 howardyclo
commented
6 years ago
howardyclo
commented
6 years ago Summary
- The word embeddings are derived from a Bi-LM (bidirectional language model), a.k.a., Embeddings from Language Models; ELMo. Specifically, a linear combination of the vector stacked above each input word for each end task, which markedly improves performance over just using the top LSTM layer.
- Idea: Higher-level LSTM states capture context-dependent aspects of word meaning (e.g. perform well on supervised word sense disambiguation tasks) while lower-level states model aspect of syntax (e.g. POS-tagging). By this idea, they pre-trained Bi-LM on 1B Word Benchmark dataset, fixed weights of Bi-LM, and further trained on downstream tasks with additional task-specific model capacity.
- They show that ELMo helps to significantly improve state of the art in six NLP tasks, including up to 20% relative error reduction.
- ELMo also outperforms CoVe (McCann et al. 2017), which computes contextualized representations using a neural machine translation encoder.
- Previous work (Peters et al. 2017) from the same group also uses pre-trained contextualized representation from Bi-LM and apply it to sequence labeling (NER and chunking), achieving state of the art results.
- Code: http://allennlp.org/elmo
ELMo: Embeddings from Language Models
- Bi-LM: They tie input and output word-embedding layers while maintaining separate parameters for the LSTMs in each direction. The next token is predicted by the top layer LSTM output.
- Language model architecture:
- Similar to #8 and character-aware LM (Kim et al. 2016), but modified to support both directions and add a residual connection between LSTM layers.
- They halve all embedding and hidden dimensions from the single best model CNN-BIG-LSTM (#8).
- The final model: 2-layer biLSTM layers with 4096 units and 512 dimension projections and a residual connection from the first to second layer. The word embeddings are derived from 2048 character n-gram convolutional filters followed by two highway layers and a linear projection down to a 512 representation.
- Trained 10 epoches on 1B Word Benchmark, the average forward and backward perplexities is 39.7, compared to 30.0 for the forward CNN-BIG-LSTM.
- ELMo:
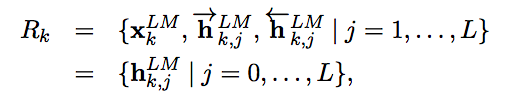
- Note:
xis word embeddings andhis bi-LSTM hidden states.
- Note:
- Using ELMo for supervised NLP tasks:
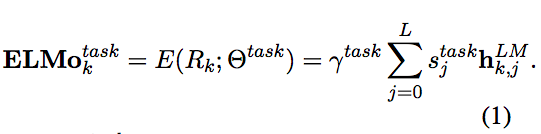
- Note:
sare softmax-normalized weights andris scalar parameter that allows the task model to scale the entire ELMo vector. - Simply concatenate word embeddings and ELMo representation for task-specific RNN's input.
- Additionally concatenating ELMo representation with RNN's output also improves.
- Note:
- Further improvements:
- Add dropout to ELMo.
- Regularize ELMo weights by L2 regularization.
Evaluation
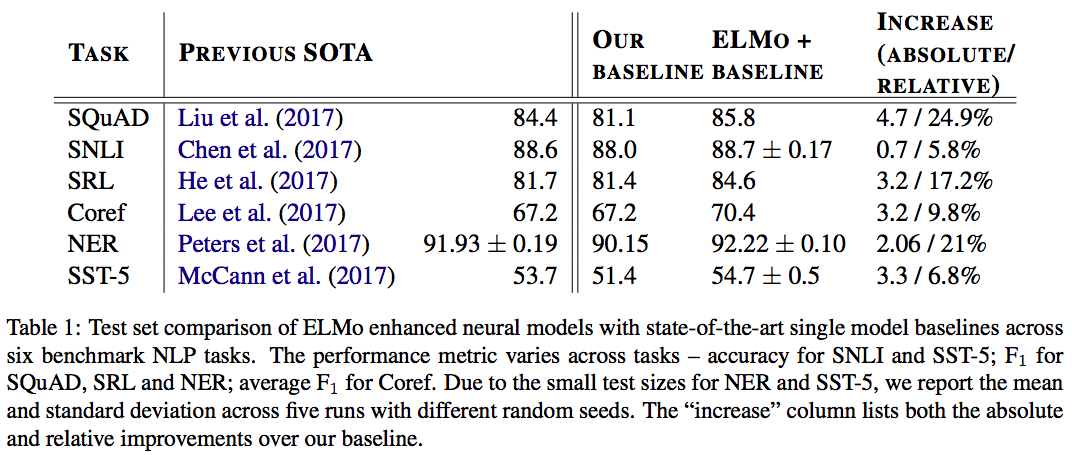
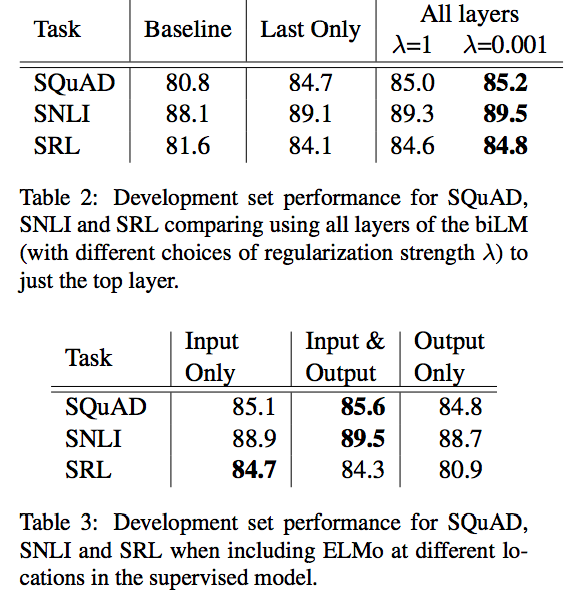
References
- Learned in Translation: Contextualized Word Vectors by McCann et al. (NIPS 2017)
- Semi-supervised sequence tagging with bidirectional language models by Peters et al. (ACL 2017)
- Character-Aware Neural Language Models by Kim et al. (AAAI 2016)
Metadata