 eqv
commented
4 years ago
eqv
commented
4 years ago Just to avoid flaming: The idea is to sample a very small percentage of the inputs during fuzzing.
Open inferno-chromium opened 4 years ago
eqv
commented
4 years ago Just to avoid flaming: The idea is to sample a very small percentage of the inputs during fuzzing.
 inferno-chromium
commented
4 years ago
inferno-chromium
commented
4 years ago Just to avoid flaming: The idea is to sample a very small percentage of the inputs during fuzzing.
Corrected in description.
 mboehme
commented
4 years ago
mboehme
commented
4 years ago What are path or state transitions?
 lszekeres
commented
4 years ago
lszekeres
commented
4 years ago What are path or state transitions?
I think that refers to a "coverage point" (eg. edge / block / region / or what have you).
mboehme
commented
4 years ago Great idea! I suppose this would show the coverage overlap (difference) between fuzzers? Might help with debugging a fuzzer.
eqv
commented
4 years ago exactly & relative frequency of the areas explored.
lszekeres
commented
4 years ago Great idea! I suppose this would show the coverage overlap (difference) between fuzzers? Might help with debugging a fuzzer.
Note that the coverage overlap/difference between fuzzers is already shown by the unique coverage plots.
inferno-chromium
commented
4 years ago I think this one is about edge/region transitions and not about edges/regions covered.
 aflgo
commented
4 years ago
aflgo
commented
4 years ago Maybe @eqv can clarify, but I understood it more like what he mentioned in his blog post.
https://hexgolems.com/2020/08/on-measuring-and-visualizing-fuzzer-performance/
(I would also be intetested in the data).
eqv
commented
4 years ago Like @aflgo said, initially it was meant to be about the difference in frequency. Which is stronger than difference in coverage. The downside is that it requires additional changes to be measured. Note that we cannot simply compute this based on the queue. Instead we would have to live sample from the fuzzing process. Like the visualization done by Brandon, but as a proper measurement: https://twitter.com/gamozolabs/status/1288440436680306688
eqv
commented
4 years ago For the record: While super cool to watch, I don't think that kind of visualization (cookie dough) will help to understand the performance of fuzzers on real programs - We would need better ways to aggregate and plot the data.
mboehme
commented
4 years ago Fuzzbench distinguishes runner and measurer and only the seed corpus ever reaches the measurer. So, getting coverage statistics right from the fuzzing process might be a bit more difficult.
If covered_regions.json contains information on the number of seeds that exercise a certain region, you could generate at least an approximation. Does that work?
eqv
commented
4 years ago It's certainly nontrivial to predict this from the queue... you will at least also need to know how often the seed where mutated. And even then you will probably only get a very poor approximation (because most mutations will go to an error path that is triggered MUCH more often that the part that was actually the reason why the seed was stored). Would be interesting to compare though.
 jonathanmetzman
commented
4 years ago
jonathanmetzman
commented
4 years ago Fuzzbench distinguishes runner and measurer and only the seed corpus ever reaches the measurer. So, getting coverage statistics right from the fuzzing process might be a bit more difficult.
If covered_regions.json contains information on the number of seeds that exercise a certain region, you could generate at least an approximation. Does that work?
Right I think to implement this we could try to wrap LLVMFuzzerTestOneInput so that we can sample inputs in a fuzzer-agnostic way.
mboehme
commented
4 years ago The following is based on data from Stephan Lipp (@sphl) of TU Munich. I used that data to play around with ways to visualize coverage progress. The graphs can be auto-generated from a CSV file containing function-level coverage information over time (amongst others) and the CG dot file produced by LLVM, plus a bit of R and GraphViz.
Fun little coverage visualizations inspired by @Gamozolabs cookie-dough. These are call graphs of freetype2. Red is uncovered in all trials, yellow is covered by at least one trial and less than 20 trials, Green is covered in all 20 trials.
Still playing around with better ways to visualize. Was hoping to see some kind of coverage-frontier advancing forward from the root node. Instead it's looks like increasingly more parts of a Christmas tree coming on.

| AFL (23 hours in 32 frames) | Honggfuzz (23 hours in 32 frames) |
|---|---|
 |
 |
Maybe this should differential coverage instead?
 Graphviz doesn't let me break the ranks to produce a format with less blank space.
Graphviz doesn't let me break the ranks to produce a format with less blank space.
At the top, the number of BBs over the number of trials covering the BBs at the end of the 24hr campaign. For instance, for AFL a bit over 10k BBs are covered in none of the trials while a bit over 3k BBs are covered in all trials. There are only 2 BBs that are covered by 9 and 19 trails, respectively.
At the bottom, we see coverage over time for a single run. Obviously, Honggfuzz continuous to make progress while the campaign for AFL is stalled.
Maybe this one should also be animated over time?

 dliyanage
commented
4 years ago
dliyanage
commented
4 years ago Maybe @eqv can clarify, but I understood it more like what he mentioned in his blog post.
https://hexgolems.com/2020/08/on-measuring-and-visualizing-fuzzer-performance/
(I would also be intetested in the data).
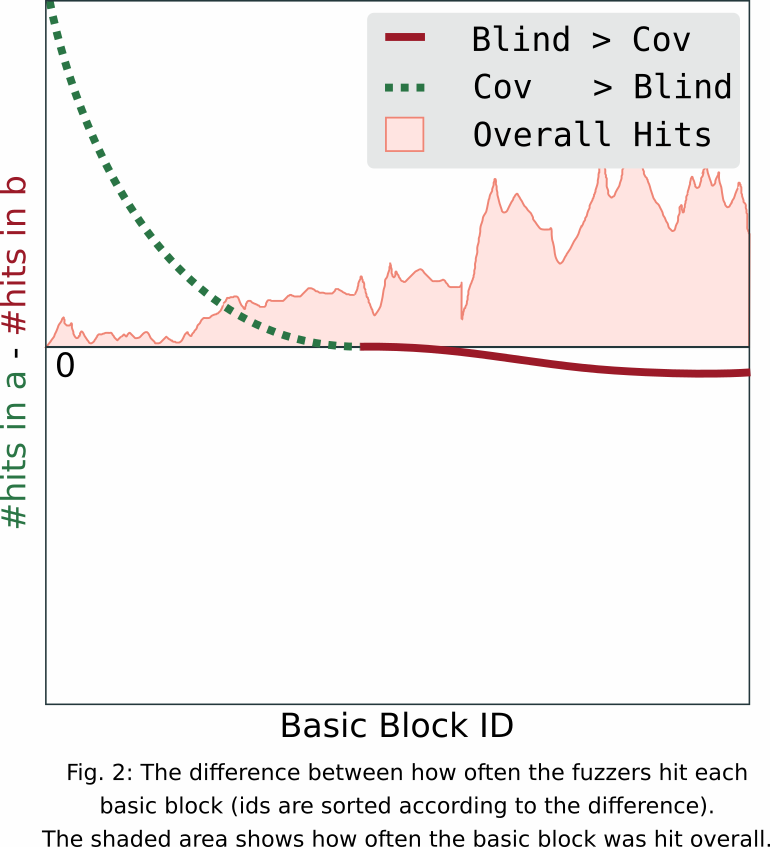
We considered two fuzzing executions, AFL and Honggfuzz on freetype2. Similar to this graph, the differences between hit counts of AFL and Hinggfuzz for each basic block are plotted. Also, the hit counts are represented on the same graph. The blue and green color dots represent hit_counts(AFL) and -hit_counts(Honggfuzz) for each basic block. Make sure that we have excluded all the basic blocks which had 0 hit counts from both the fuzzers.
To make the behavior much clearer, we transformed all the hit counts to log10 scale before computing the differences. We adjusted each hit count by adding +1 to make log transformation viable for all the data points. Essentially we have plotted log10(hit_counts_AFL) - log10(hit_counts_Hongfuzz). Blue and green dits are also in log10 scale. These results are also based on the data by Stephan Lipp (@sphl) of TU Munich.

mboehme
commented
4 years ago Thanks Danushka! Maybe I can add an interpretation.
We use the log10(hits) just because the scale is substantial. The X axis shows the basic block IDs ordered by log10(AFL_hits) - log10(Hongg_hits). The blue dots are log10(AFL_hits) and the green dots are -log10(Hongg_hits).
On the left, we can see BBs that AFL excutes about 1 order of magnitude more often. On the right, we can see BBs that Hongg executes about 10 order of magnitudes more often. In this example, Honggfuzz clearly executes more BBs and the majority of BBs several orders of magnitude more often than AFL.
eqv
commented
4 years ago Sweet! This is exactly the kind of plot I was thinking of! The differences between hongg fuzz and AFL are pretty big (in terms of coverage reached overall) but I think this neatly shows how almost all of the basic blocks where AFL is doing better than honggfuzz are also basic blocks that honggfuzz explores very thoroughly already. Are the datapoints sampled over the whole campaign or are they calculated from the queue?
mboehme
commented
4 years ago That's from the coverage profile generated by executing the entire queue at the end of the campaign.
eqv
commented
4 years ago hmm that means that early basic blocks will be under represented, as they are found in a few inputs, but where ran a lot of times. And basic blocks that were found later are over represented, as they were executed far less than the early ones, even though they both appear the same # times in the queue. Right?
eqv
commented
4 years ago Is there a way to access this data? I wonder if it would be helpful to display how often the losing fuzzer covered the same basic block. So you can easily tell the difference between 30_000 vs 40_0000 and 0 vs 10_000.
mboehme
commented
4 years ago Is there a way to access this data?
PR #778 is to generate that data in Fuzzbench.
I wonder if it would be helpful to display how often the losing fuzzer covered the same basic block. So you can easily tell the difference between 30_000 vs 40_0000 and 0 vs 10_000.
This should already be visible. For any BB where the line is below 0 (i.e., AFL is the losing fuzzer), blue indicates log10(hits + 1) for AFL.
dliyanage
commented
4 years ago Is there a way to access this data? I wonder if it would be helpful to display how often the losing fuzzer covered the same basic block. So you can easily tell the difference between 30_000 vs 40_0000 and 0 vs 10_000.
I think this would help. Say ntrials is the number of times a given BB hit at least once out of k runs. We plotted the ntrials(AFL)-ntrials(Hongg) along with ntrials(AFL) and -ntrails(Hongg) in the same graph. In data, there were k=20 runs for each fuzzer-subject combination. Same as above, blue and green dots represent AFL and Honggfuzz trials respectively.

eqv
commented
4 years ago This should already be visible. For any BB where the line is below 0 (i.e., AFL is the losing fuzzer), blue indicates log10(hits + 1) for AFL.
Yes, in theory that's true, but it's really hard to see - in general it seems like most basic blocks where AFL is better are also found by Honggfuzz many times, but imho we can't easily see if there is some basic blocks that are found significantly fewer times.
mboehme
commented
4 years ago That's log10(hits) sorted by Honggfuzz hits.

@eqv's idea Either 1: Capture a sample of inputs generated during fuzzing and then store path/state transitions that happen.