 honwen
commented
6 years ago
honwen
commented
6 years ago 已存在的记录 程序没办法知道你哪些要哪些不要 啊。 程序怎么敢乱删
Open islercn opened 6 years ago
honwen
commented
6 years ago 已存在的记录 程序没办法知道你哪些要哪些不要 啊。 程序怎么敢乱删
 islercn
commented
6 years ago
islercn
commented
6 years ago 我在name.com上有一个域名,也容易出现这个问题,我没有一个域名多个IP的需求(估计绝大多数人也没有吧),因此我在脚本里的处理方式是每次获取一次子域名对应的记录条数,然后遍历一遍,全部删掉,再添加新的,当然也可能遍历时某条删除失败,可以尝试删除多次,当然一般也不会那么点背总出问题吧
honwen
commented
6 years ago 我自己就有子域名的需要,再说,用不到的子域名就由它在那里就好了
honwen
commented
6 years ago 我的想法是:一个程序只做一件事,不能越俎代庖
islercn
commented
6 years ago 没问题的啊,就是在更新当前子域名的时候,保证只存在一个正确的IP啊,多条IP本来就是之前更新带来的,按理说本来就应该处理掉
honwen
commented
6 years ago 那不会出现一个子域名对应多个IP的情况,没遇过,具体情况是?
islercn
commented
6 years ago 我没太看阿里的api,我用name.com的api时,是通过api获取对应子域名的解析记录ID,然后根据这个ID删除旧的记录,再添加新的。但是用curl的时候偶尔会超时,导致删除失败,如果接下来添加记录又成功了,那就会出现两条解析记录了,以后更新的时候因为也只是删一条,所以记录就会越来越多。
没仔细看阿里的api,是不是差不多呢,网络不好,或者在插件配置页面点了多次应用,然后阴差阳错,机缘巧合,就会导致添加多条解析记录了
honwen
commented
6 years ago 阿里的API, 一个域名对应一个值,这里是A值,这程序只会在(不存在这个子域名)的时候去添加,已存在只会修改。
islercn
commented
6 years ago 比如办公室里的一台刷了x86 lede的软路由,这几天由于上层交换机故障,IP频繁变化,还时不时断网,然后就出现了多条记录
honwen
commented
6 years ago 我测试一下
islercn
commented
5 years ago 关于解析遗留的问题,我测试基本是和SignatureNonce相关的,同时也不用全删,所以我建议改成这样:
do_ddns_record() {
if uci_bool_by_name base clean ; then
query_recordid | get_recordid | while read rr; do
if [ "Z$rr" != "Z$rrid" ]; then
echo "$DATE Clean record $sub_dm.$main_dm: $rr"
suffix=awk -v min=1000 -v max=9999 'BEGIN{srand(); print int(min+rand()*(max-min+1))}'
timestamp=$(date -u "+%Y-%m-%dT%H%%3A%M%%3A%SZ")$suffix
del_record $rr >/dev/null
fi
done
fi
suffix=awk -v min=1000 -v max=9999 'BEGIN{srand(); print int(min+rand()*(max-min+1))}'
timestamp=$(date -u "+%Y-%m-%dT%H%%3A%M%%3A%SZ")$suffix
rrid=query_recordid | get_recordid
suffix=awk -v min=1000 -v max=9999 'BEGIN{srand(); print int(min+rand()*(max-min+1))}'
timestamp=$(date -u "+%Y-%m-%dT%H%%3A%M%%3A%SZ")$suffix
if [ "Z$rrid" == "Z" ]; then
rrid=add_record | get_recordid
echo "$DATE ADD record $rrid"
else
update_record $rrid >/dev/null 2>&1
echo "$DATE UPDATE record $rrid"
fi
if [ "Z$rrid" == "Z" ]; then
echo "$DATE # ERROR, Please Check Config/Time"
else
# save rrid
uci set aliddns.base.record_id=$rrid
uci commit aliddns
echo "$DATE # UPDATED($ip)"
fi}
honwen
commented
5 years ago @islercn please make a pull request
{kind=link}
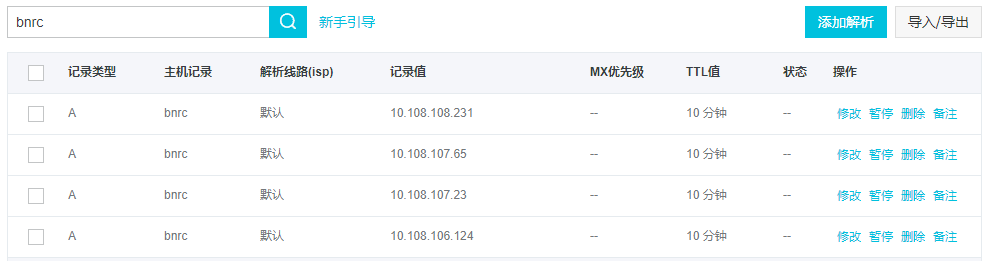
因为网络不好等一些原因,偶尔会导致出现多条解析记录(原有记录删除失败),这些多余的记录,只能手动去删除,不然会一直存在下去,很不方便。因此是否可以改为删除所有已存在的记录,然后再增加新的记录?