 evykassirer
commented
7 years ago
evykassirer
commented
7 years ago @hmaurer :
one benefit of tree positions would be that you don't actually modify the AST of an expression, you "point" at a node in the structure.
Open evykassirer opened 7 years ago
evykassirer
commented
7 years ago @hmaurer :
one benefit of tree positions would be that you don't actually modify the AST of an expression, you "point" at a node in the structure.
 hmaurer
commented
7 years ago
hmaurer
commented
7 years ago @evykassirer Also, tree positions are more general. Change groups are a subset of the cases where tree positions could be applied.
evykassirer
commented
7 years ago true! errors aren't really "changes" anyways
are there other cases you can think of in mathsteps where it'd be handy to use tree positions?
I guess a nodestatus would have a treePosition list of changed nodes then, yea?
hmaurer
commented
7 years ago @evykassirer yah that sounds right. I am not sure about other uses in mathsteps but on one of my pet projects, a first-order logic derivation engine, I used tree positions to "point" at a variable in an expression to get scoping information. For example, given forall x Px -> Q, if the user hovers "x" it will ask the engine where "x" is bound based on a tree position. e.g. getVariableInfo(variablePosition, expr).
 tkosan
commented
7 years ago
tkosan
commented
7 years ago Tree positions are also used in MathPiper to "point" to subexpressions in an expression. Some use cases include identifying a subexpression to highlight, locating the subexpression that was clicked on in a view of an expression, and identifying a subexpression to apply a rewrite rule too. Here are some additional examples that use tree positions:
Assign the above expression to the variable "tree".
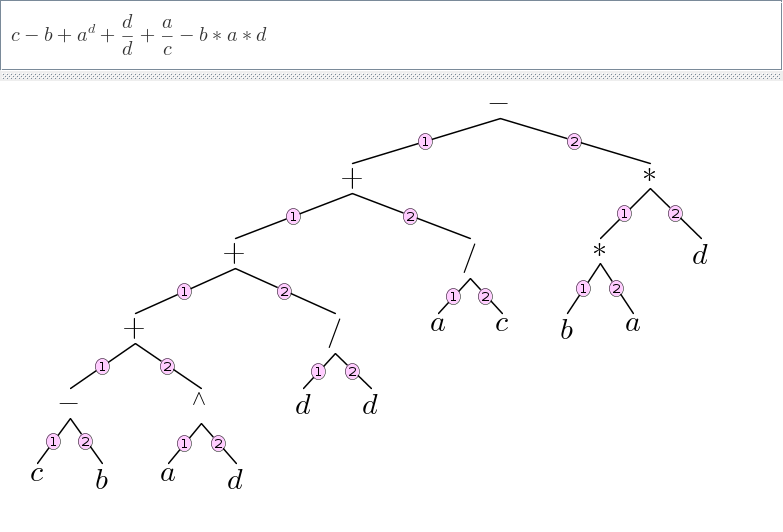
In> tree := '(c-b+a^d+d/d+a/c-b*a*d);
Result: ((((c - b) + a^d) + d/d) + a/c) - ((b*a)*d)Obtain the subexpression that is at position 1,2.
In> tree[1][2]
Result: a/cObtain the subexpression that is at position 1,1,1,2.
In> tree[1][1][1][2]
Result: a^dReturn the positions of all subexpressions that match a given pattern.
In> PositionsPattern(tree, x_/y_)
Result: ["1,2","1,1,2"]Substitute an expression for another expression at a specified position.
SubstitutePosition(tree, "1,1,2", x_/y_, "mathsteps rules!")
Result: ((((c - b) + a^d) + "mathsteps rules!") + a/c) - ((b*a)*d) kevinbarabash
commented
7 years ago
kevinbarabash
commented
7 years ago Something to note, both the current mathjs nodes and the proposed math-ast nodes have node specific properties which need to be referenced. In practice, using tree positions (or paths) would using strings (for properties) in addition to numbers (for arrays) to specify the location of a node in a tree, e.g. given:
{
type: "OperatorNode",
fn: "+",
name: "add",
args: [
{
type: "ConstantNode",
value: "1",
},
{
type: "ParenthesisNode",
content: {
type: "SymbolNode",
name: "x",
}
}
]
}The path to reference the SymbolNode representing "x" would be
["args", 1, "content"]@kevinbarabash that seems reasonable. @tkosan what do you think?
Edit: actually I am not sure. Consider x + (y + z). A path to y is a bit cleaner as[1, 0] than ["args", 1, "args", 0]. However the second one is more explicit; in the first case we attach an index implicitly to parts of the operator node.
evykassirer
commented
7 years ago "content" doesn't really have indices, but there's only one child so you could say "0"
I'd prefer to be explicit though, I think it's easier to read
kevinbarabash
commented
7 years ago @hmaurer I agree that using only indices are cleaner, but I don't think that's a viable option moving forward. As we add more functionality to mathsteps we'll have to deal with nodes that have named properties that we have to traverse. As an example, Number, as specified in math-ast (still a work in progress), has value and unit properties.
tkosan
commented
7 years ago @kevinbarabash tree positions aren't meant for accessing all of the detail that is in an AST. For example, tree positions can be used by teachers when teaching students about expression trees, and these conversations are at a higher level than how the tree is implemented in a given program. In the case of a Number, a tree position value would be able to identify its position in a tree, but since a Number is a leaf node, a tree position would not be used to go deeper into it. Can you provide an example of a node that is not a leaf node to illustrate your point?
tkosan
commented
7 years ago I meant to write "Can you provide an example of a node that is not a leaf node to illustrate your point that is not a ParenthesesNode?"
kevinbarabash
commented
7 years ago @tkosan I didn't realize that "tree positions" were something that would be communicated to users. I definitely wouldn't want to expose internals of the AST to users.
My understanding of change groups is that their main use is internal for referring to nodes within the tree. Since tree positions can't access all nodes in the AST it seems like they're not a good fit for replacing change groups.
To be clear, the current AST used by mathsteps doesn't have any nodes where tree positions aren't sufficient but over time I'm sure we'll be expanding the functionality of the AST to cover more math. Here are some examples for the current math-ast spec:
Number isn't always a leaf node. This is b/c it can have a unit which maybe a compound unit in which the units could be simplified, e.g.
(3 m) / (2 m/s) => 1.5 (m/(m/s)) => 1.5 sIn this example we'll need to reference the values of the numbers as well as their units to describe the changes.
Integral has left (bound), right (bound), and arg (expression being integrated) properties that need to be reference as part of a u substitution transform.
tkosan
commented
7 years ago @kevinbarabash
Numberisn't always a leaf node. This is b/c it can have a unit which maybe a compound unit in which the units could be simplified, e.g.
CASs usually relate values to units using a function or an operator so these parts of a tree can be manipulated by rewrite rules. For example, Mathematica uses a function named Quantity to indicate this relation, and Maxima's ezunits package uses the ` operator.
over time I'm sure we'll be expanding the functionality of the AST to cover more math
I think guidance on how to support expanding the functionality of the AST to cover more math is provided by Dijkstra's observation that there is no fundamental difference between mathematical expressions and computer programs:
It really helps to view a program as a formula. Firstly, it puts the programmer's task in the proper perspective: he has to derive that formula. Secondly, it explains why the world of mathematics all but ignored the programming challenge: programs were so much longer formulae than it was used to that it did not even recognize them as such. Now back to the programmer's job: he has to derive that formula, he has to derive that program. We know of only one reliable way of doing that, viz. by means of symbol manipulation.
In a computer, both math and code are processed by manipulating their tree forms. Rewrite rules are the main means that are used to accomplish this manipulation. Each rewrite rules contains a pattern that is used to determine if it matches any subtrees in a tree. If a rule's pattern matches a subtree, the subtree is replaced by the rule's body. For example, the following are some of the rewrite rules that define the + operator in MathPiper (<-- is the rewrite rule operator, its left operand is its pattern, its right operand is its body, and any variable in a pattern that has an _ appended to it matches any subtree):
x_Number? + y_Number? <-- AddN(x,y);
+x_ <-- x;
0 + x_ <-- x;
x_ + 0 <-- x;
x_ + n_Constant?*(x_) <-- (n+1)*x;
n_Constant?*(x_) + x_ <-- (n+1)*x;
x_ + - y_ <-- x-y;
x_ + (- y_)/(z_) <-- x-(y/z);
(- y_)/(z_) + x_ <-- x-(y/z);
(- x_) + y_ <-- y-x;
x_ + y_NegativeNumber? <-- x-(-y);
x_ + y_NegativeNumber? * z_ <-- x-((-y)*z);
x_ + (y_NegativeNumber?)/(z_) <-- x-((-y)/z);
(y_NegativeNumber?)/(z_) + x_ <-- x-((-y)/z);
(x_NegativeNumber?) + y_ <-- y-(-x);
n1_ / d_ + n2_ / d_ <-- (n1+n2)/d;
x_Number? + (y_Number? / z_Number?) <--(x*z+y)/z;
(y_Number? / z_Number?) + x_Number? <--(x*z+y)/z;
(x_Number? / v_Number?) + (y_Number? / z_Number?) <--(x*z+y*v)/(v*z);In CASs like MathPiper, not only is math defined by rewrite rules, the scripting language itself is also defined by rewrite rules (because there is no fundamental difference between math and code). For example, these are the rewrite rules that are used to define If and If/Else in MathPiper;
If(True) body_) <-- Eval(body);
(If(predicate_) body_ Else otherwise_)::(Eval(predicate) =? True) <-- Eval(body);
If(predicate_) body_ Else otherwise_)::(Eval(predicate) =? False) <-- Eval(otherwise);To a CAS, math functions such as Integrate are not treated any differently than code functions. For example, these are the top-level rewrite rules that define Integrate in MathPiper:
Integrate(var_) expr_ <-- IntSub(var, expr, AntiDeriv(var, IntClean(var, expr)))
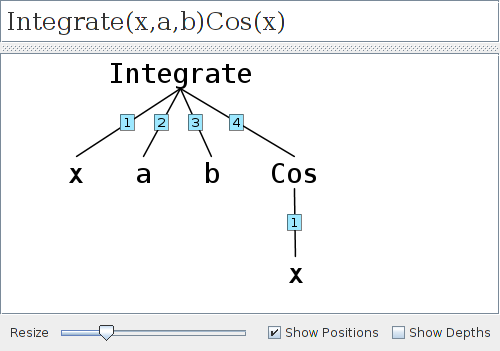
Integrate(var_, from_, to_) expr_ <-- defIntegrate(var, from, to, expr, 'a, 'b)The tree for Integrate(x,a,b) Cos(x) reflects the fact that from and to are treated as parameters instead of node-specific properties. Most CASs I am aware of use function parameters instead of special properties whenever possible because rewrite rule patterns are designed to use a tree's fundamental structure to find matches.
I suppose an argument can be made that since mathsteps implements rewrite rules with imperative code instead of with declarative rules, there is no need to support the use of declarative rewrite rules. However, since there is a desire for mathsteps to eventually support differentiation and integration, I think having support for declarative rewrite rules like the following would be helpful:
Differentiation rewrite rules
kevinbarabash
commented
7 years ago @tkosan thanks for the detailed response. My experience with ASTs is primarily with JavaScript ASTs so it's great to see how CASes structure things.
I like the idea of a Quantity node instead of including units in a Number.
I really like the succinct re-write rules. Being able to use the same syntax to define an AST chunk for matching makes a lot of sense. https://github.com/Khan/structuredJS does this for JavaScript ASTs so it's definitely possible with named properties and shouldn't be substantial different in implementation costs from positional children.
I would be interested in trying to support for rewrite rules to math-parser along with a matcher function in order to test out this hypothesis.
One big benefit I see from using named properties is that it's easier to understand the AST without having to look up which child corresponds to what.
{
type: 'Integral',
args: [
{ type: 'Identifier', name: 'x' },
{ type: 'Identifier', name: 'a' },
{ type: 'Identifier', name: 'b' },
{
type: 'Function',
name: 'cos',
args: [ { type: 'Identifier', name: 'x' } ],
}
]
}{
type: 'Integral',
variable: { type: 'Identifier', name: 'x' },
left: { type: 'Identifier', name: 'a' },
right: { type: 'Identifier', name: 'b' },
expression: {
type: 'Function',
name: 'cos',
args: [ { type: 'Identifier', name: 'x' } ],
}
}I didn't realize that "tree positions" were something that would be communicated to users. I definitely wouldn't want to expose internals of the AST to users.
I'd like to be able to use positions/changeGroups to highlight parts of expressions/equations that change in each step, or to highlight the part of the input that caused an error (like dividing by 0) -- as a pedagogical tool. Changegroups are already being used for this in Socratic's app.
Since tree positions can't access all nodes in the AST it seems like they're not a good fit for replacing change groups.
is this if we only use indices? it's possible if we use the param/index combination right?
Also, I do like the named indices. I personally find some of the CAS terminology/structure hard to follow, and want to prioritize the mathsteps code being easy to read/understand/contribute to (which I hope we're doing an okay job of so far). Having friendly code is a priority, even if it means we do things a little differently.
kevinbarabash
commented
7 years ago Using the param/index combo will allow us to reference any part of an AST that has named properties.
hmaurer
commented
7 years ago @kevinbarabash Yeah. The intent is different than tree positions but it would suit this project. Basically we are talking about pointers into a javascript object. Sounds good to me!
tkosan
commented
7 years ago @kevinbarabash
I really like the succinct re-write rules. Being able to use the same syntax to define an AST chunk for matching makes a lot of sense. https://github.com/Khan/structuredJS does this for JavaScript ASTs so it's definitely possible with named properties and shouldn't be substantial different in implementation costs from positional children.
I was excited to see that structuredJS implements a significant part of a full CAS-style pattern matcher. MathPiper's pattern matcher is based on a subset of the Wolfram Language pattern matcher (which provides a good example of what pattern matching is capable of). I also use pattern matching to assess student code when teaching beginners MathPiper. I think it would be useful to compare how pattern matching is used in MathPiper to assess student code with the way this is done in structuredJS to see what the similarities and differences are.
I would be interested in trying to support for rewrite rules to math-parser along with a matcher function in order to test out this hypothesis.
When the opportunity becomes available to do these tests, I am interested in helping because it is indeed easier to understand the AST if named properties are used instead of just arguments.
tkosan
commented
7 years ago @evykassirer
I personally find some of the CAS terminology/structure hard to follow
This is interesting because in #138 I just saw you create the following rewrite rules without even breaking a sweat:
(a/x + b/y) * (c + d) => (a*(c+d))/x + (b*(c+d))/y
(a + b/y) * (c + d) => a*(c+d) + (b*(c+d))/y
(a + b) * (c + d) => a*c + a*d + b*c + b*dIt only took about two minutes to convert these into executable rewrite rules (/: means "apply rules to an expression"):
rules := [
(a_/x_ + b_/y_) * (c_ + d_) <- (a*(c+d))/x + (b*(c+d))/y,
(a_ + b_/y_) * (c_ + d_) <- a*(c+d) + (b*(c+d))/y,
(a_ + b_) * (c_ + d_) <- a*c + a*d + b*c + b*d
];
Echo("1: ", '((m/n + o/p) * (q + r)) /: rules);
Echo("2: ", '((m + n/o) * (p + q)) /: rules);
Echo("3: ", '((m + n) * (o + p)) /: rules);
Echo("4: ", '((3 / x^2 + x / (x^2 + 3)) * (x^2 + 3)) /: rules);
Output:
1: (m*(q + r))/n + (o*(q + r))/p
2: m*(p + q) + (n*(p + q))/o
3: ((m*o + m*p) + n*o) + n*p
4: (3*(x^2 + 3))/x^2 + (x*(x^2 + 3))/(x^2 + 3)haha nice - sometimes it's hard to tell the difference between my finding something intimidating because I don't know it yet, and it actually being confusing
thanks for explaining that! I'd be open to playing around with changing how mathsteps applies rules, though I have a feeling that'd be a pretty bit change - is that true?
tkosan
commented
7 years ago @evykassirer
I'd be open to playing around with changing how mathsteps applies rules, though I have a feeling that'd be a pretty big change - is that true?
Yes, it would be a big change, but it might be possible to do it in phases with rewrite rules that are implemented imperatively (like they are now) being used alongside the CAS-style rewrite rules for awhile. However, before playing around with implementing CAS-style rewrite rules in mathsteps, it would probably be a good idea to play with them in a CAS a little bit to see if they are worth the effort.
I could put together a short tutorial on how to use rewrite rules in a CAS if anyone were interested in learning about them. I am confident that anyone who has worked on the mathsteps code would quickly grasp the material in the tutorial.
evykassirer
commented
7 years ago thanks Ted! sounds like a good idea
I'd love to see a tutorial - seems like a great resource in general anyways :)
 aelnaiem
commented
7 years ago
aelnaiem
commented
7 years ago Is transitioning to the param/index approach blocked by anything or can someone pick that up? Basically, I'm curious if this needs more discussion or if we can choose that approach going forward.
evykassirer
commented
7 years ago I don't think it's blocked! Unless it'd be a lot easier with the new parse tree and we want to wait for then
aelnaiem
commented
7 years ago Sounds great! Going to remove the tag :)
evykassirer
commented
7 years ago we might need discussion on how it's going to be implemented though (before someone jumps into it) since we haven't had any design discussion on how tree positions fits into the mathsteps data structures (I think)
{kind=link}
{kind=link}
This is blocked on #128 (new parser) because tree positions are based on what the tree looks like.
we use
changeGroupsright now to show what part of a tree has changed@tkosan:
tree positions have been brought up a few times, so let's discuss them more here - what are their pros/cons vs changeGroups?