 gorhill
commented
7 years ago
gorhill
commented
7 years ago Is this about the /g00 thing?
Closed gorhill closed 5 years ago
gorhill
commented
7 years ago Is this about the /g00 thing?
 ameshkov
commented
7 years ago
ameshkov
commented
7 years ago Yup
ameshkov
commented
7 years ago Any idea on how do they detect dev tools?
gorhill
commented
7 years ago Yup
Again in this case, I don't see the point of secrecy, the /g00 stuff is being currently used in production, so it's not like we are trying to prevent a work around blockers, they are already being worked around. That HTML/CSS/JS code is all open to scrutiny by anybody, so there is no privileged information to protect really.
Any idea on how do they detect dev tools?
Yes: https://www.reddit.com/r/firefox/comments/5gtedd/ublock_origin_developer_raymond_hill_on/dav4iiu/
ameshkov
commented
7 years ago Thumbs up, nice technique!
gorhill
commented
7 years ago Proposed network filter syntax extension: **[...]{...} -- two-asterisk syntax.
The ** sequence tells the filter parser that a regex-valid character class follows -- and optionally a regex-valid quantifier.
The [...] part would be a regex-valid character class specifier.
The {...} is optional. If present, passed as is to the regex constructor, i.e. it would be a regex-valid quantifier. If not present, the "zero or more" * quantifier will be used.
What it solves: better matching accuracy without having to resort to inefficient regex-based filter -- thus no issue with tokenizing the filter. Benefits of both plain filter syntax and regex-based syntax without their liabilities.
Example, an abused exception filter found in EasyList:
@@||nowdownload.*/banner.php?$script,domain=~calcalist.co.il|~gaytube.com|~mako.co.il|~pornhub.com|~redtube.com|~redtube.com.br|~tube8.com|~tube8.es|~tube8.fr|~walla.co.il|~xtube.com|~ynet.co.il|~youjizz.com|~youporn.com|~youporngay.comWith the new syntax, it can't be abused anymore (showing more than one variation to highlight flexibility):
@@||nowdownload.**[a-z]/banner.php?$script
@@||nowdownload.**[a-z]{2}/banner.php?$script
@@||nowdownload.**[a-z]{2,3}/banner.php?$script
@@||nowdownload.**[^/?#]/banner.php?$scriptThis is a real case example, and currently the proposed solution means there would no longer be a need to create an exclusion list for where the filter should not apply (pornhub et al. have been abusing it, along other such similar filters).
Efficiency: the more specific a regex the more efficiently it executes. The * syntax is commonly used and it means "matches anything in any number". The ability for filter list maintainer to be more accurate in describing what is to be expected can lead to more efficient regexes internally.
For example:
/site=*/size=*/viewid=Let's say that the * were supposed to match some random sequence of digits. Of course whoever created the filter was not going to use a regex for such filter -- because they are rightfully frowned upon. On the other hand, the matching-anything-in-any-number semantic of the asterisk means that an inefficient regex must be used internally, one that will scan the whole URL to match. With the proposed syntax:
/site=**[\d]/size=**[\d]/viewid=This is a much more efficient filter, as the regex execution will bail out of matching as soon as no digit is found at the placeholder locations. This gives the filter list maintainers the ability to be more accurate in describing what the filter should match, without resorting to full blown regex-based filters.
A nice-to-have side effect for filter list maintainers: ability to specify a sequence of character with no instances of specific characters in it, i.e. the [^...] regex syntax.
A filter parser would just need to have a special code path in case a filter is found to contains an instance of double asterisk, to extract and validate the sequence **[...]{...} and transpose into the proper regex equivalent sequence, or if it does not validate, just fall back on the normal single asterisk semantic for the sequence.
This does not mean all instances of * would need to be replaced, it's merely a new syntax which would become available to filter list maintainers to make their work easier/simpler.
ameshkov
commented
7 years ago Sorry for the late reply, I've just got a free minute to think about it in silence:)
ameshkov
commented
7 years ago @gorhill you know, it looks very much like your token suggestion.
Comparing with the regular regexp rules:
As I see it, the problem is that filters maintainers generally don't care about performance. One more regex rule would do no harm, so they will continue to use them.
Frankly, I suppose we should make engines smarter instead of providing more and more syntax sugar to maintainers.
Examples:
||nowdownload.*/ - we can detect, that nowdownload.* is the domain name, so we can compile a more effective regexp.Regarding point 1, we did implement it in the latest version. I guess we need some time to see how it goes and is there any problem with token extraction.
 kzar
commented
7 years ago
kzar
commented
7 years ago We're supporting the $webrtc filter option / request type now as well, here's the blog post and here's the implementation. We also do this by wrapping RTCPeerConnection but our implementations have some differences, most notably that instances without any URLs are not listed. Sorry I meant to post here earlier but forgot!
Edit: Oh, and I also filed Chromium issue 707683 asking for proper support to be added for the blocking of WebRTC connections.
gorhill
commented
7 years ago @kzar Thanks for the head up. I do follow the issue tracker of ABP, so I was aware of this. I have been thinking of I how would implement this in uBO, but I will definitely avoid using a wrapper in uBO on my side, at least an unconditional one -- I consider this too risky, and in the event it causes an unforeseen issue, a user would be forced to disable the whole extension itself.
There is such a wrapper for uBO-Extra, and issues have been reported, see https://github.com/gorhill/uBO-Extra/issues -- you may want to use these as test cases. Having to disable a small companion extension is much less worst than having to disable the whole blocker.
Regarding https://bugs.chromium.org/p/chromium/issues/detail?id=707683, another approach is to have a content security policy directive for WevRTC connections, currently there is nothing to prevent these, a rather big hole in the CSP standard. See https://github.com/w3c/webappsec-csp/issues/92.
ameshkov
commented
7 years ago On the other hand, there's not much can be done about WebRTC circumvention. Either wrap it or use the scripts injections approach which ABP does not support.
but I will definitely avoid using a wrapper in uBO on my side, at least an unconditional one
Actually, there is a way to override WS/WebRTC "conditionally". We've found a way to execute dynamic script injections before the pages' code. Not a 100% guarantee yet, though, but the first tests show that it works.
Wait a bit, I'll link you an example.
ameshkov
commented
7 years ago The "fastest" way to perform a dynamic script injection is to use the onCommitted listener. Once it fires, send a message with the scripts directly to the frame and handle it in the content script. It appears, that the message is received by the content script before the page scripts are executed.
Problems:
gorhill
commented
7 years ago @ameshkov That is an interesting idea. On my side I was planning to maybe use a cookie to conditionally execute such content script code:
Not pretty and potentially have its own edge issues -- aside the added overhead.
The problem with executeScript and insertCSS, is that they are not well defined, and main chrome API statement...
Unless the doc says otherwise, methods in the chrome.* APIs are asynchronous: they return immediately, without waiting for the operation to finish
... really get its the way of reliability for the current case.
This suggests that tabs.executeScript (and also tabs.insertCSS) cannot be reliably injected in a tab/frame. The fact that these methods accept a run_at option makes all this the more ambiguous -- what is the point of using document_start if there is no guarantee that the script or CSS will be injected before any CSS or script has be executed on the page?
From the documentation, one can even imagine that a script/CSS injected through these methods could potentially end up being injected in a completely different tab/frame than originally intended (what happens when there is a quick redirect?). I consider this a flaw in the API.
If the documentation could explicitly guarantee that your approach will always work (i.e. the script/CSS is injected in a synchronous manner and onCommitted can be blocking), that would be great -- it actually make sense given when webNavigation.onCommitted is fired:
Fired when a navigation is committed. The document (and the resources it refers to, such as images and subframes) might still be downloading, but at least part of the document has been received
But then again, the way this is phrased, it's as if onCommitted could be fired after things are farther than just right after the document was created ("might").
ameshkov
commented
7 years ago @gorhill nice catch with a cookie, I like it! What's good is that this is a true cross-browser solution (taking into account the MS Edge limitations).
The problem with executeScript and insertCSS, is that they are not well defined, and main chrome API statement...
As I understand, tabs.executeScript is out of the question anyway, as it executes a content script, not an in-page script: https://developer.mozilla.org/en-US/Add-ons/WebExtensions/API/tabs/executeScript
edit: ignore it, obviously the content script can inject the in-page wrapper.
If the documentation could explicitly guarantee that your approach will always work (i.e. the script/CSS is injected in a synchronous manner and onCommitted can be blocking)
I don't think it can, we'll have to keep an eye on its behavior, and that's the problem indeed.
@gorhill @kzar Whichever approach is used, I suppose we need a common rules syntax for disabling this kind of wrappers.
I suggest introducing this type of rules:
@@*$websocket,domain=example.org -- to disable websocket wrapper
@@*$webrtc,domain=example.org -- to disable RTC wrapper
Thoughts?
kzar
commented
7 years ago The idea of conditionally running content scripts is certainly interesting, and not something I considered. Copying in @snoack since he might be interested in your ideas there too.
I think in the case of these wrappers however we'll stick with executing them consistently. IMO it's better to "just" get the wrapper right in the first place, and multiple code paths make debugging harder. It's good for you guys I suppose, after the next Adblock Plus release lands we'll find out the hard way if there are any problems, if not you can use the code too :stuck_out_tongue:.
ameshkov
commented
7 years ago Guys, I've just stumbled upon a new circumvention practice.
I guess @kzar is aware of it, not sure about @gorhill:
if (window.document) {
if (window.adonisContext)
return window.adonisContext;
var e, n = document.createElement("iframe");
return n.src = "https://nop.xpanama.net/if.html?adflag=1&cb=" + i(),
n.setAttribute("style", "display: none;"),
document.body.appendChild(n),
e = n.contentWindow,
n.contentWindow.stop(),
window.adonisContext = e,
e
}
return windowIt seems that n.contentWindow.stop(), prevents the content script from doing its job. Also, with a real URL in the src they are able to bypass CSP restrictions (http:). I guess the straightforward solution would be to override document.createElement and document.__proto__.createElement
gorhill
commented
7 years ago See https://github.com/uBlockOrigin/uAssets/issues/190#issuecomment-300897354.
My underfstanding , they can call n.contentWindow.stop() because at that point the iframe is about:blank (this is what chrome://webrtc-internals/ shows), which is treated in a special way by CSP engine (it always inherit embedding document's CSP). I realized yesterday it was not obvious how to disallow about:blank specifically without disallowing too much. However, in the end, frame-src http://*/* https://*/* worked (because there is no path in about:blank).
ameshkov
commented
7 years ago I start thinking we need some kind of a $csp modifier able to set custom content security policy for an URL.
For instance:
||example.org^$csp="frame-src self"
It's crucial, though, that it should only strengthen existing policy. Which is easy to achieve if we'd add an additional CSP header.
Thoughts?
gorhill
commented
7 years ago For instance:
||example.org^$csp="frame-src self"
This is pretty much what I implemented on my side (csp=..., not committed yet), except without the quotes (no need). This allows to inject whatever CSP policy we want, while never ever relaxing existing ones (when appended using ,).
ameshkov
commented
7 years ago This is pretty much what I implemented on my side (not committed yet), except without the quotes (no need)
We'd like to support it on our side as well, let's have a common syntax for this kind of rules then.
Why no quotes btw? It'll make it much harder to parse a rule with more than one modifier. For instance, subdocument and third-party might be used along with this one (in theory, but anyway).
ameshkov
commented
7 years ago Ok, it seems that I am wrong, CSP instructions cannot contain a comma, so it should be relatively easy to parse something like ||example.org^$csp=policy,subdocument,domain=example.com
Are you planning to support additional modifiers in this type of rules?
gorhill
commented
7 years ago CSP instructions cannot contain a comma
Yes, that's the reason I chose to leave out quotes. The comma can be used to combine CSP policies, but I rather never have them used in filter options -- fits nicely with existing use of comma to separate filter options.
The nice thing with comma to separate distinct sets of policies when combined with existing CSP policies is that it won't cause spurious CSP reports, each comma-separated set gets its own report policy.
Currently all the following modifiers are supported when used with csp=: third-party, domain=, important, badfilter.
Additionally, exception filters for csp= can be crafted two ways:
csp= match, i.e. @@||example.com/nice$csp=frame-src 'none' will cancel only whatever filter tries to inject exactly a csp=frame-src 'none' filter, but not a csp=frame-src 'self' filter; OR@@...$csp will cancel all CSP injection for URLs which match the filter.All this required refactoring on my side, as the semantic for csp= filters is that all matching filters must be found (and furthermore applied according to important and @@), while normal filters only the first hit is returned.
ameshkov
commented
7 years ago The nice thing with comma to separate distinct sets of policies when combined with existing CSP policies is that it won't cause spurious CSP reports, each comma-separated set gets its own report policy.
Isn't it the same in the case of an additional CSP header?
ameshkov
commented
7 years ago @gorhill overall, I love the idea and the features you want it to have.
I've come up with a formal description of the csp modifier:
https://github.com/AdguardTeam/AdguardBrowserExtension/issues/685
Could you please check are we on the same page?
gorhill
commented
7 years ago Isn't it the same in the case of an additional CSP header?
I guess it is the same, however I prefer to append to existing CSP header because of this passage in documentation:
A server MUST NOT send more than one HTTP header field named
Content-Security-Policywith a given resource representation.A server MAY send different
Content-Security-Policyheader field values with different representations of the same resource or with different resources.
I have a bit of a problem parsing the meaning of this, so I went with what I thought was the safest approach, which is to append and use comma as separator.
kzar
commented
7 years ago The $csp filter option is an interesting idea, I've opened issue 5241 to start a discussion with Wladimir and Sebastian about adding it to Adblock Plus as well.
ameshkov
commented
7 years ago @kzar 👍
ameshkov
commented
7 years ago I guess it is the same, however I prefer to append to existing CSP header because of this passage in documentation:
Huh, I wonder what this resource representation thing means. For instance, dropbox.com sends two CSP headers:
content-security-policy: script-src 'unsafe-eval' https://www.dropbox.com/static/compiled/js/ https://www.dropbox.com/static/javascript/ https://www.dropbox.com/static/api/ https://cfl.dropboxstatic.com/static/compiled/js/ https://www.dropboxstatic.com/static/compiled/js/ https://cfl.dropboxstatic.com/static/previews/ https://www.dropboxstatic.com/static/previews/ https://cfl.dropboxstatic.com/static/javascript/ https://www.dropboxstatic.com/static/javascript/ https://cfl.dropboxstatic.com/static/api/ https://www.dropboxstatic.com/static/api/ 'unsafe-inline' 'nonce-bKDizX/Kbtm0495WF9jC' ; default-src 'none' ; worker-src https://www.dropbox.com/static/serviceworker/ blob: ; style-src https://* 'unsafe-inline' 'unsafe-eval' ; connect-src https://* ws://127.0.0.1:*/ws ; child-src https://www.dropbox.com/static/serviceworker/ blob: ; form-action 'self' https://dl-web.dropbox.com/ https://photos.dropbox.com/ https://accounts.google.com/ https://api.login.yahoo.com/ https://login.yahoo.com/ ; base-uri 'self' api-stream.dropbox.com showbox-tr.dropbox.com ; img-src https://* data: blob: ; frame-src https://* carousel://* dbapi-6://* dbapi-7://* dbapi-8://* itms-apps://* itms-appss://* ; object-src https://cfl.dropboxstatic.com/static/ https://www.dropboxstatic.com/static/ 'self' https://flash.dropboxstatic.com https://swf.dropboxstatic.com https://dbxlocal.dropboxstatic.com ; media-src https://* blob: ; font-src https://* data:
content-security-policy: script-src 'nonce-bKDizX/Kbtm0495WF9jC' 'nonce-wTJ0bGY/hQQlxU0EVOpm' 'unsafe-eval' 'strict-dynamic'edit: asked a question: https://github.com/w3c/webappsec-csp/issues/215
ameshkov
commented
7 years ago So, after all:
gorhill
commented
7 years ago @mapx-, @kzar
About https://issues.adblockplus.org/ticket/5291, what I don't see being done in the comment is:
Yes, I have seen ABP grow to past 340 MB, and even leaving the browser on idle did not cause the memory to be garbage-collected. However, after accomplishing the above steps, there was memory being garbage-collected, and the memory snapped back to expected levels (keeping in mind fragmentation, js engine internals, etc.).
Any report of high memory usage should always be done after the steps above, including the equivalent ones on Firefox.
kzar
commented
7 years ago Thanks that's a good tip, I will give it a try. It's just weird (to me at least) that garbage collection is not happening automatically. We can hardly expect users to trigger it manually :(
 hemantgoyal
commented
7 years ago
hemantgoyal
commented
7 years ago Why does the chrome store say it is corrupted now ? :(
 bershan2
commented
7 years ago
bershan2
commented
7 years ago @hemantgoyal That is a Chrome hash function bug. See https://github.com/gorhill/uBlock/issues/2720 (already fixed with a bit of padding).
gorhill
commented
6 years ago  mapx-
commented
6 years ago ameshkov
commented
6 years ago
mapx-
commented
6 years ago ameshkov
commented
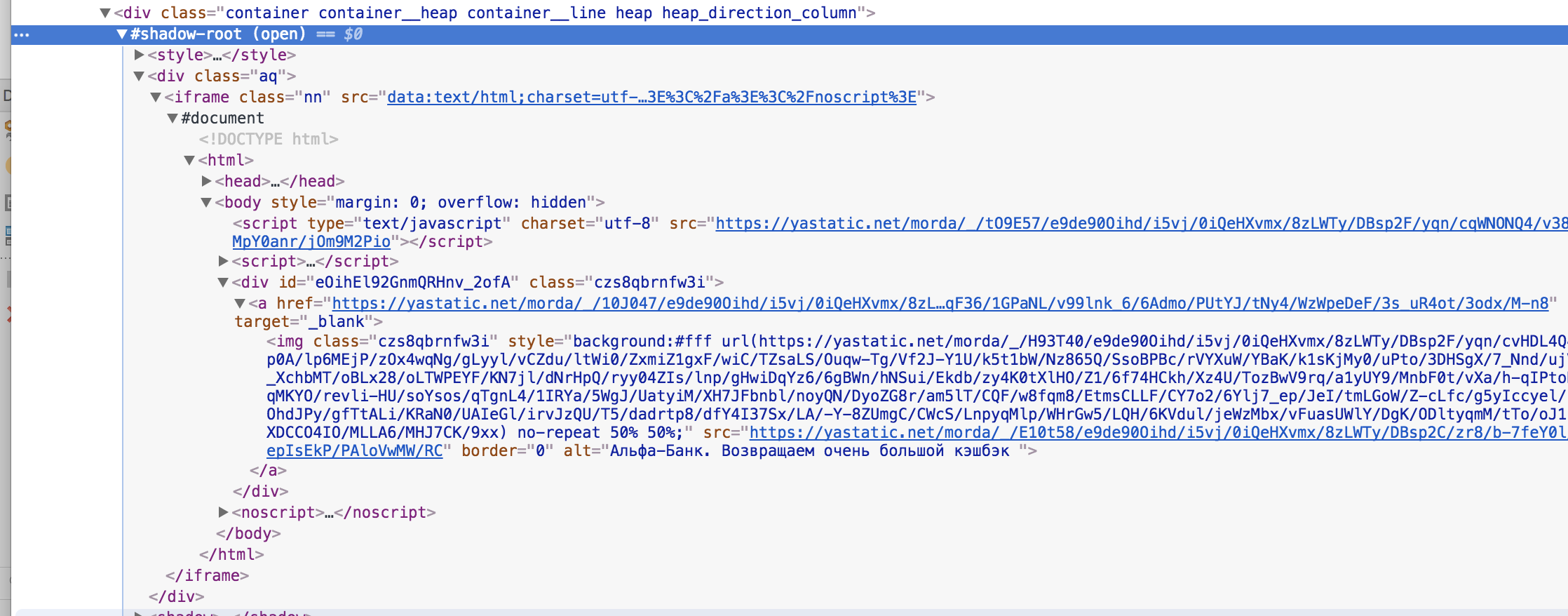
6 years ago Hey guys, I've recently stumbled upon an interesting adblocking circumvention technique used by Yandex.
The thing is that they use shadow DOM to circumvent element hiding rules: https://uploads.adguard.com/up04_5pkb0_Yandeks.png
The open root is used in the screenshot so we can get inside with a /deep/, and when a closed root is used, /deep/ cannot help us. Anyway, all the shadow piercing selectors are deprecated and will be eventually removed so we have a problem here.
Possible solution (rather ugly though):
::shadow pseudo-selector to pierce inside open roots.attachShadow and force all shadow roots to be open.Have you already faced anything like that? Thoughts?
mapx-
commented
6 years ago @ameshkov I added you here: https://issues.adblockplus.org/ticket/5318 and https://issues.adblockplus.org/ticket/5302
perhaps it's about the same yandex stuff
ameshkov
commented
6 years ago @mapx- thank you! Yeah, it's been a while since they began their crusade and both issues are relevant.
What bothers me is that the "closed shadow root" approach seems to be a universal way to avoid elements hiding and even user stylesheets won't help us defeat it once Chrome stops supporting /deep/ and ::shadow.
gorhill
commented
6 years ago The /deep/ issue has been raised before. It's being deprecated as a valid CSS selector component in a CSS rule, but will still be valid as a CSS selector in querySelector[All] call. My understanding.
So currently, not an issue with Firefox I presume (does not support shadow stuff yet). An issue with Chrome, but can be worked around by manually hiding through querySelectorAll.
ameshkov
commented
6 years ago @gorhill
So currently, not an issue with Firefox I presume (does not support shadow stuff yet). An issue with Chrome, but can be worked around by manually hiding through querySelectorAll.
That's basically what I meant -- support either shadow or /deep/ "polyfills" just like we do with :has.
Good news is that /deep/ is able to pierce inside closed shadow roots so my the second point in my comment is redundant.
gorhill
commented
6 years ago just like we do with
:has.
I just realized we can probably already just use :has for filter with /deep/?
example.com##div.container:has(/deep/ .aq)Would this work now?
ameshkov
commented
6 years ago I just realized we can probably already just use :has for filter with /deep/?
We don't yet support it (but we definitely will), but this is a partial solution anyway.
For instance, in Yandex case they shadow contains legit elements as well so we need something like example.org##div /deep/ span:has(.banner)
gorhill
commented
6 years ago @ameshkov
The "fastest" way to perform a dynamic script injection is to use the onCommitted listener
I'm experimenting with this and this works fine so far on both Chromium and Firefox. I see 10-20ms gain in how earlier the scriptlets are injected (using tabs.executeScript), though when I measure with the number of scripts already handled (document.scripts.length), I can't see gain so far for the little I have tested.
Anyway, I want to ask why did you chose to go through messaging to inject the scriptlets rather than injecting directly using tabs.executeScript?
ameshkov
commented
6 years ago @gorhill
Anyway, I want to ask why did you chose to go through messaging to inject the scriptlets rather than injecting directly using tabs.executeScript?
As I recall, we compared both and didn't see any serious difference. Actually, in future updates, we'll migrate to tabs.insertCSS in light of the coming user-agent styles priority improvement.
 mjethani
commented
6 years ago
mjethani
commented
6 years ago @ameshkov regarding Shadow DOM, we have user style sheets in Chromium now (works on Canary) along with the cssOrigin option to tabs.insertCSS. I'm also working on allowing extensions to access closed shadow roots. We should be in a good place soon.
ameshkov
commented
6 years ago Hi @mjethani! I'm actually keeping an eye on all the pull requests you're pushing to Chromium, and you're doing a great job, thank you!
ameshkov
commented
6 years ago Hey guys, coming at you with a new modifier idea: https://github.com/AdguardTeam/AdguardBrowserExtension/issues/961
I suppose it can benefit all the privacy-oriented subscriptions so we're planning to implement it in one of the future updates.
gorhill
commented
6 years ago @ameshkov I don't see that much privacy value in dealing with cookies alone given that data can be stored in other local storage such as localStorage, indexedDB, etc.Blocking 3rd-party cookies in browser settings should be the first step for any privacy conscious person -- this also takes care of all local storages.
ameshkov
commented
6 years ago Extending this modifier to handle localStorage sounds useful indeed, and it can be done without changing the modifier syntax.
However, I've never seen indexedDB used for tracking purpose.
{kind=link}
[Intentionally empty]