 nus-pe-script
commented
6 months ago
nus-pe-script
commented
6 months ago Team's Response
While we understand and sympathize that the ID is hard to type, it's unfortunately nessecary for the amount of different generation results that can happen.
The logic behind this is that each problem set generated for the first time will be assigned a random signed integer as their ID, each unique ID is supposed to represent a unique set of problems. Which means if the range of the numbers are extremely small, say -100 to 100. It's very easy to encounter a "hash collision", meaning two different sets having the same ID.
A solution to this would be to assign small numbers in increasing order as we encounter new equations, but this would mean we have to map each set to a specific number and search the "dictionary" for a match each time a new set is generated, and on repeated uses with huge amount of records, this can potentially slow down the program significantly and hinder the user experience even more.
A better solution may exist, but it will have to be reserved for a future version.
Also, copy and pasting is viable and recommended for this command.
Items for the Tester to Verify
:question: Issue response
Team chose [response.NotInScope]
- [x] I disagree
Reason for disagreement: Dev team did not prove that flaw is not in scope as they did not highlight in their UG that a fix in this flaw would coming in future versions.
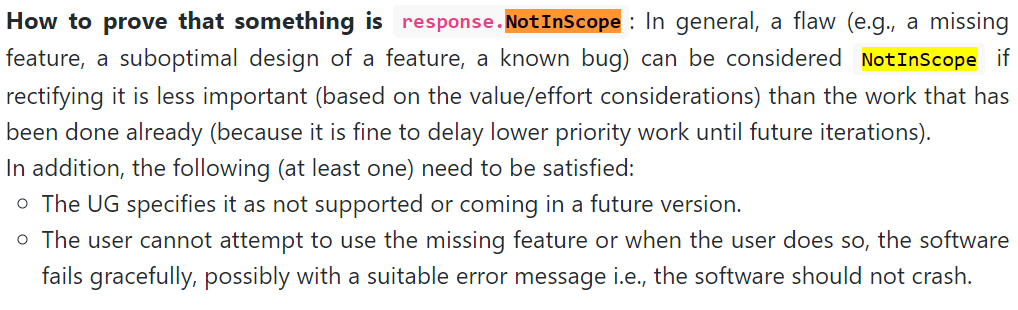

They did not recommend to use ctrl-c in their UG. Furthermore, using ctrl-c would also slow down the user as commands are meant to be easy to type, not easy to copy paste.

Not user friendly to input such a long id number to retry. As shown in the course admin info below