 gchhablani
commented
3 years ago
gchhablani
commented
3 years ago Hi @hwijeen, you might want to look at issues #1796 and #1949. I think it could be something related to the I/O operations being performed.
Open hwijeen opened 3 years ago
gchhablani
commented
3 years ago Hi @hwijeen, you might want to look at issues #1796 and #1949. I think it could be something related to the I/O operations being performed.
 hwijeen
commented
3 years ago
hwijeen
commented
3 years ago I see that many people are experiencing the same issue. Is this problem considered an "official" bug that is worth a closer look? @lhoestq
 lhoestq
commented
3 years ago
lhoestq
commented
3 years ago Yes this looks like a bug. On my side I haven't managed to reproduce it but @theo-m has. We'll investigate this !
hwijeen
commented
3 years ago Thank you for the reply! I would be happy to follow the discussions related to the issue.
If you do not mind, could you also give a little more explanation on my p.s.2? I am having a hard time figuring out why the single processing map uses all of my cores.
@lhoestq @theo-m
lhoestq
commented
3 years ago Regarding your ps2: It depends what function you pass to map.
For example, fast tokenizers from transformers in Rust tokenize texts and parallelize the tokenization over all the cores.
hwijeen
commented
3 years ago I am still experiencing this issue with datasets 1.9.0.. Has there been a further investigation?

 dduplessis
commented
2 years ago
dduplessis
commented
2 years ago Hi. Is there any update on this issue? I am desperately trying to decrease my times, and multiprocessing "should" be the solution, but it literally takes 5 times longer.
lhoestq
commented
2 years ago Which version of datasets are you using ?
 PaulLerner
commented
1 year ago
PaulLerner
commented
1 year ago Hi,
I’m running into the same issue and trying to come up with a simple benchmark.
I have a total of 80 CPUs.
datasets version: 2.4.0In [1]: from datasets import Dataset, set_caching_enabled
In [2]: import numpy as np
In [3]: set_caching_enabled(False)
In [4]: d = Dataset.from_dict({'foo': np.random.randn(1000,256)})
In [9]: d.set_format('np')
In [14]: def sort(array):
...: np.sort(array)
# multiprocessing disabled
In [19]: %%timeit
...: d.map(sort, input_columns='foo')
78.8 ms ± 1.22 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
# multiprocessing enabled
In [27]: %%timeit
...: d.map(sort, input_columns='foo',num_proc=10)
858 ms ± 45.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each) Spawning multiple processes has an overhead. For small datasets the processing is likely to be faster than spawning the processes and passing the data to them.
Especially since your dataset is in memory: the data has to be copied to the subprocesses. On the other hand, datasets loaded from disk are much faster to reload from a subprocess thanks to memory mapping.
PaulLerner
commented
1 year ago Thanks for the clarifications!
Indeed, when saving then loading the above dataset to disk, and increasing the number of rows to 10K or 100K, the performance gap narrows.
# with 10000 rows
In [3]: %%timeit
...: d.map(sort, input_columns='foo')
578 ms ± 5.89 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [4]: %%timeit
...: d.map(sort, input_columns='foo',num_proc=10)
1.06 s ± 47.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
# with 100000 rows
In [6]: %%timeit
...: d.map(sort, input_columns='foo')
5.8 s ± 25.5 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [7]: %%timeit
...: d.map(sort, input_columns='foo',num_proc=10)
7.23 s ± 154 ms per loop (mean ± std. dev. of 7 runs, 1 loop each hecmay
commented
1 year ago
hecmay
commented
1 year ago any updates on this issue?
I'm using datasets=2.12.0. Adding num_proc to the mapping function makes it at least 5x slower than using a single process.
lhoestq
commented
1 year ago What kind of function are you passing to map ? How many CPUs do you have and what did you set for num_proc ?
 ymoslem
commented
5 months ago
ymoslem
commented
5 months ago Hello! Any solution for this? Thanks!
Hi, thank you for the great library.
I've been using datasets to pretrain language models, and it often involves datasets as large as ~70G. My data preparation step is roughly two steps:
load_datasetwhich splits corpora into a table of sentences, andmapconverts a sentence into a list of integers, using a tokenizer.I noticed that
mapfunction withnum_proc=mp.cpu_count() //2takes more than 20 hours to finish the job where asnum_proc=1gets the job done in about 5 hours. The machine I used has 40 cores, with 126G of RAM. There were no other jobs whenmapfunction was running.What could be the reason? I would be happy to provide information necessary to spot the reason.
p.s. I was experiencing the imbalance issue mentioned in here when I was using multi processing. p.s.2 When I run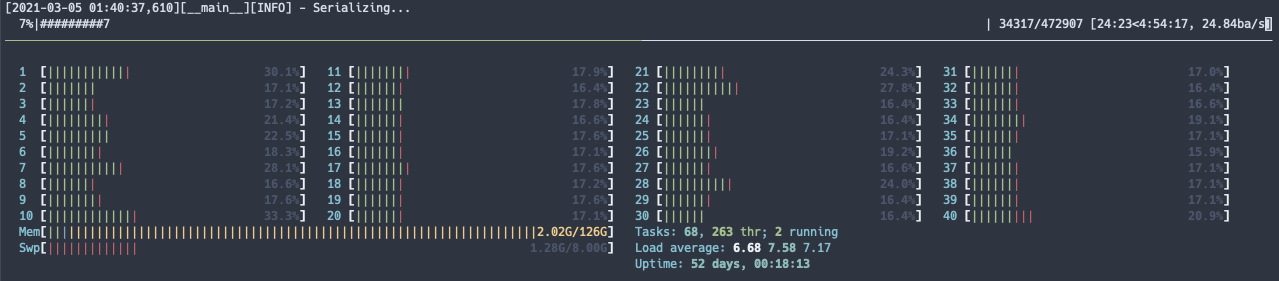
mapwithnum_proc=1, I see one tqdm bar but all the cores are working. Whennum_proc=20, only 20 cores work.