 howardyclo
commented
6 years ago
howardyclo
commented
6 years ago Summary
This paper presents a systematic re-evaluation for a number of recently purposed GAN-based text generation models. They argued that N-gram based metrics (e.g., BLEU, Self-BLEU) is not sensitive to semantic deterioration of generated texts and propose alternative metrics that better capture the quality and diversity of the generated samples. Their main finding is that, neither of the considered models performs convincingly better than the conventional Language Model (LM). Furthermore, when performing a hyperparameter search, they consistently find that adversarial learning hurts performance, further indicating that the Language Model is still a hard-to-beat model.
Motivations for GAN-based Text Generation Models
- Exposure bias problem (conditioning on ground truth while training v.s. on its own imperfect predictions while inference) and objective mismatch (negative log-likehood training vs task-specific metric evaluation) exist in conventional neural language model.
- GAN-based text generation mitigates both issues described above.
Motivations for This Paper
- One of the many challenges that slows down the progress is the lack of proper evaluation, which is a largely unsolved problem and is an active area of research.
- Current mostly used evaluation metric, such as N-gram based metrics, BLEU, do not capture semantic variations in generated texts and can only detect relatively simple problems with syntax.
Types fo Benchmarked Models
- Continuous WGAN-GP: Treat a sequence of tokens as a one-dimensional signal and directly backpropagate from the discriminator D. For RNN-based generator G, they feed the entire softmax output as the input for the next step of G. (gumbel softmax can be tried here but left for future research).
- Discrete: In contrast to continuous model, G samples (or argmax) from the softmax output. But this makes G output non-differentiable and gradients from D cannot be backpropagated through G. Thus, using REINFORCE algorithm can be used to approximate the gradient, where output from D can be treated as reward in REINFORCE algorithm.
Tricks to Address RL Issues for Training Discrete GAN Models
- Credit assignment: Monte-Carlo(MC) rollouts purposed by SeqGAN, that generates multiple entire sequences and have them scored with a per-sequence discriminator and use its output as a reward.
- Reward sparsity: Pretrain generator with negative log-likehood objective.
Discrete GAN Models
SeqGAN
- SeqGAN-reinforce: Simplest form of RL+GAN. Suffer from credit assignment issue
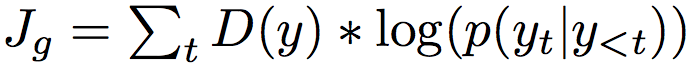
- SeqGAN-step: Mitigate credit assignment issue in SeqGAN-reinforce by following the approach same as MaskGAN, but suffer from the issue of scoring an incomplete sequence.
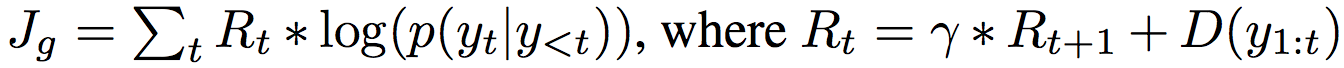
- SeqGAN-rollout: Use MC rollouts to address the issue in SeqGAN-step.
LeakGAN
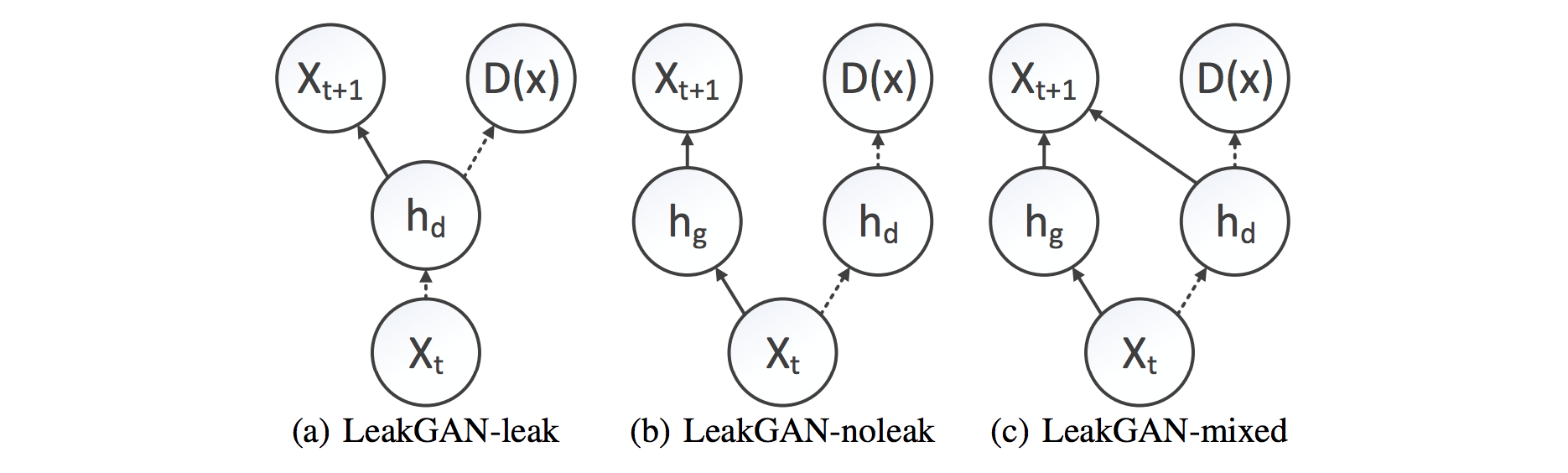
Reveal D's state to the G. They found that it is important to fuse D's and G's state with a non-linear function and thus they use a one-layer MLP to predict the distribution over the next token. In this setup, they use per-step discriminator. Three variants of the LeakGAN model that differ in how a hidden state of D is made available to G are considered: LeakGAN-leak, LeakGAN-noleak and LeakGAN-mixed:
Evaluation Methodology
Metrics
- BLEU4: Cannot capture semantic variations in generated texts and can only detect relatively simple problems with syntax.
- Pretrained language model score: Has a drawback that a model that always generates a few highly likely sentences will score very well.
- Reverse language model score: Train a LM on samples and then evaluate its performance on a held out set of real texts. However, the score is biased due to model bias (imperfection of LM) and data bias (samples as a proxy for the real data distribution).
- Frechet InferSent Distance (FD), a variant of Frechet Inception Distance (FID): FID measures the distance between distributions of features (embeddings) extracted from real and generated samples by a specific image classifier, which is widely used for evaluating GANs for images. In this paper, they adopt FID by using InferSent/UniSent/UniSent-T text embedding model, naming the metric Frechet InferSent Distance (FD).
- Human evaluation: 200 samples from each model (uniformly sampling) to the human (using 3 raters per sample) asking them to score the grammaticality and understandability on a scale from 1 to 5.
Parameter optimization procedure
They optimize each model's hyperparameters with 100 trials of random search. Once the best hyperparameters is found, they retrain with these hyperparameters 7 times and report mean and standard deviation for each metric to quantify how sensitive the model is to random initialization.
Data
600k unique sentences from SNLI & MultiNLI dataset, preprocessed with the unsupervised text tokenization model SentencePiece, with a vocabulary size equal to 4k.
Metric Comparison
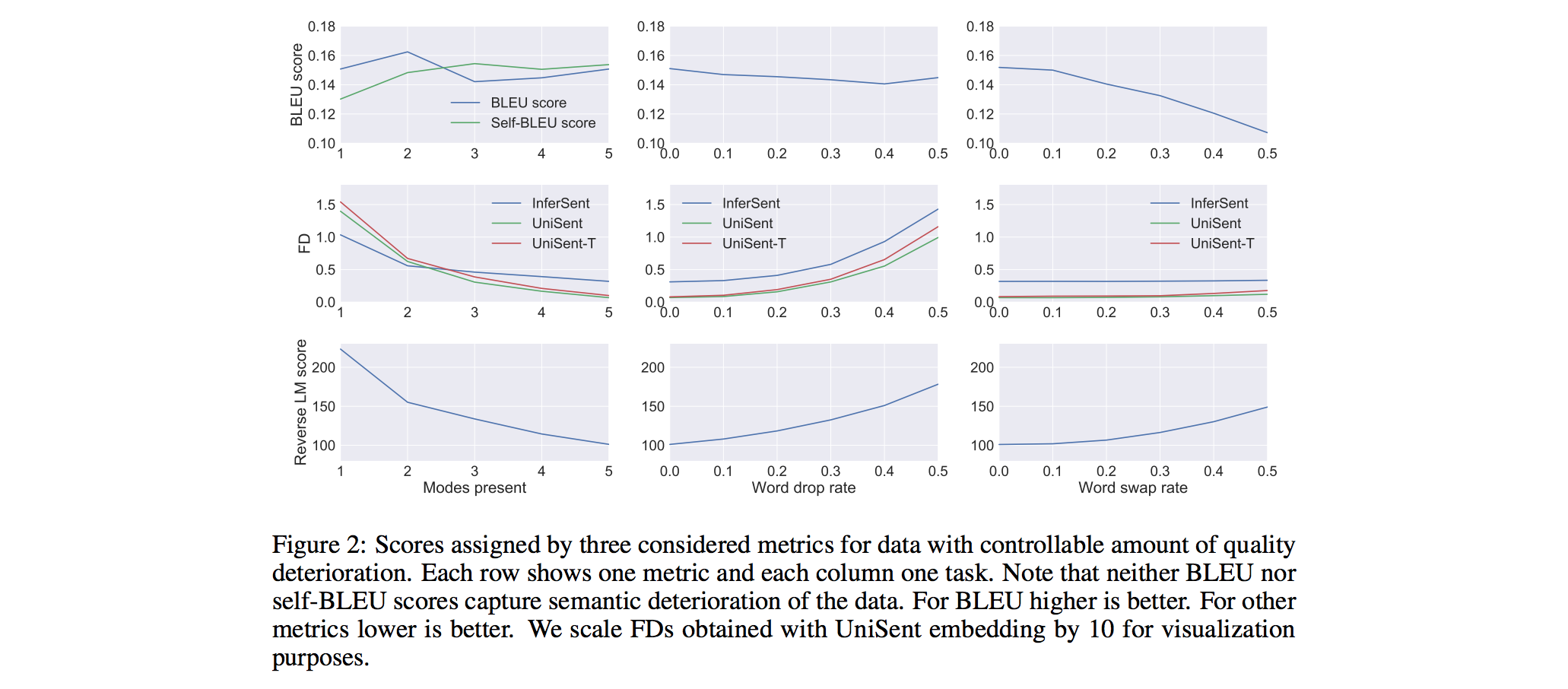
- Evaluating mode collapse (diversity of text): Evaluation metric should capture the fact that some topics are present in the reference but not in samples. (Fixed topics in train set and all topics in test set)
- BLEU4 fails to capture semantic variations.
- FD & Reversed LM score drastically increase more and more topics are removed. (Success)
- Self-BLEU: Sample from a model twice and then compute BLEU score of one set of samples with respect to the other one. If a model suffers from mode collapse, then its samples are similar to each other and such a metric will produce high values. In this experiment, however, self-BLEU cannot detect this kind of mode collapse.
- Evaluating sample quality: Word dropping and swaping in sampled sentence with a probability p.
- BLEU4 fails to capture word dropping, but succeed to capture word swapping.
- FD succeeds to capture word dropping, but fails to capture word swapping.
- Reversed LM score succeeds to capture both word dropping and word swapping.
- Evaluating the metrics can be able to detect that larger LM produces better samples: All three metrics exhibit strong correlation with the performance of LM with different hidden sizes. (strong LM -> large hidden size).

The experiments suggest that both FD and reverse LM score can be successfully used as a metric for unsupervised sequence generation models.
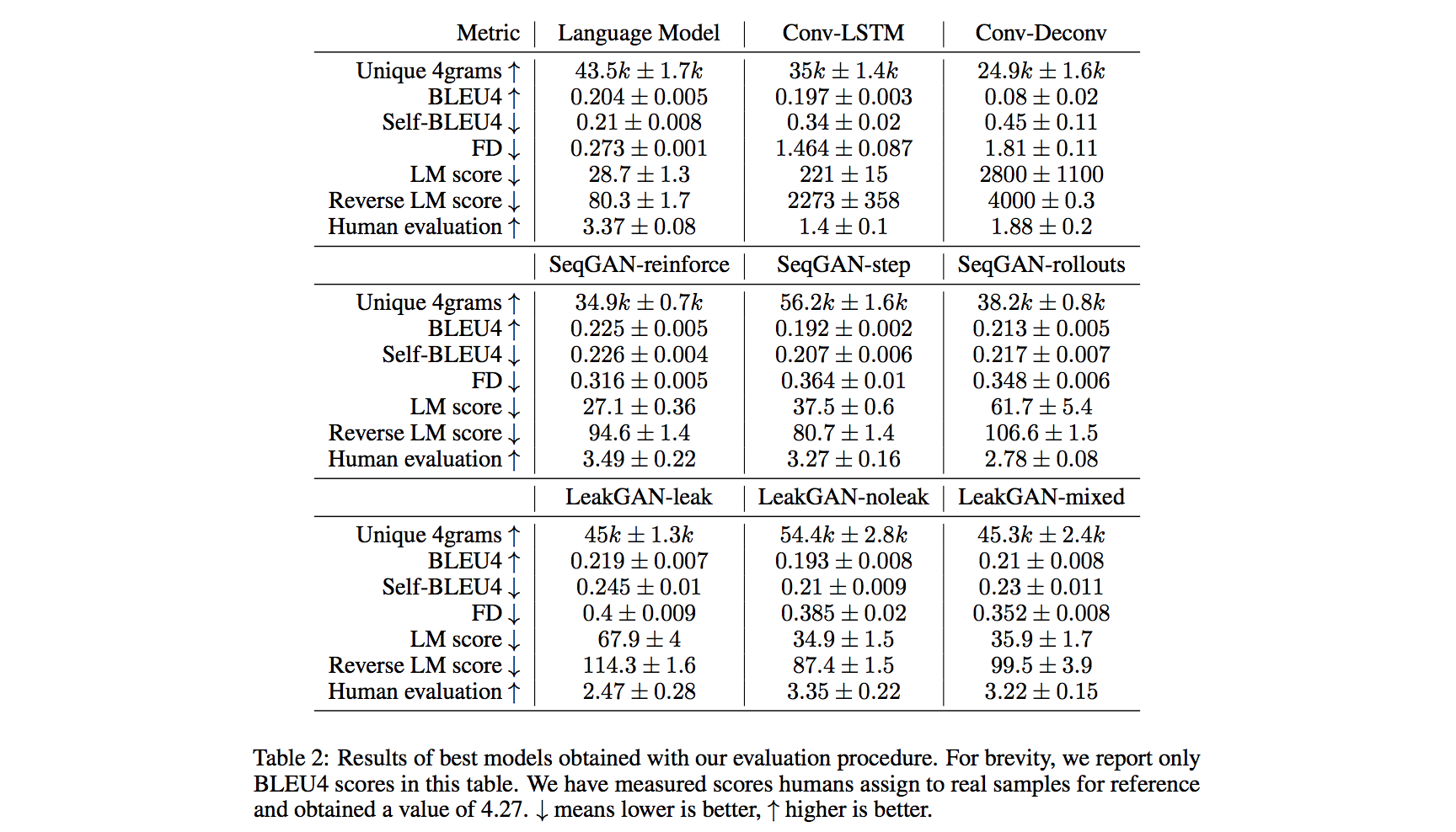
GAN Model Comparison (Important Findings)
For all GAN models, they fix the generator to be one-layer Long ShortTerm Memory (LSTM) network.
- Discrete GAN models outperform continuous ones, which could be attributed to the pretraining step.
- SeqGAN-reinforce achieves lower LM score and higher human ratings than the Language Model but higher reverse LM scores, suggesting improved precision at large cost to recall.
- Most of GAN models achieve higher BLEU scores than the LM, while other metrics disagree, showing that looking only at BLEU scores would put the LM at a significant disadvantage.
- No GAN model is convincingly better than the LM. However, the LM is not convincingly better than SeqGAN-reinforce either. While the LM achieves lower FD, LM score and human evaluations prefer the GAN model. This further supports that it is important to report different metrics – reporting only FD would make the comparison biased towards the LM.
- We do not observe improvements of models with access to the discriminator’s state in LeakGAN-leak, suggesting that the previously reported good result may be due to the RL setup.
- Supervised pretraining of the generator is extremely important, since training of every GAN model that achieves reasonable results includes pretraining step.
- Lower learning rates help to keep the generator weights close to a Language Model used to initialize the weights.
- BLEU scores of the generated sequences improve suggesting, higher precision for GAN models.
Future Research
- Neither of the those metrics is perfect since they do not detect overfitting.
- No metric provides breakdown into precision and recall.
- Disentangling various dimensions affecting the results of GAN models.
- Performing similar comparison for conditional models, such as image captioning and machine translation.
Related Work
- Neural Text Generation: Past, Present and Beyond by Lu et al., 2018
- Eval all, trust a few, do wrong to none: Comparing sentence generation models by Cífka et al., 2018. (Google)
- Assessing Generative Models via Precision and Recall by Sajjadi et al., 2018 (Google Brain)
 xpqiu
xpqiu
Metadata
Authors: Stanislau Semeniuta, Aliaksei Severyn, Sylvain Gelly Organization: Google AI Conference: NIPS 2018 Paper: https://arxiv.org/pdf/1806.04936.pdf