 rlouf
commented
5 years ago
rlouf
commented
5 years ago Hi!
First, please check the run_summarization.py script in the example-summarization branch as it is more up-to-date. To answer your questions:
a) We are following this implementation: https://arxiv.org/pdf/1908.08345.pdf where they add an extra [CLS] token for each new sentence.
b) I would need to triple-check the authors’ code, but I hope it does not matter.
c) Good point. If you look at the way the encoder-decoder is implemented you will see that masks passed to the decoder are automatically turned into causal (“look-ahead”), so the code does have the expected behavior :)
 linWujl
linWujl
❓ Questions & Help
Hi, thanks for sharing the code, i was confused about some code and implements when i reading it. a) In run_summarization_finetuning.py, should cls_token_id be replaced by sep_token_id?
b) In utils_summarization.py
should cls_token_id be replaced by sep_token_id?
b) In utils_summarization.py
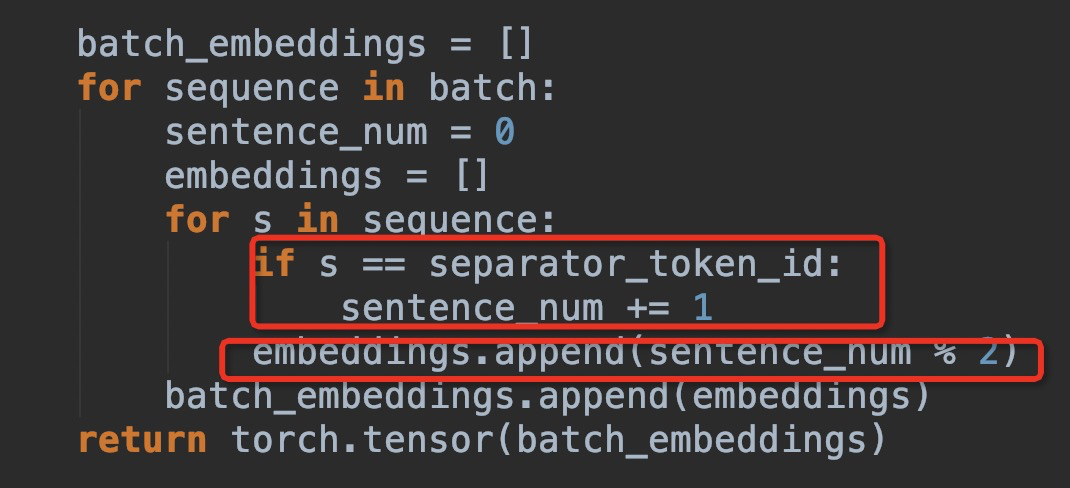 This will make sequence [cls] a b [sep] c d [sep] encoded as 0 0 0 1 1 1 0, should the order be changed?
c) In the decoder, the deocder_mask only mask the pad token, i think look_ahead_mask is more accurate for we can't see the future words in advance.
This will make sequence [cls] a b [sep] c d [sep] encoded as 0 0 0 1 1 1 0, should the order be changed?
c) In the decoder, the deocder_mask only mask the pad token, i think look_ahead_mask is more accurate for we can't see the future words in advance.
Looking forward to reply. Thanks!