 howardyclo
commented
6 years ago
howardyclo
commented
6 years ago Summary
Incorporate linguistic features to improve neural machine translation (NMT) performance, such as lemmas, subword tags, morphological features, part-of-speech (POS) tags and syntactic dependency labels.
Hypotheses
- Lemmatization: Helps in better generalization over inflectional variants of the same word form.
- POS & syntactic dependency: Helps in disambiguation.
NMT Model
Follows the NMT architectures by Bahdanau et al. (2015).
Adding Input Features
The main innovation over the standard encoder-decoder architecture is that they represent the encoder input as a combination of features, or factors (Alexandrescu and Kirchhoff, 2006).
The "Ex" in equation 1 is the vanilla way to embed a word.
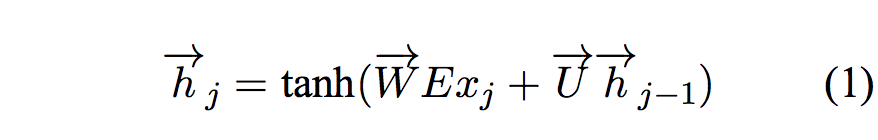
Now, the "||" in equation 2 is the extended way to embed a word and list of features. (The equation here view a word as a features, thus generalize this equation)
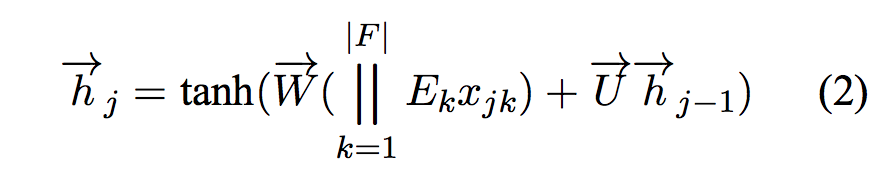
In other words, they look up separate embedding vectors for each feature, which are then concatenated. The length of the concatenated vector matches the total embedding size, and all other parts of the model remain unchanged.
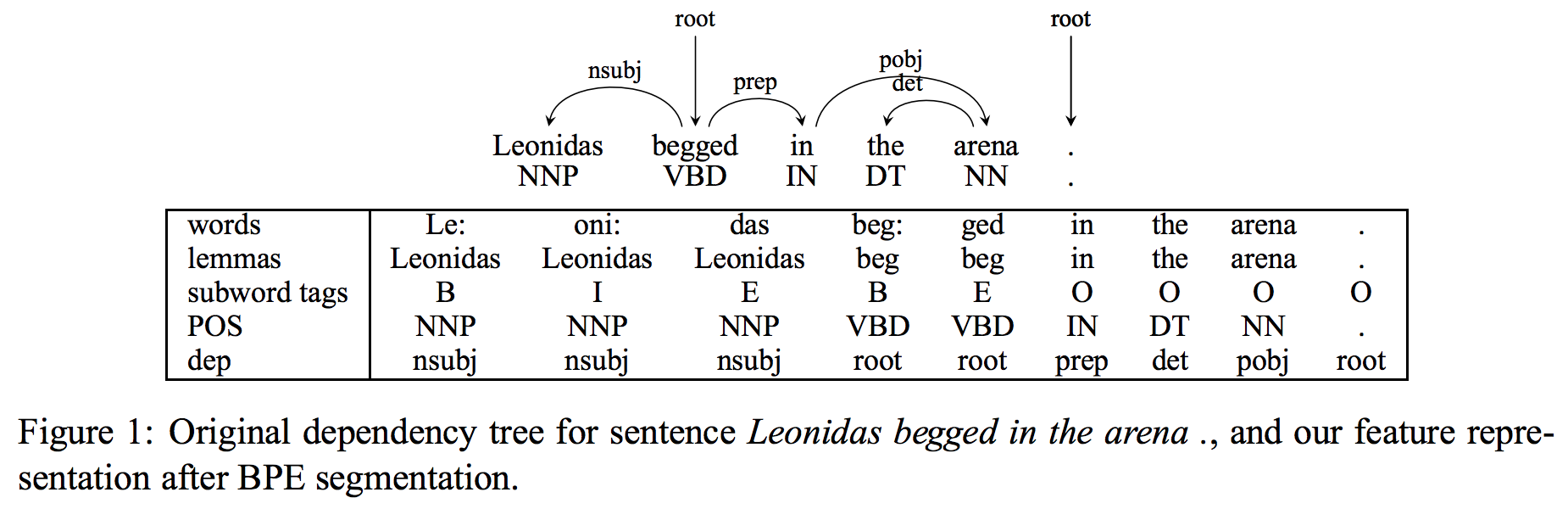
The figure 1 shows how they use word-level features in a subword model. "All other features are originally word-level features. To annotate the segmented source text with features, we copy the word’s feature value to all its subword units."
Experimental Results

Opportunity
This paper addresses the question whether linguistic features on the source side are beneficial for neural machine translation. On the target side, linguistic features are harder to obtain for a generation task such as machine translation, since this would require incremental parsing of the hypotheses at test time, and this is possible future work.
References
- Neural Machine Translation by Jointly Learning to Align and Translate by Bahdanau et al. (2015)
- Factored Neural Language Models by Andrei T Alexandrescu and Katrin Kirchhoff. (2006)
Metadata