 howardyclo
commented
6 years ago
howardyclo
commented
6 years ago Summary
This paper purposes to train neural machine translation (NMT) model from scratch on both bilingual and target-side monolingual data in a multi-task setting by modifying the decoder in a neural sequence-to-sequence model to enable multi-task learning for target-side language modeling and translation.
This paper is similar idea to #3 , where #3 uses a recurrent neural network (RNN) to jointly train sequence labeling and bidirectional language modeling (predict context words). But the difference between them is that this paper only predicts the next target word from the representation of the lowest layer of the decoder, and an attentional recurrent model conditioned on source representation, while #3 predicts context words from the representation of the top layer of the RNN.
Though the experimental result shows some improvement, it doesn't improve significantly as training on synthetic using back-translation approach (Sennrich et al., 2016) as well.
Incorporating Monolingual Data by Adding Separate Decoder LM layer (LML)
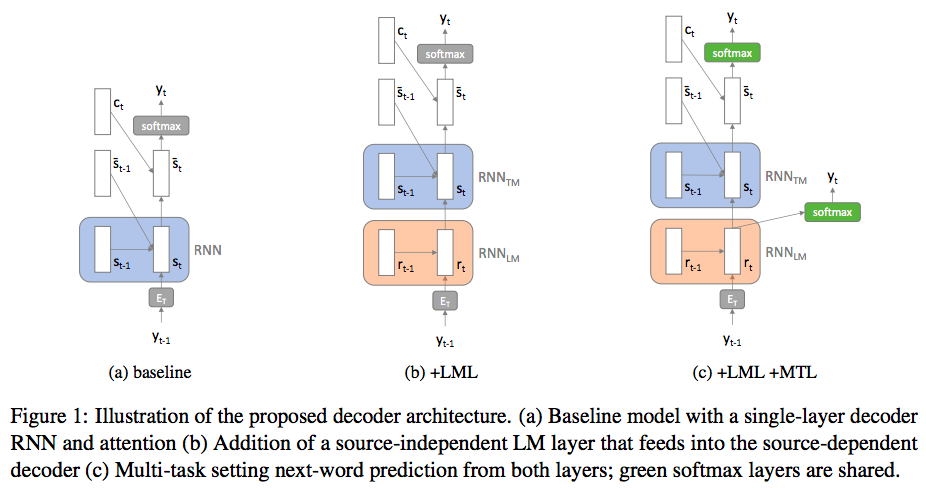
Vanilla RNN decoder in seq2seq (see a. in Figure 1) are not available for monolingual corpora and previous work has tried to overcome this problem by either using synthetically generated source sequences or using a NULL token as the source sequence (Sennrich et al., 2016) As previously shown empirically, the model tends to forget source-side information if trained on much more monolingual than parallel data.
In their approach (see b. & c. in Figure 1 ), they use an additional "source-independent" decoder for target-side language modeling at the bottom of the original "source-dependent" decoder.
Multi-task Learning (MTL)
The language model can also be jointly trained with the translation task. They trained it through the joint loss:
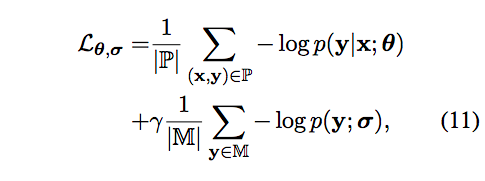
The parameters (σ) of "source-independent" decoder are updated by gradients from both translation and language modeling, while the parameters (θ) of "source-dependent" decoder are updated only by gradients from translation task. Note: σ is part of θ.
In practice, mini-batch of training examples are composed of 50% parallel data, 50% monolingual data and set γ (gamma) to 1.
Experiments
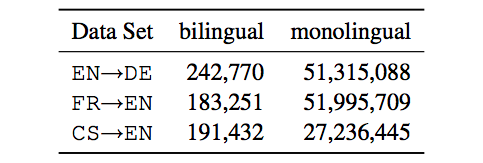
Data statistics:
Experimental Setup
- Preprocessing: Apply Byte Pair Encoding (BPE) with 30k merge operations learned on joined bilingual data.
- Baseline model: 1-layer bi-LSTM encoder with embedding size of 512 and hidden size of 1024; 1-layer LSTM decoder with hidden size of 1024 and attention network with hidden size of 256.
- Optimizer: Adam with learning rate 0.0003, no weight decay and max gradient norm set to 1.
- Batch size: 64
- Maximum sequence length: 100
- Dropout: 0.3 for embedding and RNN outputs.
- Weight initialization: Orthogonal matrices for RNN and Xavier method for the remaining parameters.
- Training: Synthetic parallel data are generated by back-translation (Sennrich et al., 2016).
- LML ("Source-independent" decoder): Same settings as the baseline model.
Results
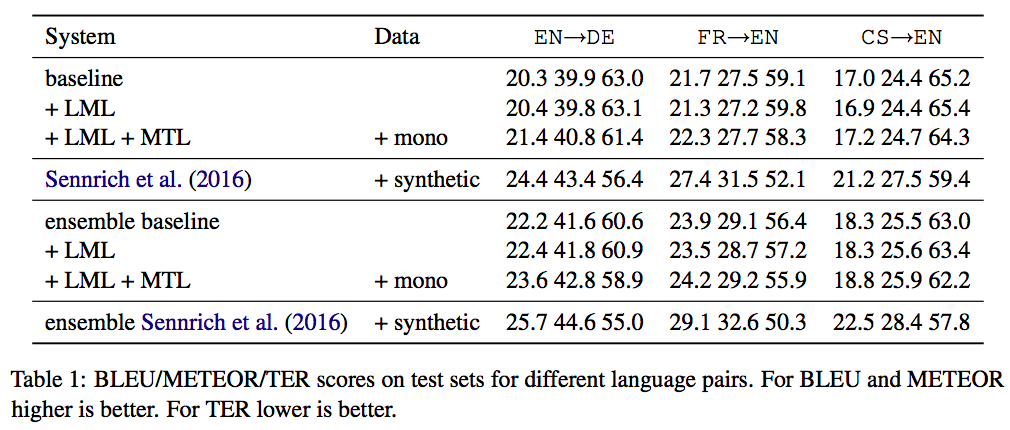
- LML doesn't significantly improves.
- MTL improves by a small but consistent margin across all metrics.
- The use of synthetic parallel data still outperforms their approach.
Hypothesis (Or maybe insights...)
While separating out a language model allowed us to carry out multi-task training on mixed data types, it constrains gradients from monolingual data examples to a subset of source-independent network parameters (σ). In contrast, synthetic data always affects all network parameters (θ) and has a positive effect despite source sequences being noisy. We speculate that training from synthetic source data may also act as a model regularizer.
References
- Exploiting Source-side Monolingual Data in Neural Machine Translation by Zhang and Zong. (EMNLP 2016)
- Improving Neural Machine Translation Models with Monolingual Data by Sennrich et al. (ACL 2016)
- Multi-task sequence to sequence learning by Luong et al. (ICLR 2016)
Metadata