 howardyclo
commented
6 years ago
howardyclo
commented
6 years ago Summary
This paper purposes to initialize the weights of encoder and decoder in neural sequence-to-sequence (Seq2Seq) model with two pre-trained language models, and then fine-tuned with labeled data. During the fine-tuning phase, they jointly train the Seq2Seq objective with the language modeling (LM) objectives to prevent overfitting. The experiment results show that their method achieves an improvement of 1.3 BLEU from the previous best models on both WMT'14 and WMT'15 English->German. Human evaluations on abstractive summarization also shows that their method outperforms a purely supervised learning baseline. (See more important insights on ablation studies)
This paper is also similar to #3, #5 and #6.
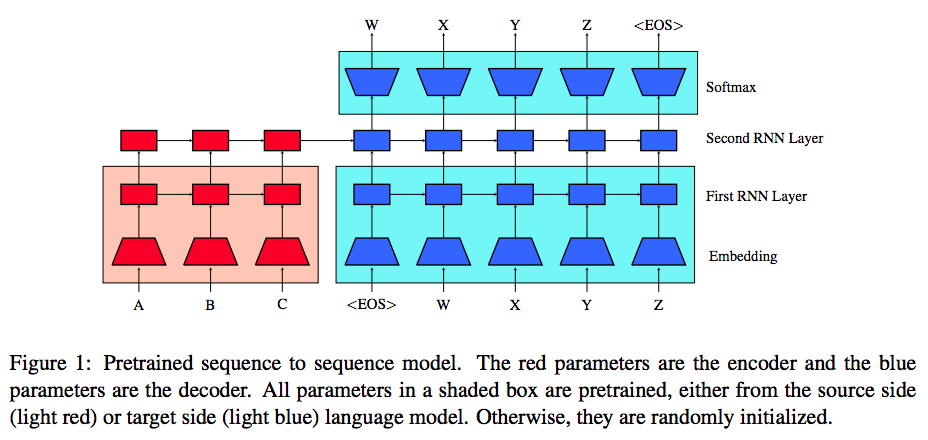
Fine-tuning with Language Modeling Objective
After the Seq2Seq is initialized with pre-trained language models (see Figure 1), the Seq2Seq is then fine-tuned with both the translation objective and the language modeling objective (multi-task learning), to avoid catastrophic forgetting (GoodFellow et al. 2013).
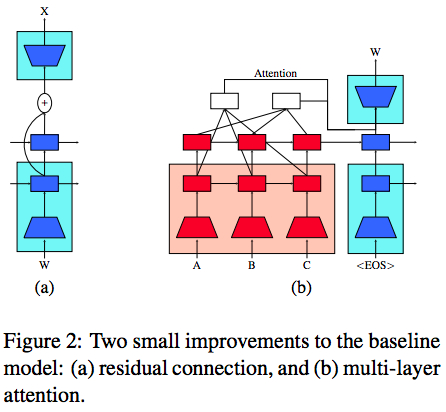
Other Improvements
- Residual connections: The residual connections can avoid the problem of feeding the random-permuted vector from the task-specific layer to softmax layer, since the task-specific layer is random initialized at first.
- Multi-layer attention: Attending on both task-specific layer and pre-trained layer.
Experiment Settings
Machine translation dataset
- Training: WMT14 English->Germain dataset, 4 million after preprocessing.
- Tokenization: BPE with 89500 merge operations, giving a vocabulary size around 90000.
- Validation: Concatenated newstest2012 and newstest2013
- Testing: newstest2014 and newstest2015
- Metric: BLEU
- Monolingual training dataset: The News Crawl English and German corpora, each of which has more than a billion tokens.
- The language model is trained in the same fashion as Jozefowicz et al. (2016).
- Hyperparameters:
- Language model: 1-layer 4096 dimensional LSTM with hidden size projected down to 1024 (I think it is 1000, not 1024) units. (Trained for one week on 32 Tesla K40 GPUs)
- Seq2Seq: 3-layer model where 2th and 3th layers each have 1000 hidden units.
- Adam optimizer with 5e-5 learning rate.
- Learning rate is multiplied by 0.8 every 50K steps after an initial 400k steps.
- Max gradient norm: 5.
- Dropout: 0.2 on non-recurrent connections.
- Beam size: 10
Abstractive summarization dataset
- Training: CNN/Daily Mail corpus (fewer than 300K document-summary pairs)
- Metric: Full length Rouge
- Monolingual training dataset: English Gigaword corpus
- Tokenization: BPE with 31500 merge operations, giving a vocabulary size around 32000.
- The language model is trained in the same fashion as Jozefowicz et al. (2016).
- Hyperparameters:
- Language model: 1-layer 1024 dimensional LSTM.
- Seq2Seq: Similar settings as the machine translation experiments, with the second layer having 1024 hidden units.
- Learning rate is multiplied by 0.8 every 30K after an initial 100K steps.
Experiment Results
Results on machine translation task:

Figure 3 shows important Insights on ablation studies on machine translation.
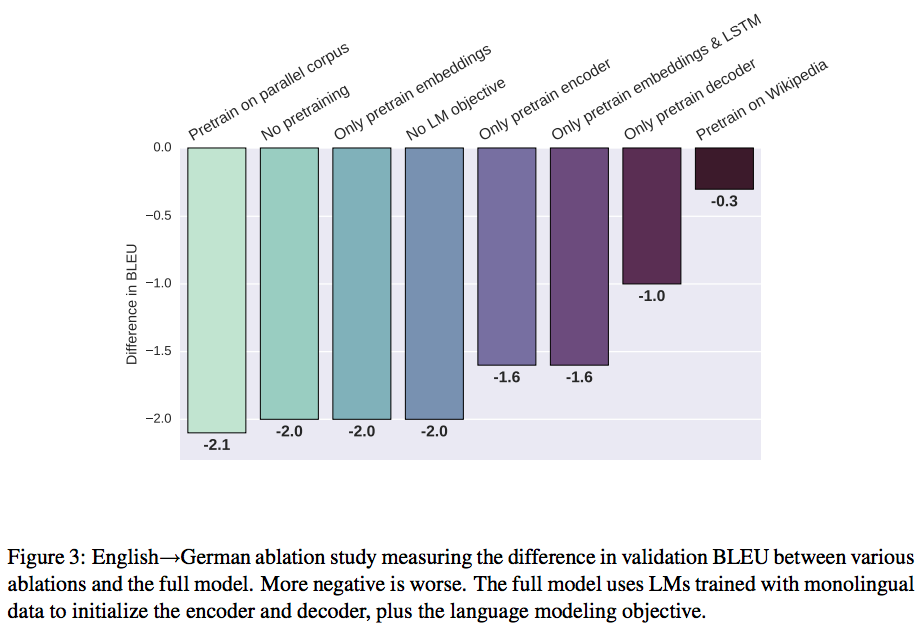
- For translation, the main gains come from the pre-training features.
- For summarization, pre-training the encoder gives large improvements.
- Only pre-training the decoder is better than only the encoder.
- Pre-train as much as possible.
- Pre-train the softmax (target embeddings) is important.
- The auxiliary LM objective is a strong regularizer. Pre-training the entire model without LM objective is as bad as using the LM objective without pre-training.
- Pre-training on a large-scale unlabeled data is essential. If LM is only pre-trained on parallel data (4 million each side) is as bad as not pre-training at all.
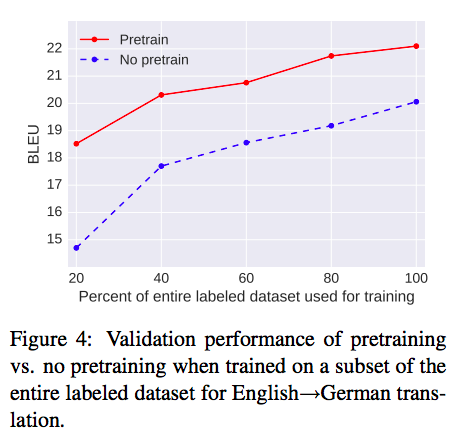
Figure 4 shows that the unsupervisedly pre-trained models degrade less than the models without unsupervised pre-training as the labeled dataset becomes smaller.
Results on abstractive summarization task:

The unsupervisedly pre-trained model is only able to match the baseline model, which uses a word2vec pre-trained embeddings + bi-LSTM encoder. Don't forget that this paper just uses an uni-directional LSTM as encoder in Seq2Seq. This result shows that just pre-training the embeddings itself gives a large improvement
Figure 5 shows important Insights on ablation studies on abstractive summarization.
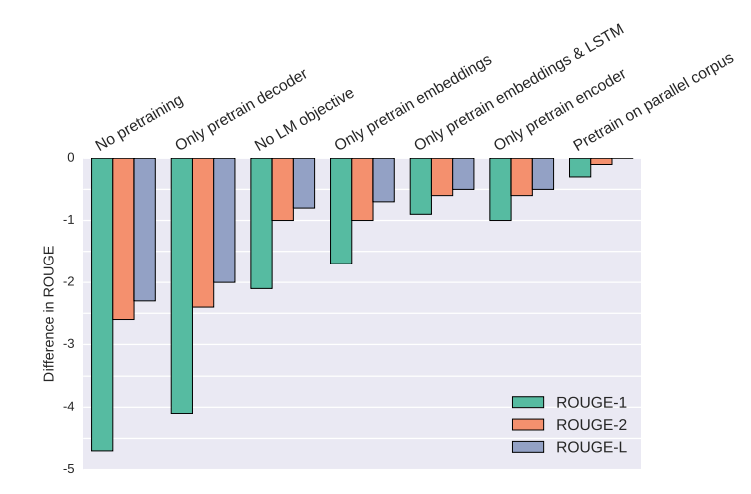
- In contrast to machine translation, only pre-training the encoder is better than only the decoder.
- The auxiliary LM objective is still a strong regularizer.
Finally, human evaluation shows that not only the better generalization the unsupervised pre-training method can achieve, but also the decrease of unwanted repetition in abstractive summarization.
Personal Thoughts
Maybe we can use a bi-LSTM to pre-train a bidirectional language modeling instead of using only an uni-directional pre-trained LSTM purposed in this paper.
References
- An Empirical Investigation of Catastrophic Forgeting in Gradient-Based Neural Networks by Ian GoodFellow et al. (2013)
- Exploring the Limits of Language Modeling by Jozefowicz et al. (2016)
Metadata
Authors: Prajit Ramachandran, Peter J. Liu and Quoc V. Le Organization: Google Brain Conference: EMNLP 2017 Link: https://goo.gl/n2cKG9