 abadams
commented
2 years ago
abadams
commented
2 years ago A bump allocator is difficult because there might be a parallel CPU loop outside the GPU kernel launch. Something we've talked about for a while is the ability to preallocate all resources at various scopes with an "allocation plan". It's a tricky thing to get right though due to overlapping lifetimes and such. In the short term, do you know why the built-in caching allocator is still allocating? For most of my pipelines it removes allocations entirely in the steady state. Maybe there's a threshold that needs tuning or some knobs to expose.
 mcourteaux
mcourteaux Overall performance of application is around 20% faster I think. :smile:
Overall performance of application is around 20% faster I think. :smile:
TLDR: CUDA memory API is slow, and Halide allocates and frees all intermediate buffers on the fly within the pipeline. Hence, buffer reuse is not in my control. Envisioned elegant solution: have a bump allocator argument for an AOT-compiled pipeline that will be used for all intermediate results. I think this would benefit most targets actually, as bump allocators seem perfect for this purpose of a single pipeline run. This way, I can reuse the bump allocator for sequential pipeline runs, as long as I made sure the capacity is large enough.
What are your thoughts? As this will impact my research directly, I'm considering working on this, but I would like to gather some thoughts first. Some things I am wondering:
Feature::bump_allocator?Currently, I think the idea of making a target-feature to generate the pipeline seems the most appealing, overall, as it would just add one argument to the generated function signature, that takes in the bump allocator.
The story of how I got here (feel free to skip):
I'm still optimizing my PhD software in Halide. Currently, a lot of time is wasted on allocations through
cuMemAllocand especiallycuMemFree. Ideally, I have a situation where only once in the beginning allocations are done, and once in the end frees are done.The reason is that my pipeline first selects a number of components it will consider, and then runs all the other pipeline elements using those selected elements. Thus, the number of selected elements is variable from run to run. This causes a lot of buffers of different sizes to be required. So, ideally, I want to have a no allocations, but just use one giant memory region that can fit the worst case scenario worth of buffers.
I investigated in Halide, and there is an option to use
halide_reuse_device_allocations(nullptr, true);, which already improved things a little. Next, I did tricks like this:.align_storage(k, 512)to make sure Halide takes multiples of 512, heavily increasing the buffer reuse possibilities and decreasing fragmentation in the Halide-internal device-memory allocator. This reduced memory allocations/frees by a lot (I guess 70%). But still, there are a whole bunch of them left, which do take up time.For some reason (I'm not familiar with CUDA), the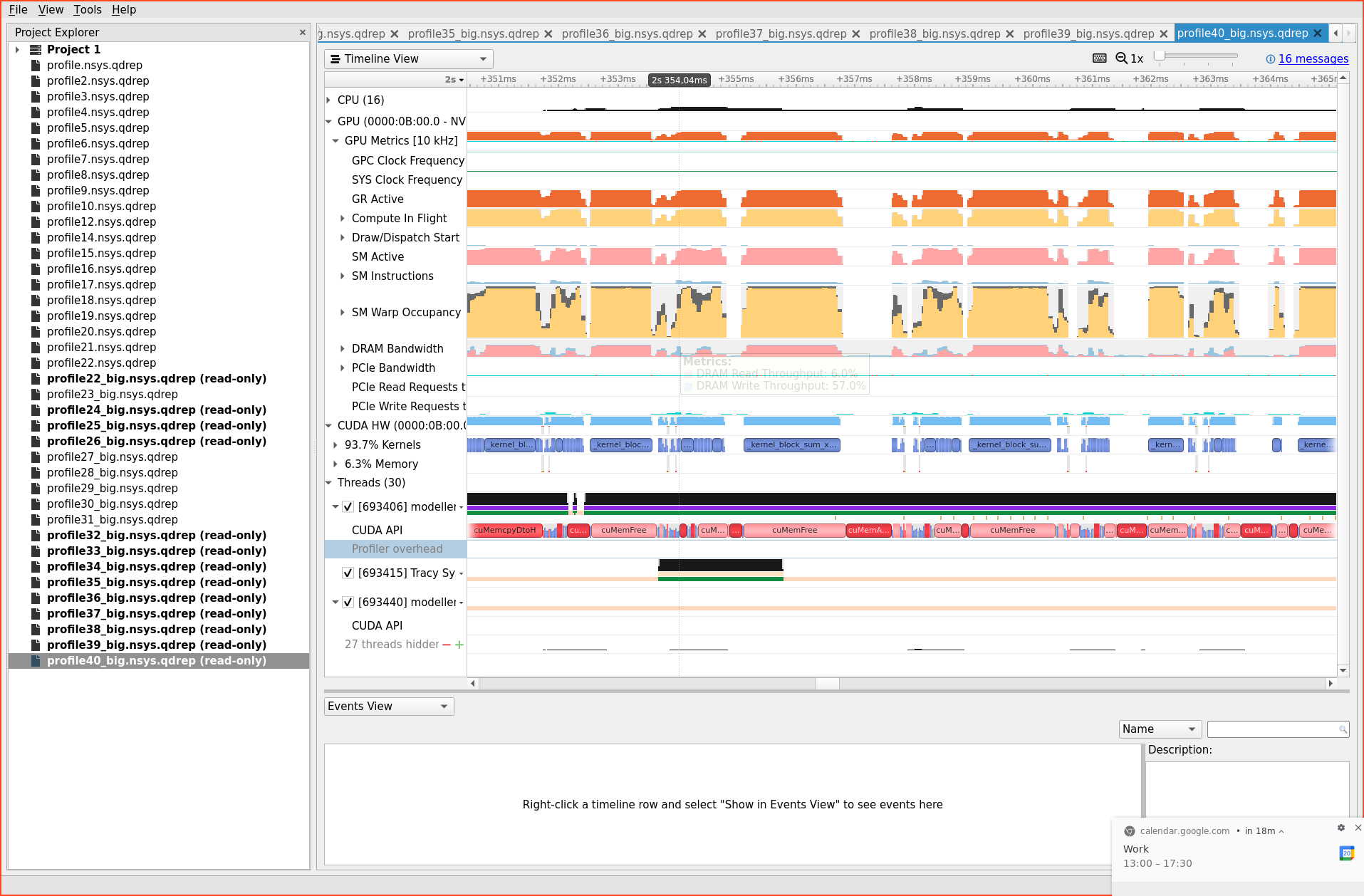
cuMemFreeis synchronous at API level, as can be seen in this screenshot from the performance profiler:In this screenshot, all of the time the GPU is not working, is because it is waiting and synchronizing on memory operations.
Thinking about this, I came to the conclusion that the problem lies in the fact that Halide allocates and frees all intermediate memory buffers in the pipeline itself. Halide does an effort to compute the required buffer sizes in the pipeline, which is nice, as it can use this size to allocate nicely the required amount of memory for each buffer. However, this allocation could instead happen on a bump allocator, which already has a large on-device buffer ready. This will yield instantaneous allocations, instead of waiting on
cuMemAllocandcuMemFreeand wasted compute time, like the screenshot about.In the end, the bump allocator just resets at the end of the pipeline (or alternatively at the beginning?). It then is the programmers responsibility to make sure your bump-allocator capacity is big enough to provide for all the required intermediate buffers the Halide pipeline will need.