 stas00
commented
3 years ago
stas00
commented
3 years ago Thank you, @alexorona!
I'm still in the process of gathering info/reading up and doing some small experimentation, so will post my thoughts once I have something concrete to share.
Here are some resources if someone wants to join in:
Abbreviations:
- MP = Model Parallelism
- DP = Data Parallelism
- PP = Pipeline Parallelism
Resources:
-
Parallel and Distributed Training tutorials at pytorch - a handful, starting with https://pytorch.org/tutorials/beginner/dist_overview.html
-
fairscale
- github https://github.com/facebookresearch/fairscale
- the MP part of fairscale is a fork of https://github.com/NVIDIA/Megatron-LM
-
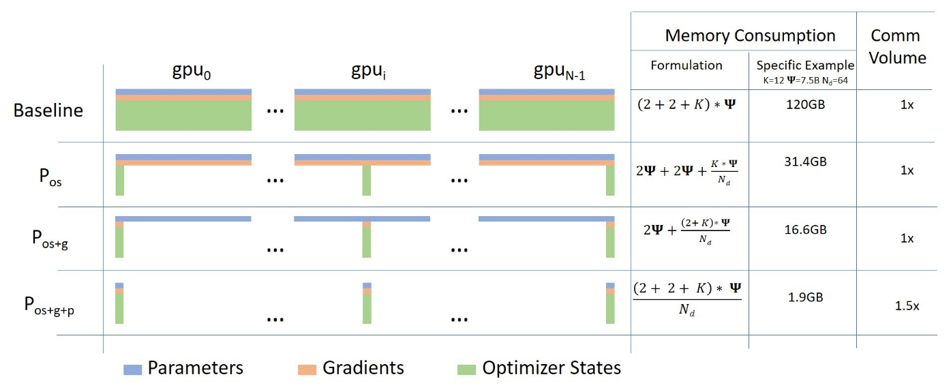
ZeRO and deepspeed:
- paper ZeRO: Memory Optimizations Toward Training Trillion Parameter Models https://arxiv.org/abs/1910.02054
- paper ZeRO-Offload: Democratizing Billion-Scale Model Training https://arxiv.org/abs/1910.02054
- detailed blog posts with diagrams:
- https://www.microsoft.com/en-us/research/blog/deepspeed-extreme-scale-model-training-for-everyone/
- https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/
- https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/
- github https://github.com/microsoft/DeepSpeed
- deepspeed examples git https://github.com/microsoft/DeepSpeedExamples
- deepspeed in PL https://github.com/PyTorchLightning/pytorch-lightning/issues/817
- deepspeed in PT https://github.com/pytorch/pytorch/issues/42849
- discussion of the paper with visuals https://www.youtube.com/watch?v=tC01FRB0M7w
-
Pipeline Parallelism
- DeepSpeed https://www.deepspeed.ai/tutorials/pipeline/
- Fairscale https://fairscale.readthedocs.io/en/latest/api/nn/pipe.html
- GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism https://arxiv.org/abs/1811.06965
- PipeDream: Fast and Efficient Pipeline Parallel DNN Training https://arxiv.org/abs/1806.03377
 alexorona
alexorona g-karthik
g-karthik julien-c
julien-c
 blefaudeux
blefaudeux PeterAJansen
PeterAJansen
 sgugger
sgugger mxa4646
mxa4646 ghost
ghost
🚀 Feature request
This is a discussion issue for training/fine-tuning very large transformer models. Recently, model parallelism was added for gpt2 and t5. The current implementation is for PyTorch only and requires manually modifying the model classes for each model. Possible routes (thanks to @stas00 for identifying these):
fairscaleto avoid individual model implementationdeepspeedto possibly enable even larger models to be trained