 howardyclo
commented
5 years ago
howardyclo
commented
5 years ago Summary
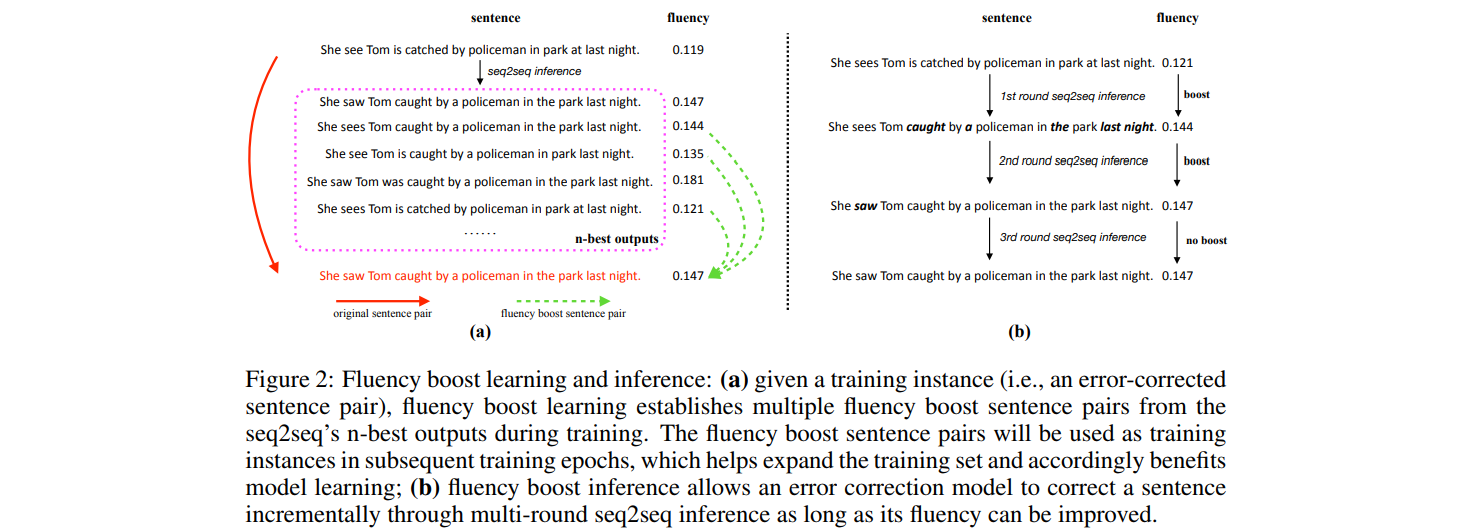
- Present fluency boost learning and inference mechanism for seq2seq model. (See figure 2)
- Fluency boost learning: Generates more error-corrected sentence pairs from model's n-best list, enabling error correction model to see more error sentences during training and accordingly improving its generalization ability.
- Fluency boost inference: Correction model correct a sentence incrementally with multiple inference steps as long as the fluency can be boosted.
- Reaching human-level performance on CoNLL-2014 (F_0.5 score: 75.72 > 72.58) and JFLEG (GLEU: 62.42 > 62.37) dataset.
Flaws of Seq2Seq Model (Motivation of This Paper)
- Current error-correct sentence pairs are not large enough for seq2seq to learn to generalize well. Thus, if testing sentence is slightly different in training sentence, seq2seq commonly fails to correct it.
- Seq2Seq model usually cannot correct a sentence perfectly through single-round inference.

Fluency Boost Learning
- Fluency score f(x) for a sentence x: 1/1+H(x), where H(x) is the cross-entropy of the sentence x, computed by a language model. The range of H(x) is [0, +∞], and accordingly, f(x) is (0, 1].
- Three fluency boost learning strategies are presented: Back-boost, self-boost, and dual-boost.
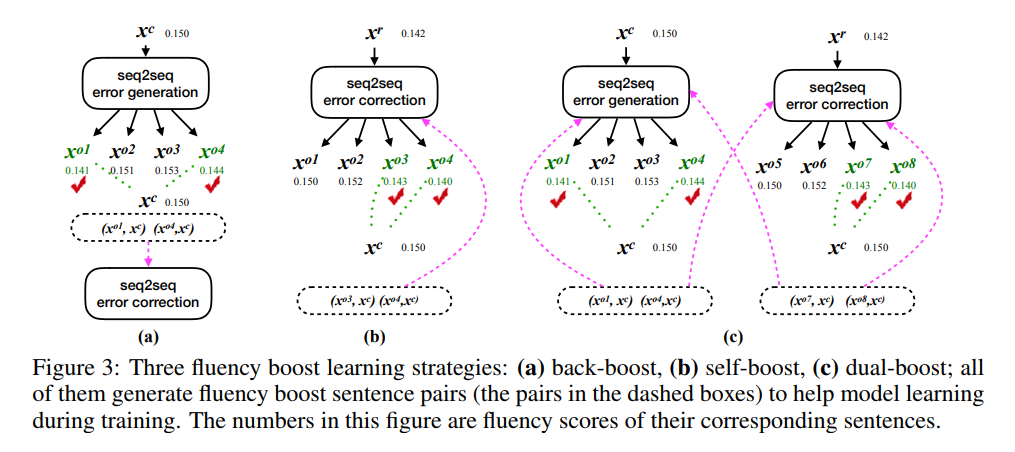
Back-Boost Learning

- Borrows the idea from back translation (Sennrich et al., 2016) in NMT.
- Train a reverse model (input correct sentence x^c, output error sentence x^o) to generate N error-correct sentence pairs through beam search as additional data.
- The additional data need to be filtered by f(x^c)/f(*x^o) ≥ σ, in order to filter out sentence pairs with unnecessary edits (e.g., I like this book. → I like the book.). (Same for self-boost & dual-boost)
- They set σ = 1.05 since the corrected sentence in our training data improves its corresponding raw sentence about 5% fluency on average.
- Constrain the size of additional data not to exceed the size of original error-correct sentence pairs.
Self-Boost Learning

- Generate N error-correct sentence pairs by a correction model itself through beam search.
- It is also noteworthy that D_self (x^c) (the error candidates of correct sentence) is incrementally expanded because the error correction model is dynamically updated.
Dual-Boost Learning

The error correction model and the error generation model are dual and both of them are dynamically updated, which improves each other: the disfluency candidates produced by error generation model can benefit training the error correction model, while the disfluency candidates created by error correction model can be used as training data for the error generation model.
Fluency Boost Learning with Large-Scale Native Data
The purposed strategies can be easily extended to utilize massive native text data, where we can additionally increase correct-correct sentence pairs from native data.
Fluency Boost Infenrece
- Multi-round error correction: seq2seq infers multiple times by taking its prediction at previous time as input at current time, until its prediction at the current time does not improve its prediction at previous time in terms of fluency.
- Round-way error correction: Some types of errors (e.g., articles) are easier to be corrected by a right-to-left seq2seq, while some (e.g., subject verb agreement) are more likely to be corrected by a left-to-right seq2seq.
Experiments
Dataset
- Train set:
- Learner dataset: Lang-8 (1114139) + CLC (1366075) + NUCLE (57119) + Extended Lang-8 (2865639) = 5402972 error-correct sentence pairs.
- Native dataset: 61677453 sentences from Wikipedia.
- Dev set: CoNLL-2013 test set & JFLEG dev set respectively for different test set.
- Test set: CoNLL-2014 (1312; 2(old)/10(new) human annotations for each test sentence.) & JFLEG (747; 4 human annotations for each test sentence.)
- Metrics: MaxMatch for CoNLL-2014 & GLEU for JFLEG.
Experiment setting
- Model: Fairseq (conv-seq2seq) for both error correction & generation seq2seq.
- Number of layer: 7
- Size of word embedding for both encoder & decoder: 500.
- Size of hidden layers for both encoder and decoder: 1024.
- Conv window: 3
- Vocab size for both source and target size: 30K BPE tokens.
- Optimizer: Nesterov Accelerated Gradient with a momentum value of 0.99.
- Initial learning rate: 0.25 + learning rate decaying if validation perplexity stops improving.
- Dropout: 0.2
- Terminate training when learning rate falls below 1e-4.
- Ensemble decoding with 4 models with different random initializations.
- Use dual-boost learning + native data + round-way error correction.
- Additional error-correct pairs are generated from 10-best outputs (beam search)
- Use 5-gram language model trained on Common Crawl released by Junczys-Dowmunt & Grundkiewicz (2016) for computing fluency score.
- Preprocessing JFLEG with Bing Spell Check.
Experiment Results
(Note: See tables in the paper, we only provide analysis here)
- The baseline without fluency boost learning & infernece outperforms most of previous systems owing to the larger size (2x~5x; non-public CLC & non-benchmark extended Lang-8) of training data.
- Fluency boost learning improves both precision and recall by 2~5 points, and GLEU by ~1 point.
- Fluency boost inference decreases precision by 4 points, but increases recall by 3~4 points, and improves GLEU by ~1 point (demonstrate it actually improves sentence's fluency).
Contributions
Unlike the models trained only with original error-corrected data, we propose a novel fluency boost learning mechanism for dynamic data augmentation along with training for GEC, despite some related studies that explore artificial error generation for GEC.
We propose fluency boost inference which allows the model to repeatedly edit a sentence as long as the sentence’s fluency can be improved. To the best of our knowledge, it is the first to conduct multi-round seq2seq inference for GEC, while similar ideas have been proposed for NMT (Xia et al., 2017).
Related Work
- Deliberation Networks: Sequence Generation Beyond One-Pass Decoding by Xie et al., NIPS 2017.
- Noising and denoising natural language: Diverse backtranslation for grammar correction by Xie et al., NAACL 2018. (Similar idea to Back-Boost Learning and applying native data).
Metadata