 LysandreJik
commented
5 years ago
LysandreJik
commented
5 years ago Hi!
If you saved the model BertForMultipleChoice to a directory, you can then load the weights for the BertForMaskedLM by simply using the from_pretrained(dir_name) method. The transformer weights will be re-used by the BertForMaskedLM and the weights corresponding to the multiple-choice classifier will be ignored.
 XuhuiZhou
XuhuiZhou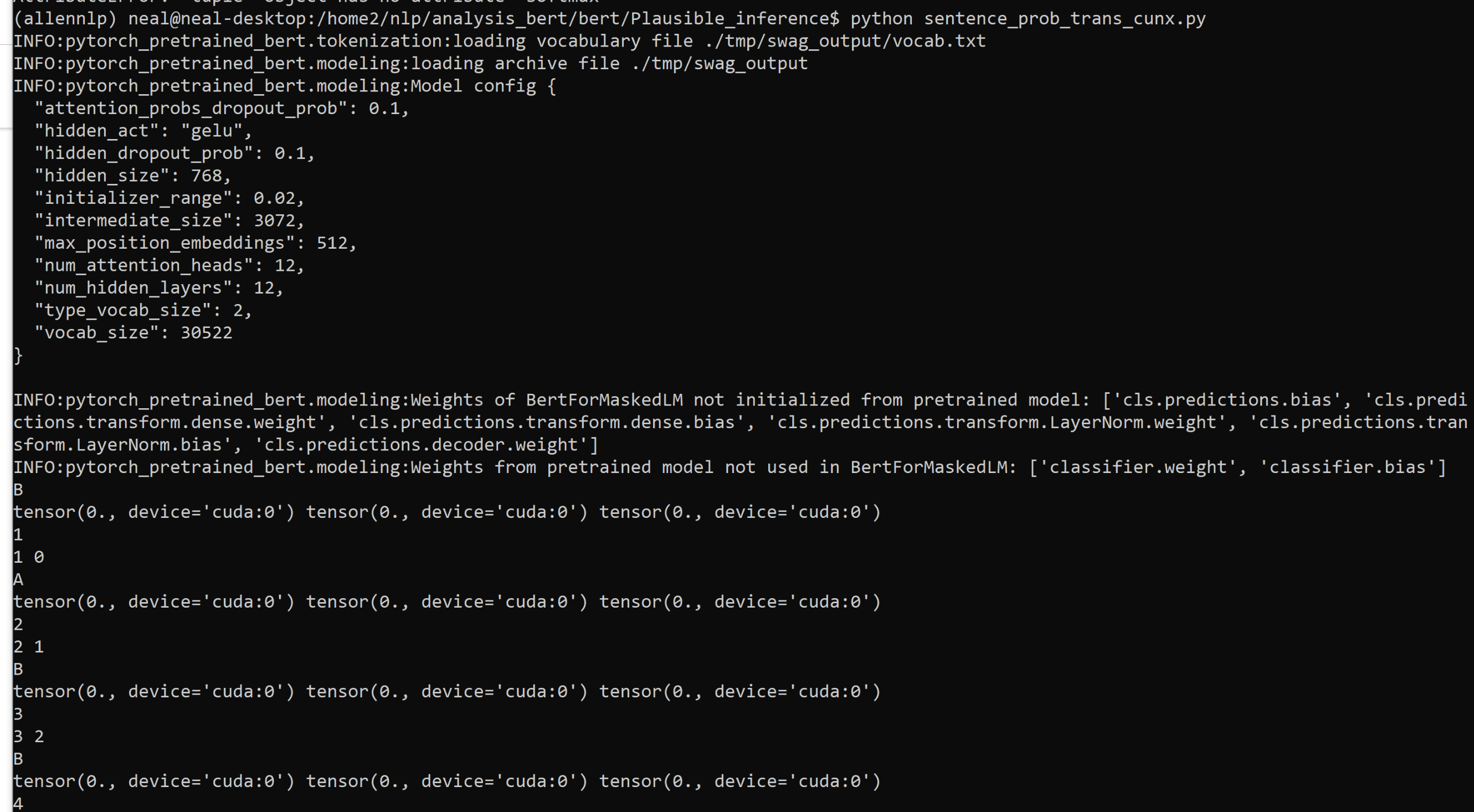 As you can see, the output tensors are all zeros, which seems to be really weird!
As you can see, the output tensors are all zeros, which seems to be really weird! 
 thomwolf
thomwolf
 stale[bot]
stale[bot]
Hi, I am currently using this code to research the transferability of those pre-trained models and I wonder how could I apply the fine-tuned parameter of a model to another model. For example, I fine-tuned the BertForMultipleChoice and got the pytorch_model.bin, and what if I want to use the parameters weight above in the BertForMaskedLM.
I believed there should exist a way to do that since they just differ in the linear layer. However, simply use the BertForMaskedLM.from_pretrained method is problematic.