 howardyclo
commented
3 years ago
howardyclo
commented
3 years ago Prior Approaches on Knowledge Distillation
Basically, knowledge distillation aims to obtain a smaller student model from typically larger teacher model by matching their information hidden in the model. The information could be: final soft predictions, intermediate features, attentions, relations between samples. See this complete review.
Highlights
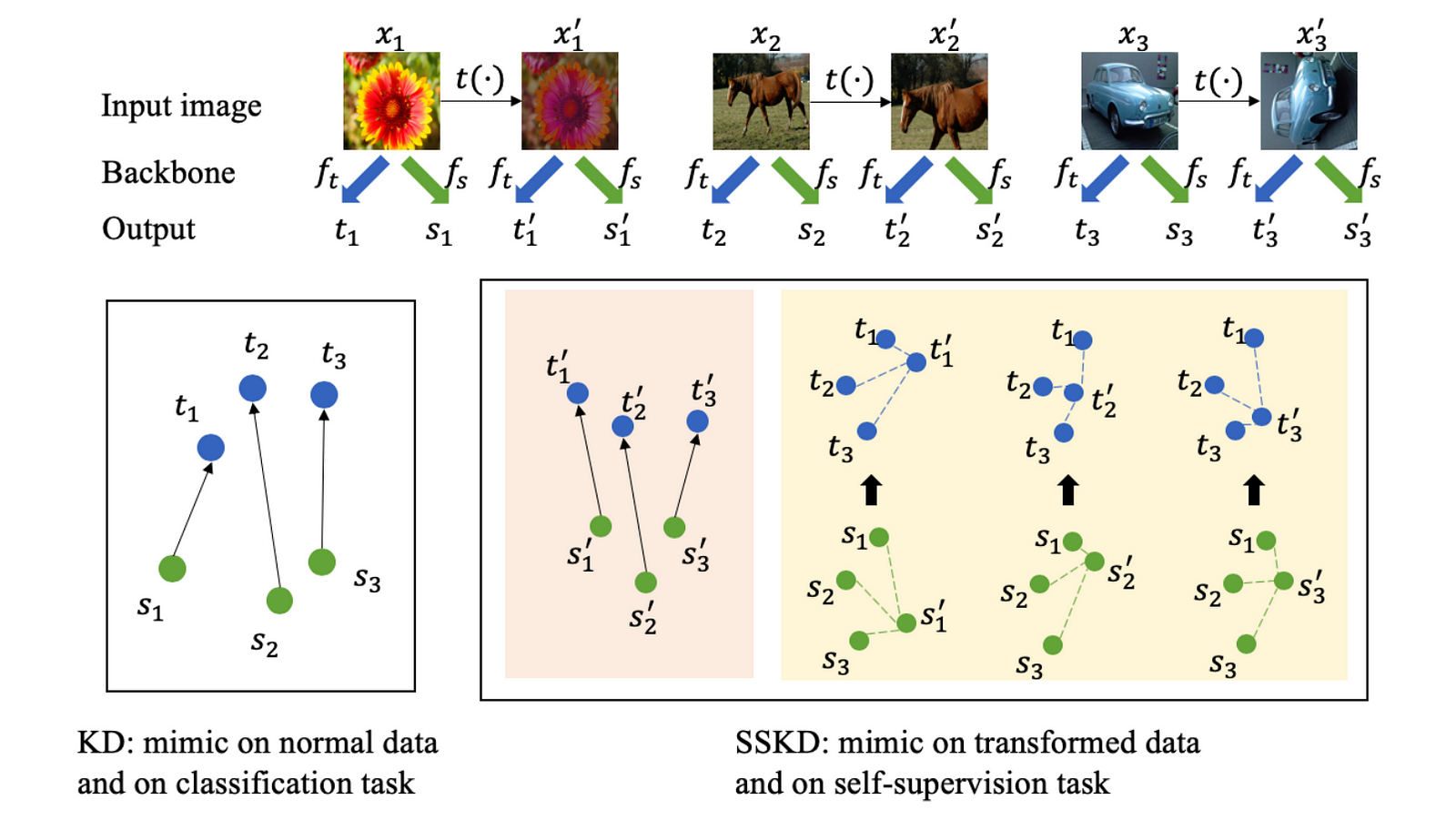 Conventional knowledge distillation (KD) mimics teacher's single prediction on an image. SSKD considers to mimic the predictions of self-supervised contrastive pairs from teacher.
Conventional knowledge distillation (KD) mimics teacher's single prediction on an image. SSKD considers to mimic the predictions of self-supervised contrastive pairs from teacher.
- Different from prior work that exploits architecture-specific cues such as mimicking teacher's features or attentions. This paper instead proposes to mimic teacher's prediction on self-supervised contrastive examples, i.e., similarity scores of positive and negative examples.
- This general and model-agnostic approach achieves SoTA on CIFAR-100 and ImageNet. It also works well under several settings such as few-shot, noisy labels, and especially on cross-architecture setting due to its model-agnostic nature.
- Another benefit is that the distilled knowledge is richen by self-supervised predictions instead of only supervised task-specific predictions, leading to richer distilled knowledge instead of the one that only reflects a single facet of the complete knowledge encapsulated in teacher.
- The main competitor is CRD (Contrastive representation distillation. Tian et al. ICLR 2020). The difference between them is how contrastive task is performed. For example, CRD chooses to maximize the mutual information whereas SSKD adopts SimCLR.
Methods
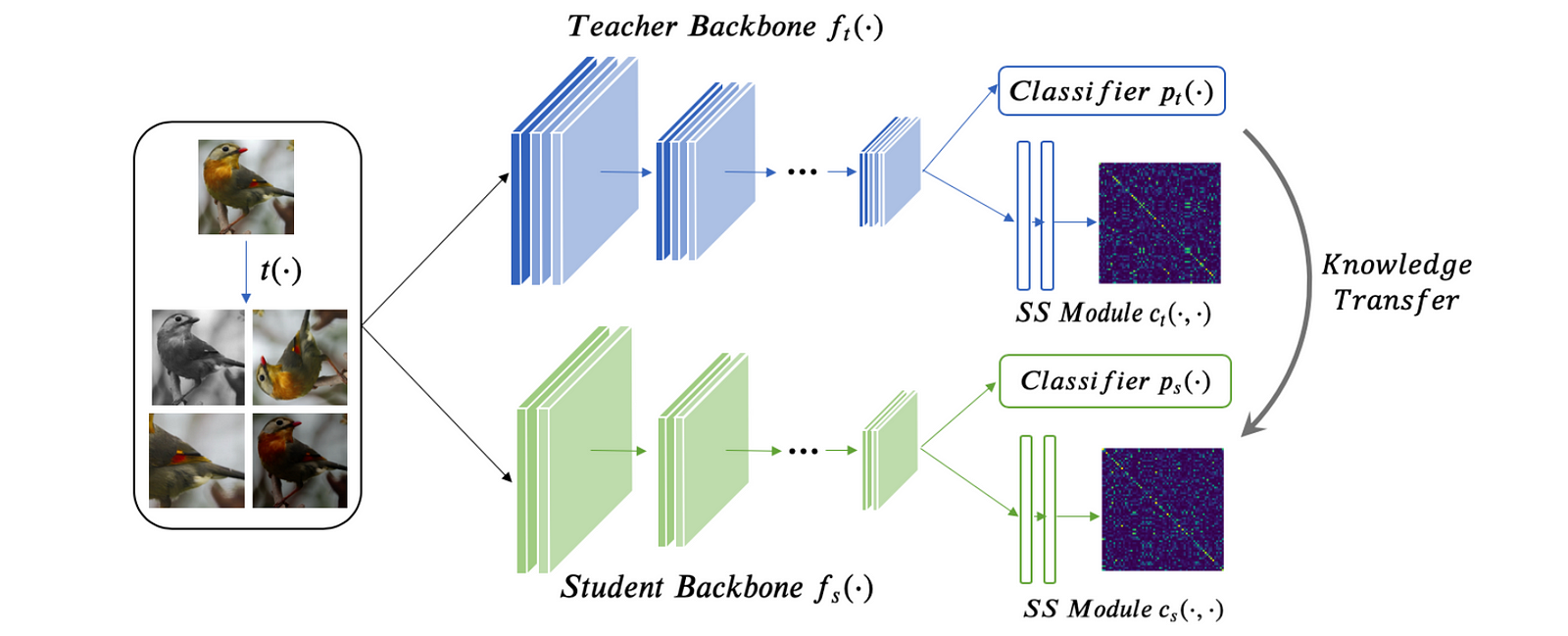
- Stage 1: Train teacher network (backbone & classifier) with supervised task loss on weakly augmented samples (previous work shows that strongly augmented samples harms supervised learning but benefits self-supervised learning).
- Stage 2: Fix teacher network (backbone & classifier), train "SS Module" on SimCLR contrastive task. The SS module is 2-layer MLP projection head on backbone features and its output is basically the pairwise similarity matrix of positive and negative pairs.
- Stage 3: Train student network with (1) supervised task loss on weakly augmented samples (2) knowledge distillation loss matching teacher's output on weakly augmented + strongly augmented samples (3) knowledge distillation loss matching teacher's SS module's output.
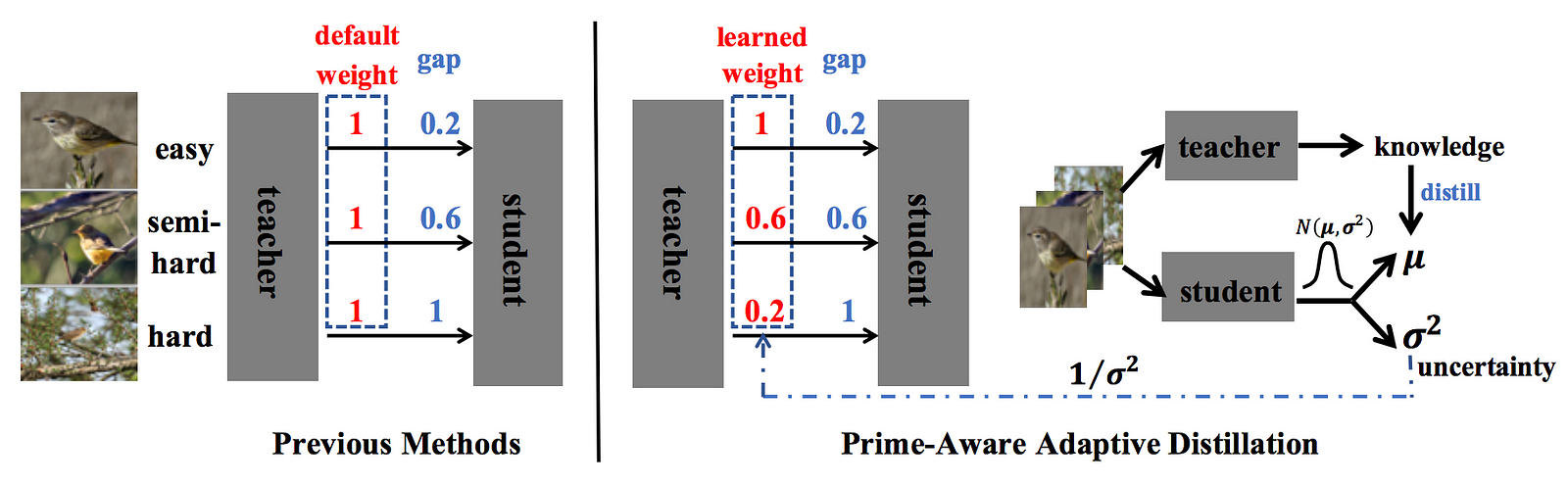
- Filtering incorrect teacher's contrastive predictions (i.e., incorrectly assign higher similarity score to negative pair instead of positive pair). They only transfer correct and top-k% ranked incorrect predictions within a batch. The best performance is achieved by keeping both correct and top-50%~75% incorrect predictions. → Keeping noisy predictions from teacher and not treating all samples equally are important. This leads to our intro to the next paper "Prime-Aware Adaptive Distillation".


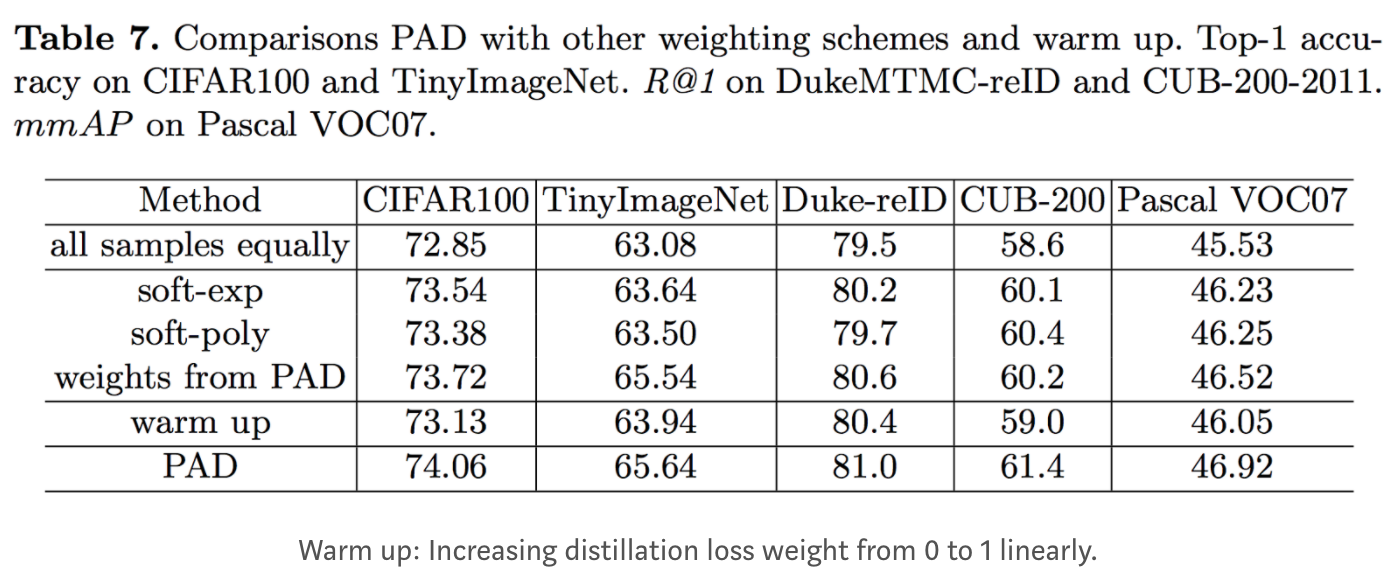
Metadata: Knowledge Distillation Meets Self-Supervision