 NielsRogge
commented
4 years ago
NielsRogge
commented
4 years ago To save your model, first create a directory in which everything will be saved. In Python, you can do this as follows:
import os
os.makedirs("path/to/awesome-name-you-picked")Next, you can use the model.save_pretrained("path/to/awesome-name-you-picked") method. This will save the model, with its weights and configuration, to the directory you specify. Next, you can load it back using model = .from_pretrained("path/to/awesome-name-you-picked").
Source: https://huggingface.co/transformers/model_sharing.html
 wmathor
wmathor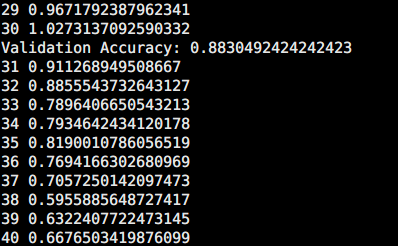
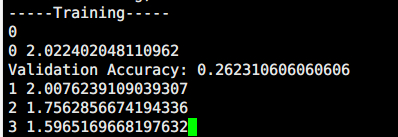
 fakerbrother
fakerbrother cedar33
cedar33 GregRoq
GregRoq julien-c
julien-c osanseviero
osanseviero
 Zhongli2002
Zhongli2002 Nikita-Shrma
Nikita-Shrma
❓ Questions & Help
Details
I have defined my model via huggingface, but I don't know how to save and load the model, hopefully someone can help me out, thanks!