 tomohideshibata
commented
3 years ago
tomohideshibata
commented
3 years ago This is not a problem. When the model predicts the word next to "Ich" (given "Ich"), the word "Ich" cannot attend the words in the future positions (e.g., "will", "ein", etc). However, when the model predicts the word next to "ein" (given "Ich will ein"), the word "Ich" can attend "will" and "ein", which is not cheating. So, the word embeddings of "Ich" in the different right contexts are different.
 voidful
voidful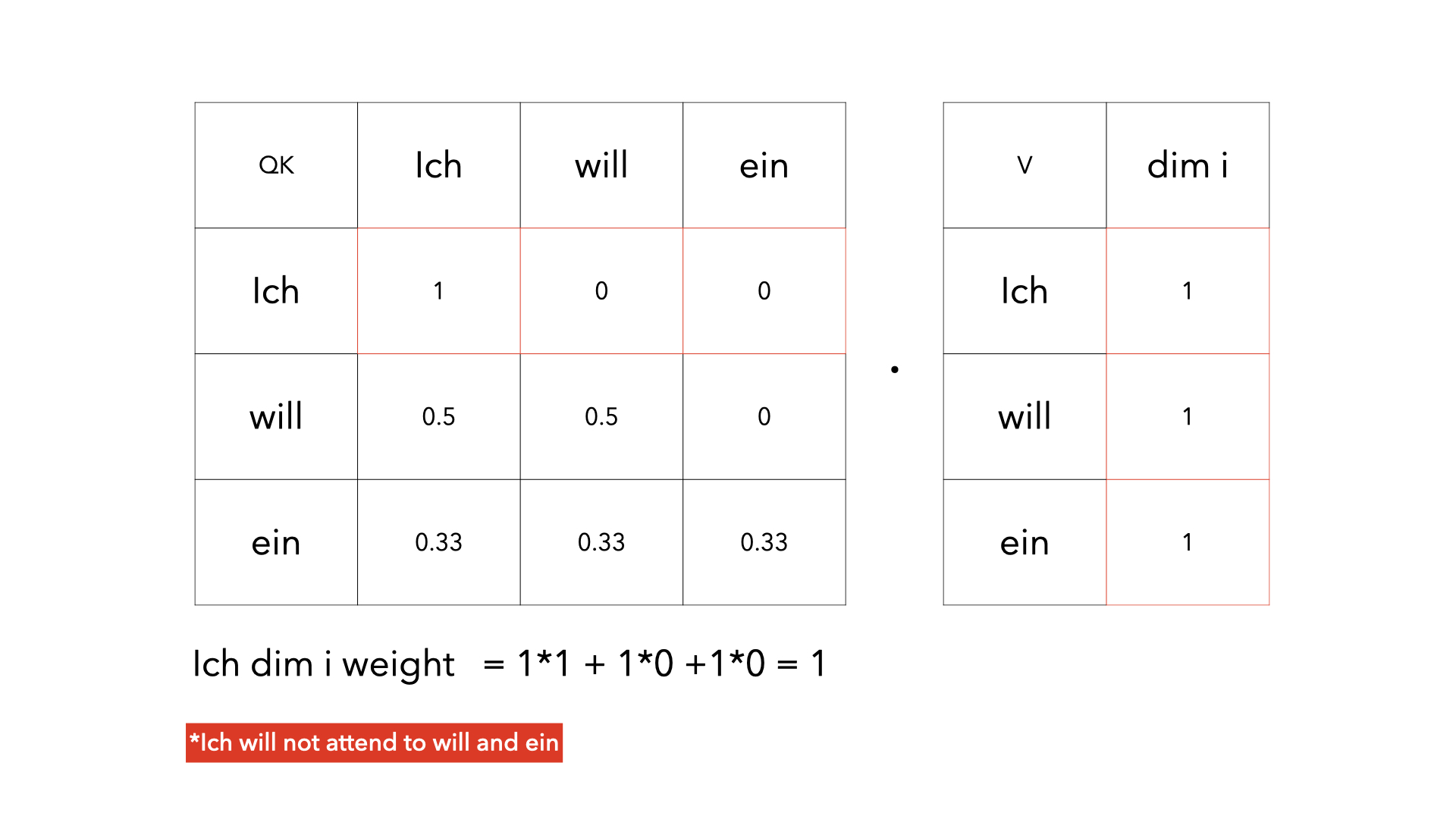
 p208p2002
p208p2002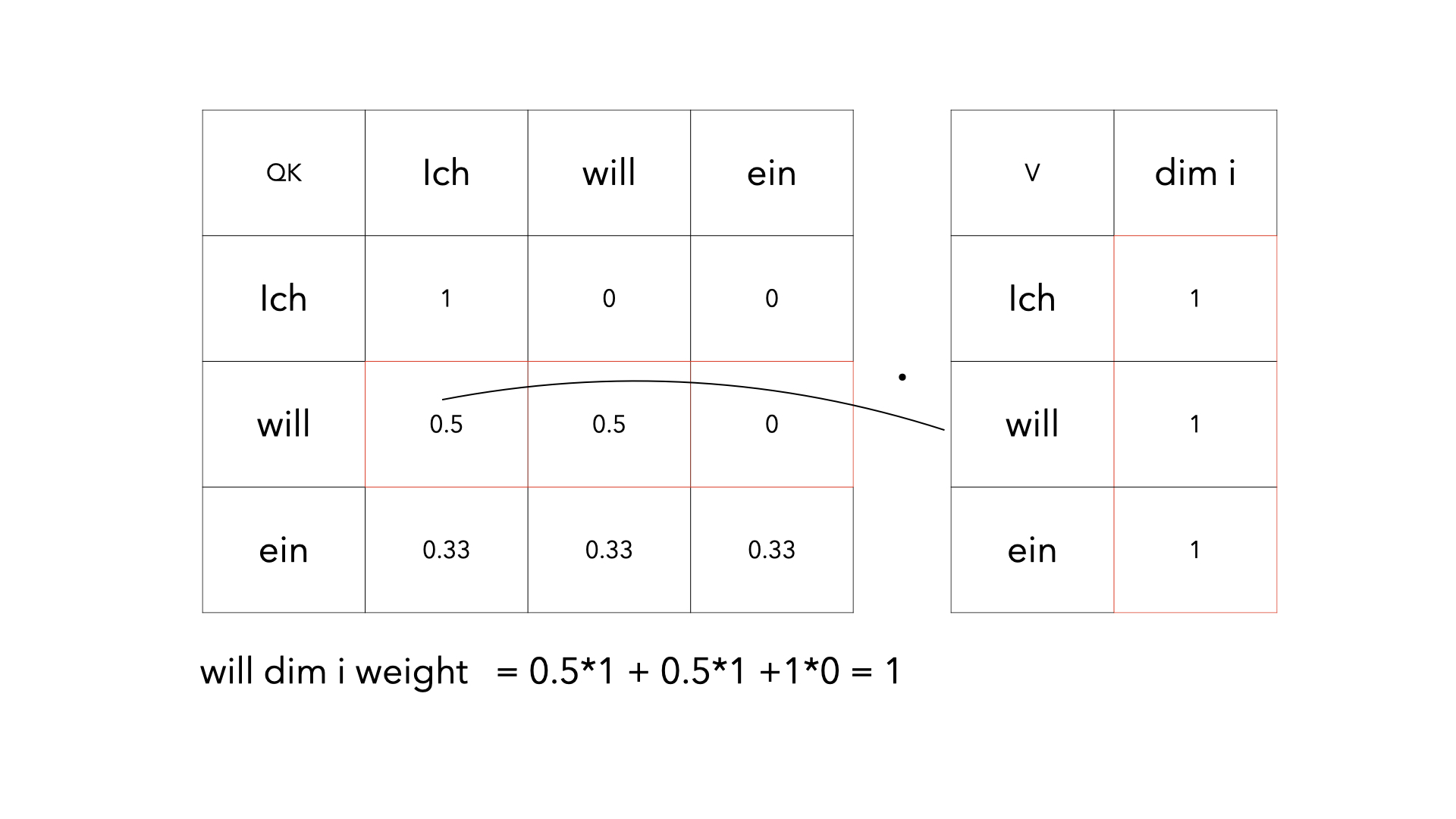
 patrickvonplaten
patrickvonplaten
Problem
Causal Models is only attended to the left context. Therefore causal models should not depend on the right tokens. For example, The word embedding of "I" will be unchanged no matter what is in the right In GPT2. Since Causal Language Model are uni-directional self-attention.
Result
However, when it comes to other models, the result is not following the assumption, the logits will be changed when changing the right side input? What is the reason? Is it a bug? I really want to know the answer, thank you!
BERT
BART
Roberta
Experiment notebook colab
Environment info
transformersversion: 4.3.3Who can help
Information
Model I am using (GPT, Bert, RoBerta, BART ForCausalLM):
The problem arises when using:
To reproduce
Experiment notebook colab
Expected behavior
Causal Models should not be affected by the right context?