android-tfl-detect. PS: I attached the COCO Edge TPU model with 320x320 input resolution in case you're interested.
pliablepixels
commented
3 years ago Issue moved to the right repo. Thanks @zldrobit
zldrobit
commented
3 years ago @pliablepixels plz report Edge TPU YOLOv5 related issues to https://github.com/ultralytics/yolov5/pull/1127
 batrlatom
commented
3 years ago
batrlatom
commented
3 years ago @pliablepixels You could export and test Edge TPU model with https://github.com/zldrobit/yolov5/tree/tf-android-tfl-detect. PS: I attached the COCO Edge TPU model with 320x320 input resolution in case you're interested.
I love the work! Thank you for the effort. Do you think you could share the script for prediction on the google coral devboard which is compatible with the tflite model you shared?
btw ... 60ms per image is comparable with the mobiledet and we could only improve from there. Perfect! Unfortunatelly I am getting 350ms per prediction on this
My current code for inference is:
import argparse
import time
import numpy as np
from PIL import Image
from PIL import ImageDraw
from pycoral.adapters import common
from pycoral.adapters import detect
from pycoral.utils.dataset import read_label_file
from pycoral.utils.edgetpu import make_interpreter
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('-m', '--model', required=True,
help='File path of .tflite file')
parser.add_argument('-i', '--input', required=True,
help='File path of image to process')
parser.add_argument('-l', '--labels', help='File path of labels file')
parser.add_argument('-t', '--threshold', type=float, default=0.4,
help='Score threshold for detected objects')
parser.add_argument('-o', '--output',
help='File path for the result image with annotations')
parser.add_argument('-c', '--count', type=int, default=5,
help='Number of times to run inference')
args = parser.parse_args()
labels = read_label_file(args.labels) if args.labels else {}
interpreter = make_interpreter(args.model)
interpreter.allocate_tensors()
#image = Image.open(args.input)
#_, scale = common.set_resized_input(
# interpreter, image.size, lambda size: image.resize(size, Image.ANTIALIAS))
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
input_index = interpreter.get_input_details()[0]["index"]
output_index = interpreter.get_output_details()[0]["index"]
sizes = interpreter.get_input_details()[0]["shape"]
print(sizes)
input_data = np.ones(sizes)
scale, zero_point = input_details[0]['quantization']
input_data = input_data / scale + zero_point
input_data = input_data.astype(np.uint8)
#common.set_input(interpreter, input_data)
interpreter.set_tensor(input_index, input_data)
print('----INFERENCE TIME----')
print('Note: The first inference is slow because it includes',
'loading the model into Edge TPU memory.')
for _ in range(args.count):
start = time.perf_counter()
interpreter.invoke()
inference_time = time.perf_counter() - start
print(inference_time)
output_data = interpreter.get_tensor(output_index)
print(output_data)
if __name__ == '__main__':
main()
@batrlatom I use an Intel CPU with 20 threads for the test, and it should be faster than the CPU on the dev board.
EDIT: There are still 12 operators running on CPU
I don't have a complete script for the dev board, but you could refer to this comment.
In the comment, there is code for the bounding box reconstruction and NMS.
You could just add the code to your script, and test it.
 wb666greene
commented
3 years ago
wb666greene
commented
3 years ago @zldrobit @pliablepixels I stumbled upon this looking for a solution as to why my MPCIe TPU module works on Ubuntu 20.04 but not Windows 10 (dual boot i3-4025 system) but running a yolo model on the TPU is something I really want to try! Plugging in the USB3 TPU my Windows code runs, so my PyCoral installation seems correct. I've just ported my TPU code from "legacy" edgetpu to pycoral.
I'm doing pretty much like what @pliablepixels has done with ZoneMinder, adding AI to existing security DVR/NVR (Lorex, Amcrest, GeoVision, etc.) setups. https://github.com/wb666greene/AI-Person-Detector
Could either of you point me to the labels file for this yolo_v5 model? Also what is the output format? I need the object.id (0 for a person with mobilenetSSD_v2 tflite_edgetpu model), the box points, and detection confidence. I've downloaded the 320x320 yolo_5 model @zldrobit was kind enough to link, and am ready to drop it into my system once I can figure out how to decode the inference output.
@batrlatom you seem to be basically using the Edge TPU PyCoral detection example code, it only does a single image. If arg.count is 1, the inference time includes loading the model, but 350 mS seems unreasonable. If count is greater than 1, then the same image inference is repeated again, which should be pretty much the best case inference time, what times are reported for counts greater than one? Perhaps the "12 CPU operations" are killing the TPU performance which makes the TPU not usable. I get ~4.5 fps for yolov4-416 with the Jetson Nano sample code. Getting ~3fps with yolo an a TPU would not be very useful to me.
Edit: A quick look at @zldrobit site made it look like "person" is index zero so I made two trivial changes to run the yolov5 model, inference seemed to run but I got error trying to use the output:
File "TPU.py", line 990, in TPU_thread detection=detect.get_objects(model, confidence, (1.0,1.0)) File "C:\Users\MINI PC\AppData\Local\Programs\Python\Python37\lib\site-packages\pycoral\adapters\detect.py", line 192, in get_objects count = int(common.output_tensor(interpreter, 3)[0]) File "C:\Users\MINI PC\AppData\Local\Programs\Python\Python37\lib\site-packages\pycoral\adapters\common.py", line 29, in output_tensor return interpreter.tensor(interpreter.get_output_details()[i]['index'])() IndexError: list index out of range
I'm new to pycoral, all I did was change:
model = make_interpreter("mobilenet_ssd_v2/mobilenet_ssd_v2_coco_quant_postprocess_edgetpu.tflite") model = make_interpreter("mobilenet_ssd_v2/yolov5s-int8_edgetpu.tflite")
And change my input image resize from 300,300 to 320,320. I could easily be missing something if the input setup for yolo5 is different from mobilenet_ssd_v2.
glenn-jocher
commented
3 years ago @wb666greene yes person is index 0 in the class vector. You can see the full list of classes in the data.yaml file: https://github.com/ultralytics/yolov5/blob/238583b7d5c19029920d56c417c406c829569c75/data/coco.yaml#L20-L30
You can print class indices with:
# Print YOLOv5 model COCO classes
with open('data/coco.yaml') as f:
d = yaml.load(f, Loader=yaml.FullLoader) # dict
for i, x in enumerate(d['names']):
print(i, x)320 image size works well also.
wb666greene
commented
3 years ago @glenn-jocher
Thanks, I don't really need the full labels file as once the inference has been run I only look at the output inside an if statement where the object id matches that for a "person" so knowing that person is index zero is sufficient.
You may not have seen my edit where I tried with the assumption that person was index 0 but got an error in detection=detect.get_objects(model, confidence, (1.0,1.0)) which is run immediately after model.invoke()
Do you have any idea what I did wrong?
Since the sample code accepts a --model command line parameter and doesn't seem to have any parameters to account for differences in detection output formats, I assume the detection output format has been "standardized". I know there seem to be differences in the returned object between pycoral and edgetpu:
if __PYCORAL__ is False:
detection = model.detect_with_image(frame, threshold=confidence, keep_aspect_ratio=True, relative_coord=False)
for r in detection:
if r.label_id == 0:
# extract the bounding box and box and predicted class label
box = r.bounding_box.flatten().astype("int")
##detect_label = labels[r.label_id] #not being used anywhere now
(startX, startY, endX, endY) = box.flatten().astype("int")
else:
common.set_input(model,frame)
model.invoke()
detection=detect.get_objects(model, confidence, (1.0,1.0))
for r in detection:
if r.id == 0:
startX=r.bbox.xmin
startY=r.bbox.ymin
endX=r.bbox.xmax
endY=r.bbox.ymax
`@batrlatom I ran the code you posted and superficially seem to get pretty good performance using the yolo5 edgetpu.tflite model that @zldrobit linked.
Running Ubuntu 16.04 on an i3-4025 with the USB3 TPU the first inference is ~65 milliSeconds, the 4 repeats average ~49 mS. Using the MPCIe module the first inference is ~56 mS and the others average ~43 mS.
But I still can't make any sense of the output from interpreter.get_tensor(output_index) so I've no idea iif its actually doing anything useful or not.
[edit] I just noticed that you have commented out the loading of the input image and are running the inference on an array of ones. Maybe that is why its not detecting anything.
wb666greene
commented
3 years ago @zldrobit
PS: I attached the COCO Edge TPU model with 320x320 input resolution in case you're interested.
I've downloaded it and tried to run it on my Coral TPU. It appears to run but I can't make any sense of the outputs -- I need things like object ID, box points of located object, and detection confidence.
Could you please give me a clue?
I'm using PyCoral TPU support, which is supposed to be just a wrapper around tflite and OpenCV 4.x for visualization and camera rtsp stream decoding.
 binqi-sun
commented
3 years ago
binqi-sun
commented
3 years ago @pirazor Hi, I am wondering if you have solved the prelu issue on edgetpu? I am also trying to use prelu and meet the same problem as yours. I have tried to reduce the input size but it does not work. :( I am Curious if you have solved this issue?
zldrobit
commented
3 years ago @wb666greene Sorry for the late reply. After some investigations, I found that PyCoral lacks some functions for inference. For example, there isn't an output_details() function to get the quantization parameters for the final output (https://coral.ai/docs/reference/py/pycoral.adapters/#module-pycoral.adapters.common). Would you stick to the tflite inference API since PyCoral is a wrapper of tflite?
EDIT: Add PyCoral API reference link

I was converting yolov5 int8 TFLite model to EdgeTPU, but LeakyRelu and Hardswish ops are not supported. (https://github.com/ultralytics/yolov5/pull/959)
LeakyRelu and Hardswish is the major part of CPU operations (8+51=59 out of 72). I guess if they are supported in EdgeTPU, the model will run significantly faster.
Network inspection by netron is as below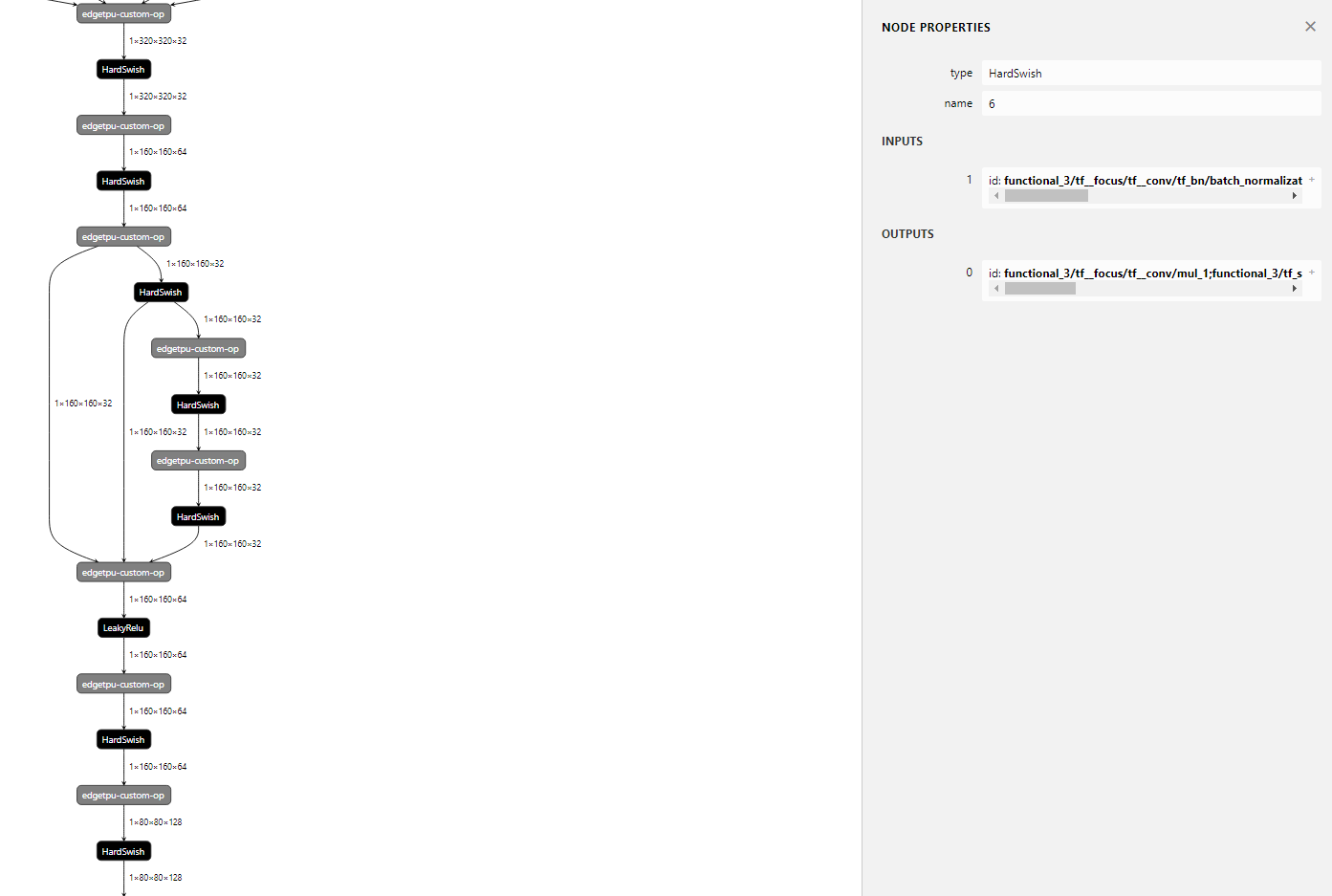
Edge TPU Compiler version 15.0.340273435
Here is the converted EdgeTPU model yolov5s-int8_edgetpu.zip
PS: I saw https://github.com/google-coral/edgetpu/issues/165 also discussing the support for LeakyRelu.