 learning-chip
commented
8 months ago
learning-chip
commented
8 months ago For the simplest Jacobi decoding mask (like below), xformers support such a LowerTriangularFromBottomRightMask shape
(BTW, the BlockDiagonalMask can also help with static batching without padding)
 shermansiu
shermansiu xinlong-yang
xinlong-yang
{kind=link}
{kind=link}
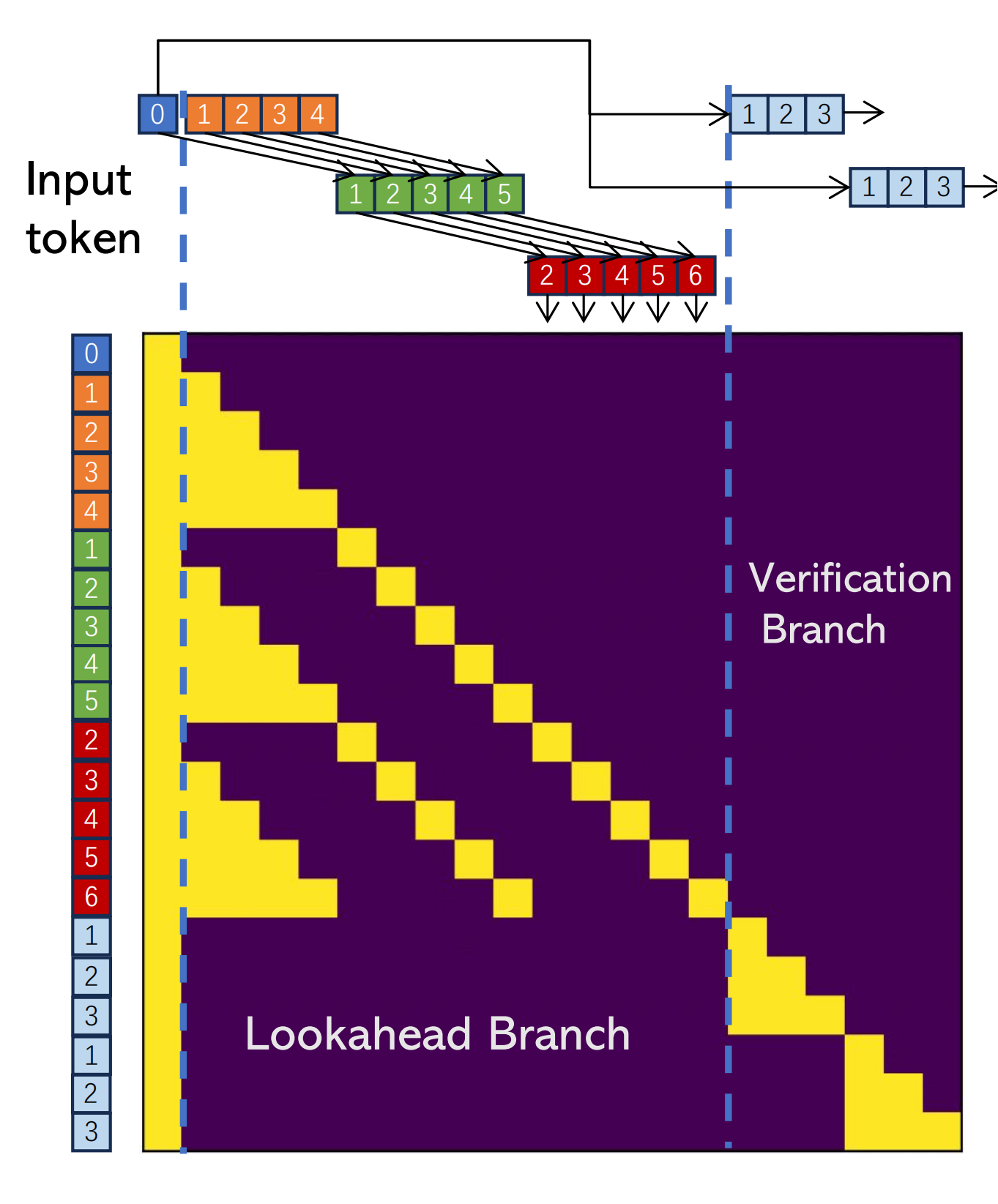
I have some questions about the structure of custom mask for lookahead and verify branches as described in the blog.
Related code
The
combined_attention_maskcreated byj_prepare_decoder_attention_mask(): https://github.com/hao-ai-lab/LookaheadDecoding/blob/b756db313419298d292a927c6dda950020ec1073/lade/models/llama.py#L201-L203Such attention mask is then sent to the decode layer, in order to compute all branches in a single
model.forwardcall:https://github.com/hao-ai-lab/LookaheadDecoding/blob/b756db313419298d292a927c6dda950020ec1073/lade/models/llama.py#L234-L236
1. Token dependency in lookahead branches
For the upper-left corner (blue-0 and orange-1,2,3,4):
I can understand that it is the Jacobi iteration (screenshot from this paper):
where each token in the current guess is updated concurrently, based on the current values. The input is a 5-token guess (in this figure), and the output is the updated 5-token guess. The input-output dependency is a normal triangular (casual) mask.
What I don't fully understand, is the green and red branches:
For example:
So why does each output token depend more on cross-iteration tokens, not in-iteration tokens? For example:
This is only about the model.forward computation part, not yet touching the N-gram cache management logic (that is in the
greedy_search()level, above themodel.forward()level). Thus this part should fall within the Jacobi decoding framework -- which shouldn't have cross iteration dependencies? (step-t state is computed from step t-1, but not t-2 or earlier)2. Past tokens (KV cache) and ways to call fused operators
The blog's mask omits the past token history. The actual, full attention mask sent to
LlamaAttention.forward()should look like this?The middle yellow block has KV-cache available (
past_key_values). The left padding block is the optional left-padding if used in static batching settings, to pad to the longest prompt length. The right block (shown in the original blog) deals with the newly-constructed queries (concats all branches), and no KV cache available.So what would be the proper way to call fused FlashAttention operator for such a mask pattern? The triton version of FlashAttention supports custom attention bias -- setting bias to
-infaccording to the mask pattern should have the desired mask effect? Has anyone checked the performance gain?