 howardyclo
commented
5 years ago
howardyclo
commented
5 years ago Summary
Contribution
- Propose a novel formulation for object detection as detecting bounding box as paired keypoints (top-left and bottom-right corner), which does away with anchor boxes.
- Propose corner pooling for improving corner localization.
- Modify the hourglass network and add novel variant of focal loss.
- Achieves 42.1% AP on MS COCO, outperforming all existing one-stage detectors.
Drawback of Using Anchor Boxes in Traditional One-stage Detector
- Traditional one-stage detector places anchor boxes (predefined candidate boxes with various sizes and aspect ratios) densely over an image and generate final box predictions by scoring anchor boxes and refining their coordinates through regression.
- Method uses anchor boxes for training will creates a huge imbalance between positive and negative anchor boxes and slows down training (Ref. Focal loss)
- Introduce hyperparameter choices.
- Become very complicated when combining with multiscale architectures where a single network makes separate predictions at multiple resolutions, with each scale using different features and its own set of anchor boxes. (SSD, Focal loss, DSSD).
How Does CornerNet Work?

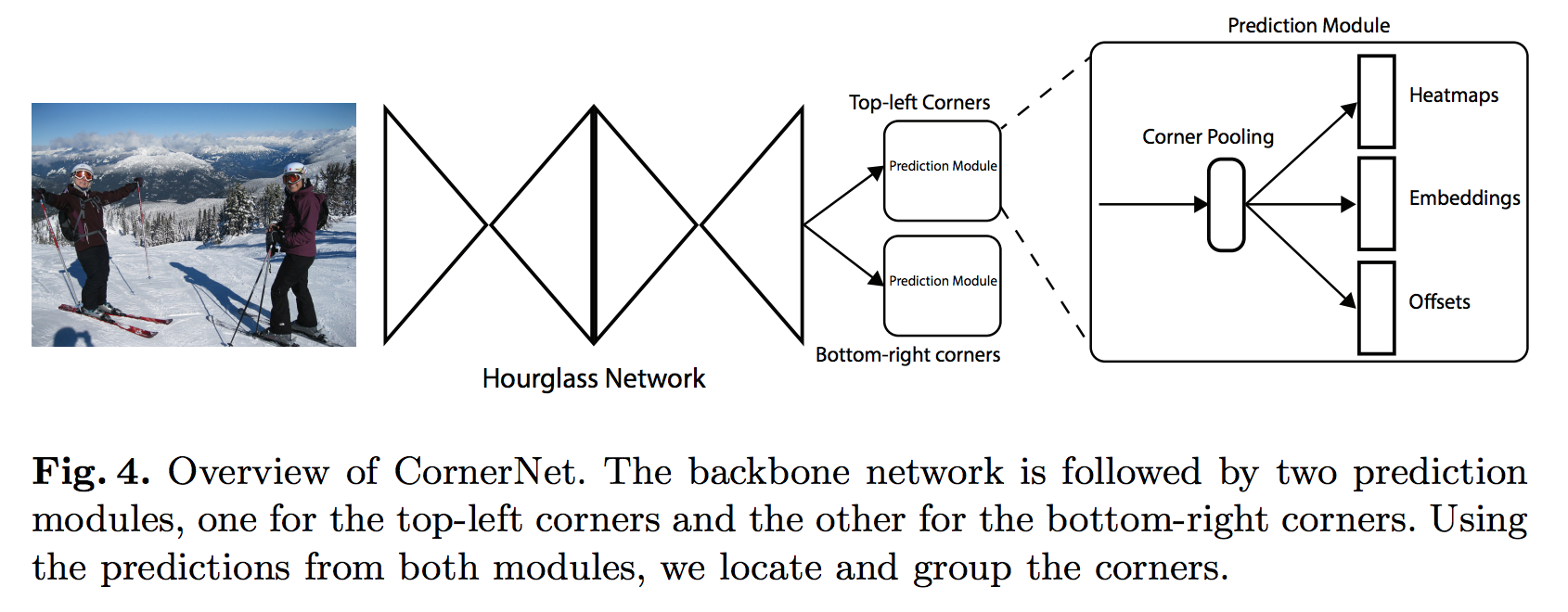
- Use a single convolutional network to predict:
- A set of heatmap for the top-left corners of all instances of the same object category.
- A set of heatmap for the bottom-right corners of ... (same as the above).
- Note: Each set of heatmaps has C channels, where C is object classes (no background class). Each channel is a binary mask indicating the locations of the corners for a class.
- An embedding vector for each detected corner (inspired from NIPS'17 associative embedding). The embeddings serve to group a pair of corners that belong to the same object -- the network is trained to predict similar embeddings for them.
- To produce tighter bounding boxes, the network also predicts offsets to slightly adjust the locations of the corners.
How Does Corner Pooling Work?

- Motivation: A corner of a bounding box is often outside the object, thus cannot be localize based on local evidence. For the top-most corner, we need to look horizontally towards the right for the topmost boundary of the object, and look vertically towards the bottom for the leftmost boundary.
- It takes in two feature maps; at each pixel location it max-pools all feature vectors to the right from the first feature map, max-pools all feature vectors directly below from the second feature map, and then adds the two pooled results together.


How Is Corner Pooling Used in CornerNet?

Losses
- Corner detection loss:

- Corner offset loss:


- Grouping corner loss:

- Note: they use 0.1 to weight this 2 loss terms, since set to 1 for both leads to poor performance.
Ablation Study
- Corner pooling

- Reducing penalty to negative locations

- Error analysis

Comparisons with State-of-the-art Detectors

Metadata