 CryptoSalamander
commented
3 years ago
CryptoSalamander
commented
3 years ago In my case, TPU's BF16 datatype caused a fixed loss value. did you use BF16 for training?
Closed prikmm closed 3 years ago
CryptoSalamander
commented
3 years ago In my case, TPU's BF16 datatype caused a fixed loss value. did you use BF16 for training?
 prikmm
commented
3 years ago
prikmm
commented
3 years ago In my case, TPU's BF16 datatype caused a fixed loss value. did you use BF16 for training?
Hey @CryptoSalamander, thanks for your reply. I finally found out the issue. My LR was 0.0, I was under the impression that, AdaSchedule would use the lr in optimizer and change with every step. But, when we use AdaSchedule, we have to pass in the initial_lr or it will default to 0.0 and since relative updates were false (as per the recommendation), the lr remained constant at 0.0.
Environment info
transformersversion: 4.9.0/4.9.1Who can help
@patil-suraj, @sgugger
Information
Model I am using (Bert, XLNet ...): T5
I am trying to finetune T5 on XSum using TPU, but getting near constant training loss and constant validation loss. It's like the model is not learning anything. I tried
t5-small,t5-base,t5-large(on kaggle),google/t5-v1_1-small,google/t5-v1_1-base, but all are giving constant training loss. I applied all the tips from T5 Finetuning Tips thread like using AdaFactor etc. Now, @patil-suraj was able to to traint5-largewithmax_input_length=512,max_output_length=64andbatch_size=8. But, I was also able to traint5-largewithmax_input_length=1024,max_output_length=128andbatch_size=128on kaggle. I don't know why this is happening. Is it because of some of the layers are frozen by default?Loss for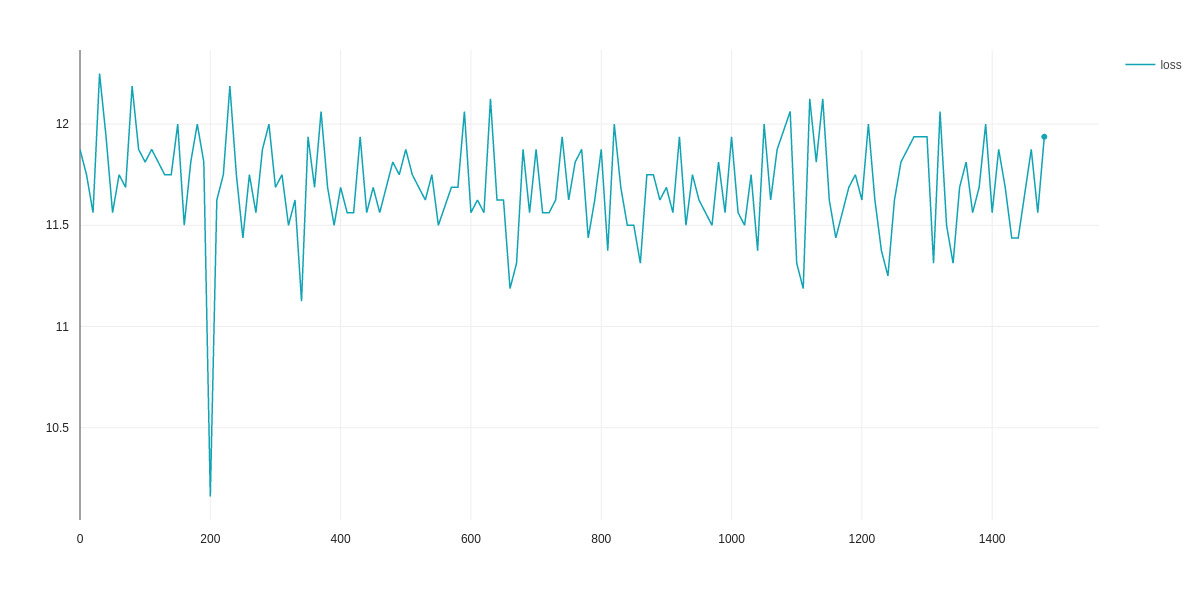
t5-small:Eval Loss for 't5-small`: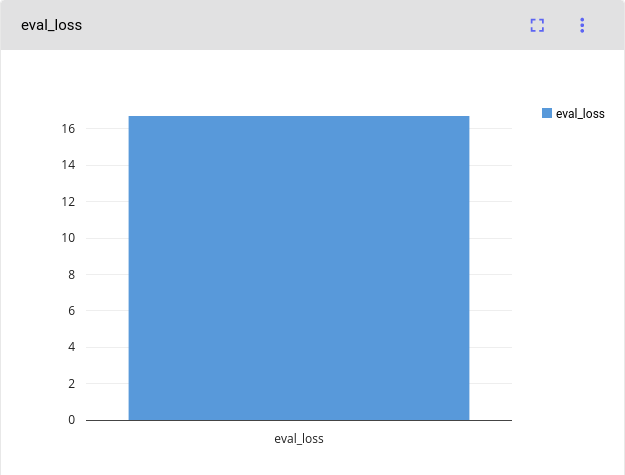
The problem arises when using:
I have modified the script
The tasks I am working on is:
To reproduce
Colab Link
Code bits from Colab for overview:
Dataset Creation:
Model Training:
Expected behavior
Proper Finetuning of T5