 apparentlymart
commented
8 years ago
apparentlymart
commented
8 years ago @phinze this proposal brings together several discussions we've had elsewhere and provides a new take on the "static vs. dynamic" problem that seems to be a common theme in Terraform supporting more complex use-cases.
I'd love to work on something in this vein early next year if you guys think this is a reasonable direction to take, but given the work involved I'd love to hear your thoughts before I get stuck in to implementation.
 ketzacoatl
ketzacoatl phinze
phinze mitchellh
mitchellh IX-Erich
IX-Erich matthewhartstonge
matthewhartstonge stuartellis
stuartellis handlerbot
handlerbot blaggacao
blaggacao icornett
icornett pycaster
pycaster bodgit
bodgit rochdev
rochdev sinzin91
sinzin91 pryorda
pryorda ColinHebert
ColinHebert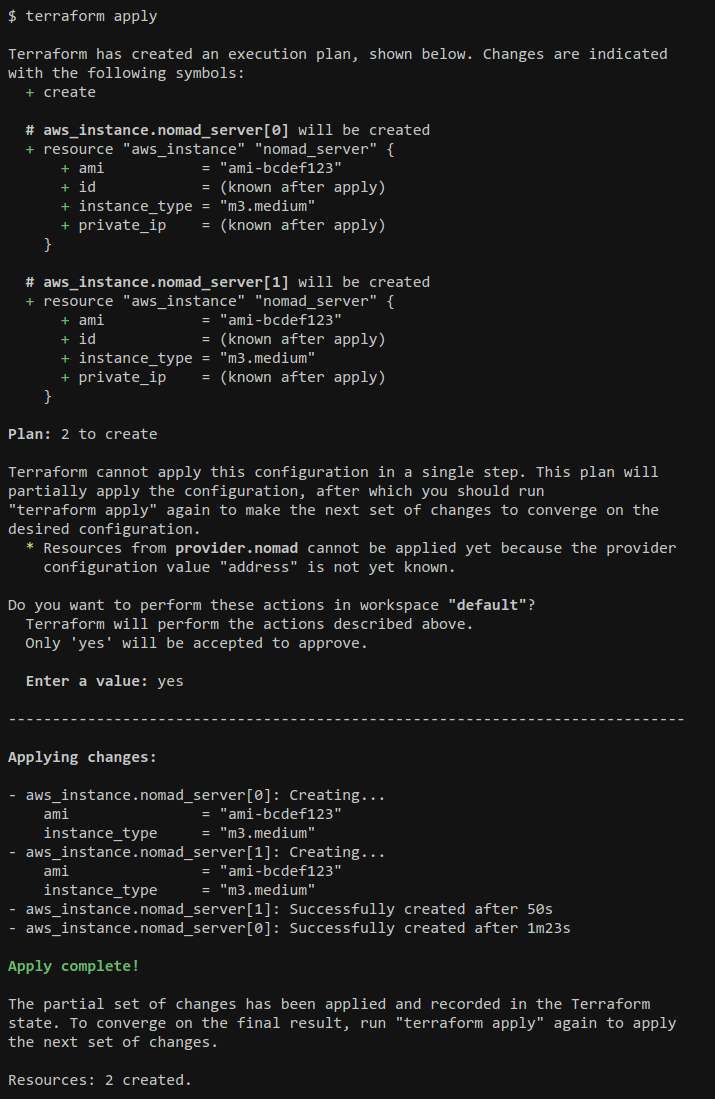
 karl-tpio
karl-tpio rifelpet
rifelpet glasser
glasser cevich
cevich ooOOJavaOOoo
ooOOJavaOOoo Sodki
Sodki pbecotte
pbecotte gretel
gretel lorengordon
lorengordon muhlba91
muhlba91 jspiro
jspiro FaustTobias
FaustTobias aequitas
aequitas ret-aws
ret-aws travis-crowder-kr
travis-crowder-kr sharkymcdongles
sharkymcdongles
For a while now I've been wringing my hands over the issue of using computed resource properties in parts of the Terraform config that are needed during the refresh and apply phases, where the values are likely to not be known yet.
The two primary situations that I and others have run into are:
countmodifier on resource blocks, as described in #1497. Currently this permits only variables, but having it configurable from resource attributes would be desirable.After a number of false-starts trying to find a way to make this work better in Terraform, I believe I've found a design that builds on concepts already present in Terraform, and that makes only small changes to the Terraform workflow. I arrived at this solution by "paving the cowpaths" after watching my coworkers and I work around the issue in various ways.
The crux of the proposal is to alter Terraform's workflow to support the idea of partial application, allowing Terraform to apply a complicated configuration over several passes and converging on the desired configuration. So from the user's perspective, it would look something like this:
For a particularly-complicated configuration there may be three or more apply/plan cycles, but eventually the configuration should converge.
terraform applywould also exit with a predictable exit status in the "partial success" case, so that Atlas can implement a smooth workflow where e.g. it could immediately plan the next step and repeat the sign-off/apply process as many times as necessary.This workflow is intended to embrace the existing workaround of using the
-targetargument to force Terraform to apply only a subset of the config, but improve it by having Terraform itself detect the situation. Terraform can then calculate itself which resources to target to plan for the maximal subset of the graph that can be applied in a single action, rather than requiring the operator to figure this out.By teaching Terraform to identify the problem and propose a solution itself, Terraform can guide new users through the application of trickier configurations, rather than requiring users to either have deep understanding of the configurations they are applying (so that they can target the appropriate resources to resolve the chicken-and-egg situation), or requiring infrastructures to be accompanied with elaborate documentation describing which resources to target in which order.
Implementation Details
The proposed implementation builds on the existing concept of "computed" values within interpolations, and introduces the new idea of a graph nodes being "deferred" during the plan phase.
Deferred Providers and Resources
A graph node is flagged as deferred if any value it needs for
refreshorplanis flagged as "computed" after interpolation. For example:countvalue is computed.Most importantly though, a graph node is always deferred if any of its dependencies are deferred. "Deferred-ness" propagates transitively so that, for example, any resource that belongs to a deferred provider is itself deferred.
After the graph walk for planning, the set of all deferred nodes is included in the plan. A partial plan is therefore signaled by the deferred node set being non-empty.
Partial Application
When
terraform applyis given a partial plan, it applies all of the diffs that are included in the plan and then prints a message to inform the user that it was partial before exiting with a non-successful status.Aside from the different rendering in the UI, applying a partial plan proceeds and terminates just like an error occured on one of the resource operations: the state is updated to reflect what was applied, and then Terraform exits with a nonzero status.
Progressive Runs
No additional state is required to keep track of partial application between runs. Since the state is already resource-oriented, a subsequent
refreshwill apply to the subset of resources that have already been created, and thenplanwill find that several "new" resources are present in the configuration, which can be planned as normal. The new resources created by the partial application will cause the set of deferred nodes to shrink -- possibly to empty -- on the follow-up run.Building on this Idea
The write-up above considers the specific use-cases of computed provider configurations and computed "count". In addition to these, this new concept enables or interacts with some other ideas:
3310 proposed one design for supporting "iteration" -- or, more accurately, "fan out" -- to generate a set of resource instances based on data obtained elsewhere. This proposal enables a simpler model where
foreachcould iterate over arbitrary resource globs or collections within resource attributes, without introducing a new "generator" concept, by deferring the planning of the multiple resource instances until the collection has been computed.2976 proposed the idea of allowing certain resources to be refreshed immediately, before they've been created, to allow them to exist during the initial plan. Partial planning reduces the need for this, but supporting pre-refreshed resources would still be valuable to skip an iteration just to, for example, look up a Consul key to configure a provider.
2896 talks about rolling updates to sets of resources. This is not directly supported by the above, since it requires human intervention to describe the updates that are required, but the UX of running multiple
plan/applycycles to converge could be used for rolling updates too.create_before_destroywith not, as documented in #2944, could get a better UX by adding some more cases where nodes are "deferred" such that the "destroy" node for the deposed resource can be deferred to a separate run from the "create" that deposed it.1819 considers allowing the
providerattribute on resources to be interpolated. It's mainly concerned with interpolating from variables rather than resource attributes, but the partial plan idea allows interpolation to be supported more broadly without special exceptions like "only variables are allowed here", and so it may become easier to implement interpolation of provider.4084 requests "intermediate variables", where computed values can be given a symbolic name that can then be used in multiple places within the configuration. One way to support this would be to allow variable defaults to be interpolated and mark the variables themselves as "deferred" when their values are computed, though certainly other implementations are possible.