 wicebing
commented
4 years ago
wicebing
commented
4 years ago I had this problem today,too. I create a new container as my new gpu environment, but cannot load any pretrained due to this error, but the same load pretrained codes are normal run on my old enviroment to download the pretrained
 LysandreJik
LysandreJik manueltonneau
manueltonneau
 elyesmanai
elyesmanai
 julien-c
julien-c D-i-l-r-u-k-s-h-i
D-i-l-r-u-k-s-h-i fathia-ghribi
fathia-ghribi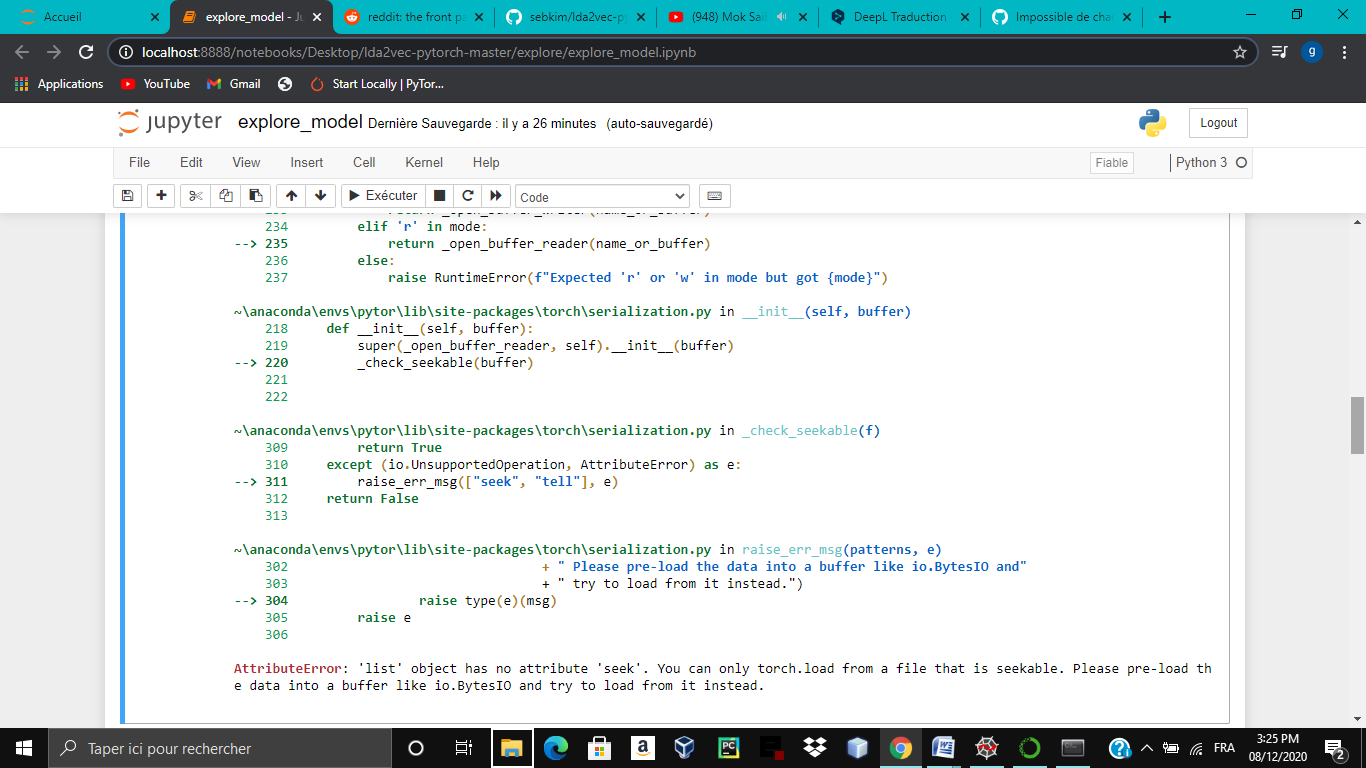 how to resolve it ?? someone help me plz
how to resolve it ?? someone help me plz brent-lemieux
brent-lemieux da-head0
da-head0 mrelmi
mrelmi marcosbodio
marcosbodio BitnaKeum
BitnaKeum foton263
foton263 ShineYull
ShineYull tothandor
tothandor zzd2001
zzd2001 JaosonMa
JaosonMa
🐛 Bug
Information
I uploaded two models this morning using the
transformers-cli. The models can be found on my huggingface page. The folder I uploaded for both models contained a PyTorch model in bin format, a zip file containing the three TF model files, theconfig.jsonand thevocab.txt. The PT model was created from TF checkpoints using this code. I'm able to download the tokenizer using:tokenizer = AutoTokenizer.from_pretrained("mananeau/clinicalcovid-bert-base-cased").Yet, when trying to download the model using:
model = AutoModel.from_pretrained("mananeau/clinicalcovid-bert-base-cased")I am getting the following error:
AttributeError Traceback (most recent call last) ~/anaconda3/lib/python3.7/site-packages/torch/serialization.py in _check_seekable(f) 226 try: --> 227 f.seek(f.tell()) 228 return True
AttributeError: 'NoneType' object has no attribute 'seek'
During handling of the above exception, another exception occurred:
AttributeError Traceback (most recent call last) ~/anaconda3/lib/python3.7/site-packages/transformers/modeling_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs) 625 try: --> 626 state_dict = torch.load(resolved_archive_file, map_location="cpu") 627 except Exception:
~/anaconda3/lib/python3.7/site-packages/torch/serialization.py in load(f, map_location, pickle_module, pickle_load_args) 425 pickle_load_args['encoding'] = 'utf-8' --> 426 return _load(f, map_location, pickle_module, pickle_load_args) 427 finally:
~/anaconda3/lib/python3.7/site-packages/torch/serialization.py in _load(f, map_location, pickle_module, **pickle_load_args) 587 --> 588 _check_seekable(f) 589 f_should_read_directly = _should_read_directly(f)
~/anaconda3/lib/python3.7/site-packages/torch/serialization.py in _check_seekable(f) 229 except (io.UnsupportedOperation, AttributeError) as e: --> 230 raise_err_msg(["seek", "tell"], e) 231
~/anaconda3/lib/python3.7/site-packages/torch/serialization.py in raise_err_msg(patterns, e) 222 " try to load from it instead.") --> 223 raise type(e)(msg) 224 raise e
AttributeError: 'NoneType' object has no attribute 'seek'. You can only torch.load from a file that is seekable. Please pre-load the data into a buffer like io.BytesIO and try to load from it instead.
During handling of the above exception, another exception occurred:
OSError Traceback (most recent call last)