edmar
commented
4 years ago
edmar
commented
4 years ago Did you discover any way of doing this?
Closed ramsrigouthamg closed 4 years ago
edmar
commented
4 years ago Did you discover any way of doing this?
 ramsrigouthamg
commented
4 years ago
ramsrigouthamg
commented
4 years ago @edmar Nothing solid yet! I Will update if I do.
 franz101
commented
4 years ago
franz101
commented
4 years ago Also looking for a solution https://github.com/google-research/text-to-text-transfer-transformer/issues/133
ramsrigouthamg
commented
4 years ago @franz101 @edmar The closest thing I could come up with :
from transformers import RobertaTokenizer, RobertaForMaskedLM
import torch
tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
model = RobertaForMaskedLM.from_pretrained('roberta-base')
sentence = "Tom has fully <mask> <mask> <mask> illness."
token_ids = tokenizer.encode(sentence, return_tensors='pt')
# print(token_ids)
token_ids_tk = tokenizer.tokenize(sentence, return_tensors='pt')
print(token_ids_tk)
masked_position = (token_ids.squeeze() == tokenizer.mask_token_id).nonzero()
masked_pos = [mask.item() for mask in masked_position ]
print (masked_pos)
with torch.no_grad():
output = model(token_ids)
last_hidden_state = output[0].squeeze()
print ("\n\n")
print ("sentence : ",sentence)
print ("\n")
list_of_list =[]
for mask_index in masked_pos:
mask_hidden_state = last_hidden_state[mask_index]
idx = torch.topk(mask_hidden_state, k=5, dim=0)[1]
words = [tokenizer.decode(i.item()).strip() for i in idx]
list_of_list.append(words)
print (words)
best_guess = ""
for j in list_of_list:
best_guess = best_guess+" "+j[0]
print ("\nBest guess for fill in the blank :::",best_guess)The output is :
['Tom', 'Ġhas', 'Ġfully', '
sentence : Tom has fully
['recovered', 'returned', 'recover', 'healed', 'cleared'] ['from', 'his', 'with', 'to', 'the'] ['his', 'the', 'her', 'mental', 'this']
Best guess for fill in the blank ::: recovered from his
 Diego999
commented
4 years ago
Diego999
commented
4 years ago @ramsrigouthamg @edmar @franz101 Any update on how to do that ?
ramsrigouthamg
commented
4 years ago @Diego999 The above-provided answer is the best I have. Google hasn't released the pretrained multi-mask fill model.
Diego999
commented
4 years ago @ramsrigouthamg Thanks! This is also similar to BART architecture where they mask a span of text. A similar thread is available here https://github.com/huggingface/transformers/issues/4984
ramsrigouthamg
commented
4 years ago @Diego999 There are few things that you can possibly explore. There is Spanbert https://huggingface.co/SpanBERT/spanbert-base-cased but I didn't explore on how to use it. Then there is Google pegasus that is trained with sentences as masks. https://ai.googleblog.com/2020/06/pegasus-state-of-art-model-for.html
 orena1
commented
4 years ago
orena1
commented
4 years ago This example might be useful: https://github.com/huggingface/transformers/issues/3985
 naveenjafer
commented
4 years ago
naveenjafer
commented
4 years ago @ramsrigouthamg Any luck with it yet on T5?
 stale[bot]
commented
4 years ago
stale[bot]
commented
4 years ago This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
 cccntu
commented
4 years ago
cccntu
commented
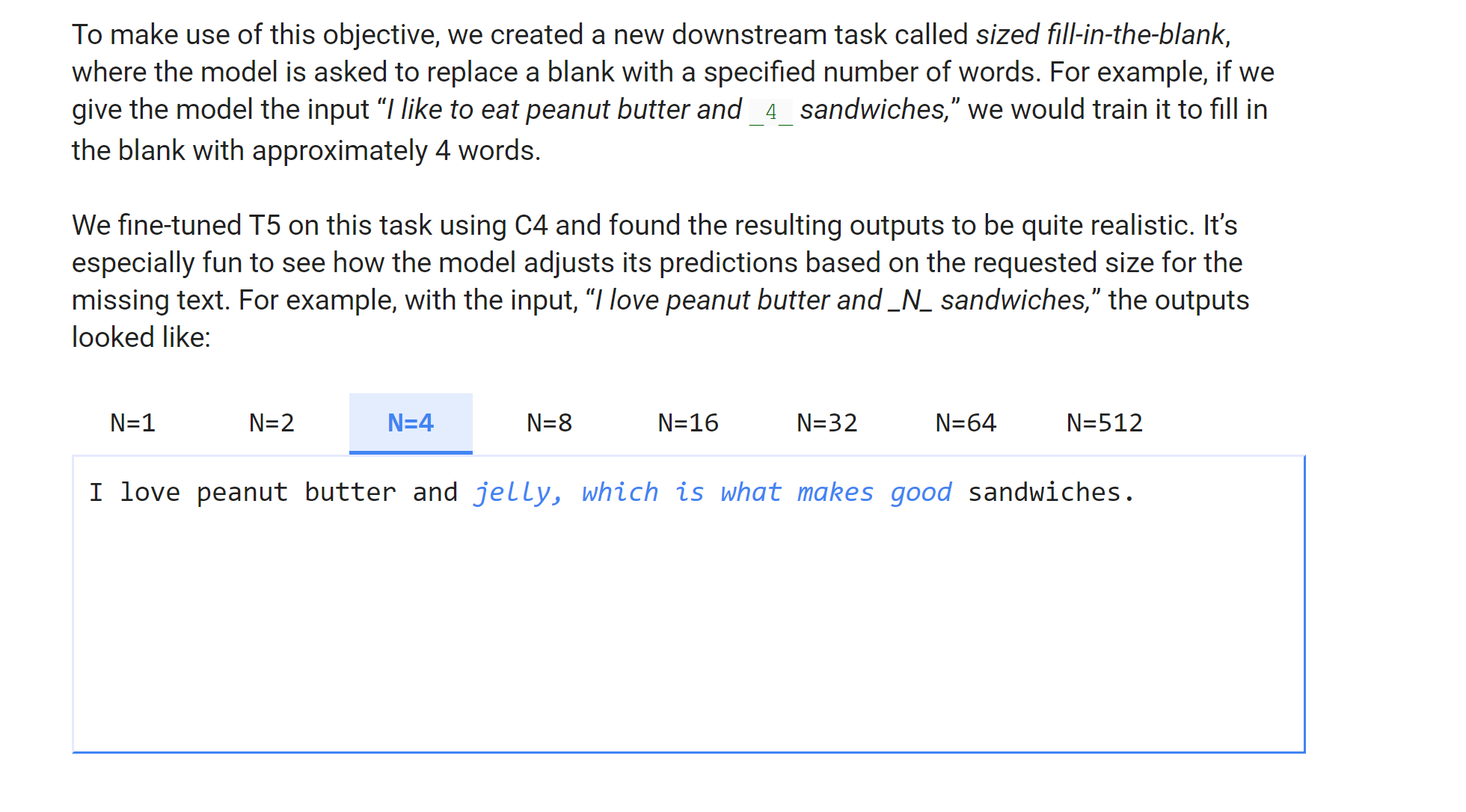
4 years ago I think the __4__ is a special token, and they use the same text to text framework (seq2seq, instead of masked-lm) to train this task.
And that's why the screenshot above says:
train it to fill in the blank with approximately 4 words
 yuchenlin
commented
3 years ago
yuchenlin
commented
3 years ago is there any updates or simple example code for doing this? thanks!
 BigSalmon2
commented
3 years ago
BigSalmon2
commented
3 years ago from transformers import T5Tokenizer, T5Config, T5ForConditionalGeneration
T5_PATH = 't5-base' # "t5-small", "t5-base", "t5-large", "t5-3b", "t5-11b"
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # My envirnment uses CPU
t5_tokenizer = T5Tokenizer.from_pretrained(T5_PATH)
t5_config = T5Config.from_pretrained(T5_PATH)
t5_mlm = T5ForConditionalGeneration.from_pretrained(T5_PATH, config=t5_config).to(DEVICE)
# Input text
text = 'India is a <extra_id_0> of the world. </s>'
encoded = t5_tokenizer.encode_plus(text, add_special_tokens=True, return_tensors='pt')
input_ids = encoded['input_ids'].to(DEVICE)
# Generaing 20 sequences with maximum length set to 5
outputs = t5_mlm.generate(input_ids=input_ids,
num_beams=200, num_return_sequences=20,
max_length=5)
_0_index = text.index('<extra_id_0>')
_result_prefix = text[:_0_index]
_result_suffix = text[_0_index+12:] # 12 is the length of <extra_id_0>
def _filter(output, end_token='<extra_id_1>'):
# The first token is <unk> (inidex at 0) and the second token is <extra_id_0> (indexed at 32099)
_txt = t5_tokenizer.decode(output[2:], skip_special_tokens=False, clean_up_tokenization_spaces=False)
if end_token in _txt:
_end_token_index = _txt.index(end_token)
return _result_prefix + _txt[:_end_token_index] + _result_suffix
else:
return _result_prefix + _txt + _result_suffix
results = list(map(_filter, outputs))
results mishav78
commented
2 years ago
mishav78
commented
2 years ago does the above work?
In the Google T5 paper they mentioned : For example, with the input, “I love peanut butter and 4 sandwiches,” the outputs looked like: I love peanut butter and jelly, which is what makes good sandwiches.
How do I achieve Multi Mask filling with T5 in hugging face transformers? Code samples please :)