 lxuechen
commented
3 years ago
lxuechen
commented
3 years ago I think now we're seeing something on the right track. The main issue here is that you should just take zs[-1, :, 1] as logqp to make it consistent with what we had before, as opposed to summing over the first dimension, which would mean inflating the KL divergence.
 mtsokol
mtsokol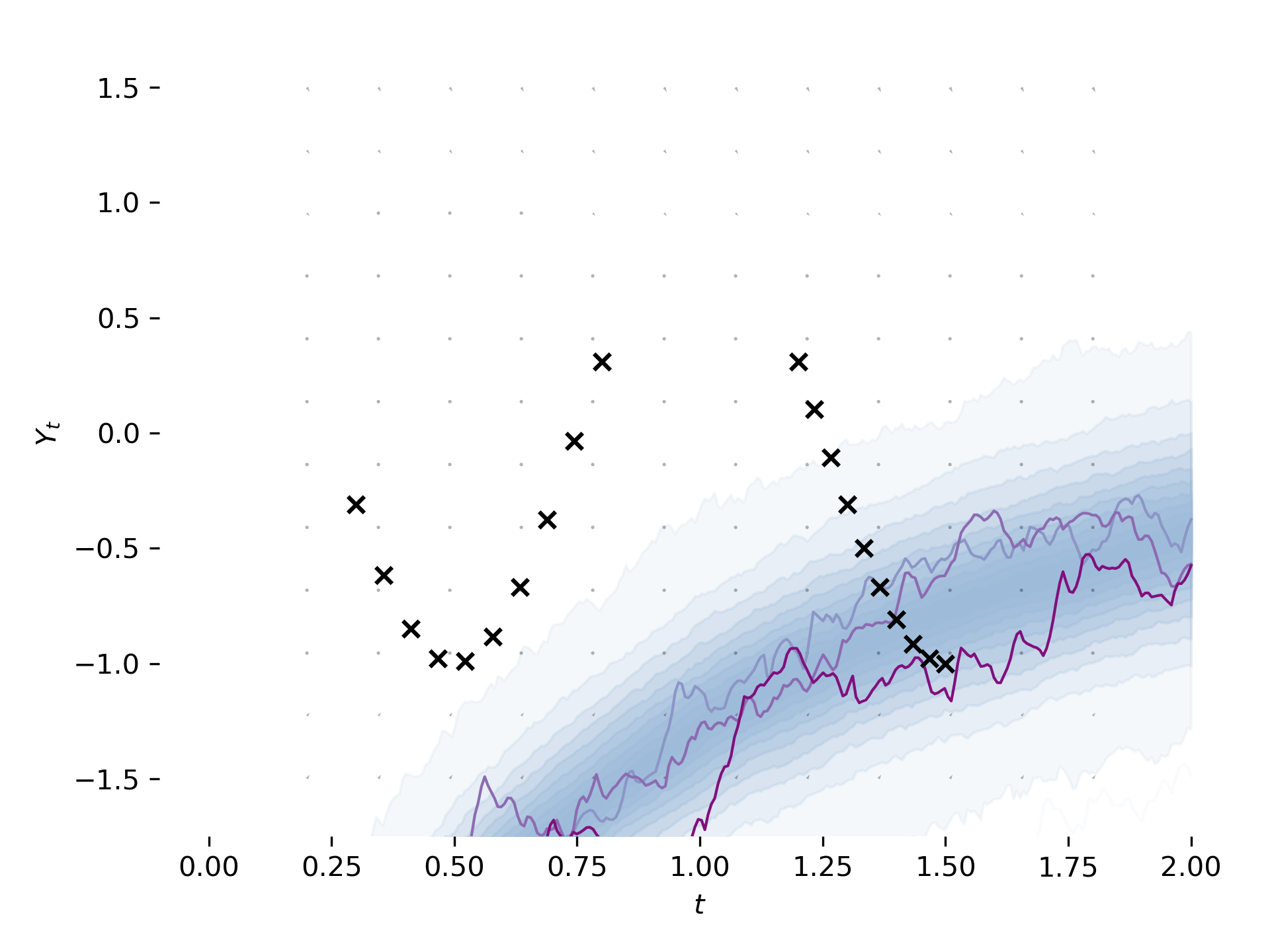
Hi!
Following next instructions in https://github.com/google-research/torchsde/pull/38#issuecomment-686559686 here's my idea for that - I've looked what flow exactly is for previous version available on
masterand hopefully recreated it.That's a result after 300 iterations (still not similar to 300 in previous version):
WDYT?
btw. running it locally was still slow and burning laptop so I ended up running it on CGP instance (e2-highcpu-8) as I found they have student packs and got one iteration at 4sec.