 gudongfeng
commented
7 years ago
gudongfeng
commented
7 years ago There are some variable reuse problems with multiple GPU support, I have fixed them before, but the performance doesn't increase (even decrease with multiple GPU) so I just leave it like this. I think the better choice is to use single GPU for computing. If you really want to use multiple GPU, you need to fix the variable reuse problem first and then figure out the performance problem. Check my fork for this project, maybe this could help you better understand the project. Cheers. @kcheng999
 kcheng999
kcheng999 joefang66
joefang66 hx173149
hx173149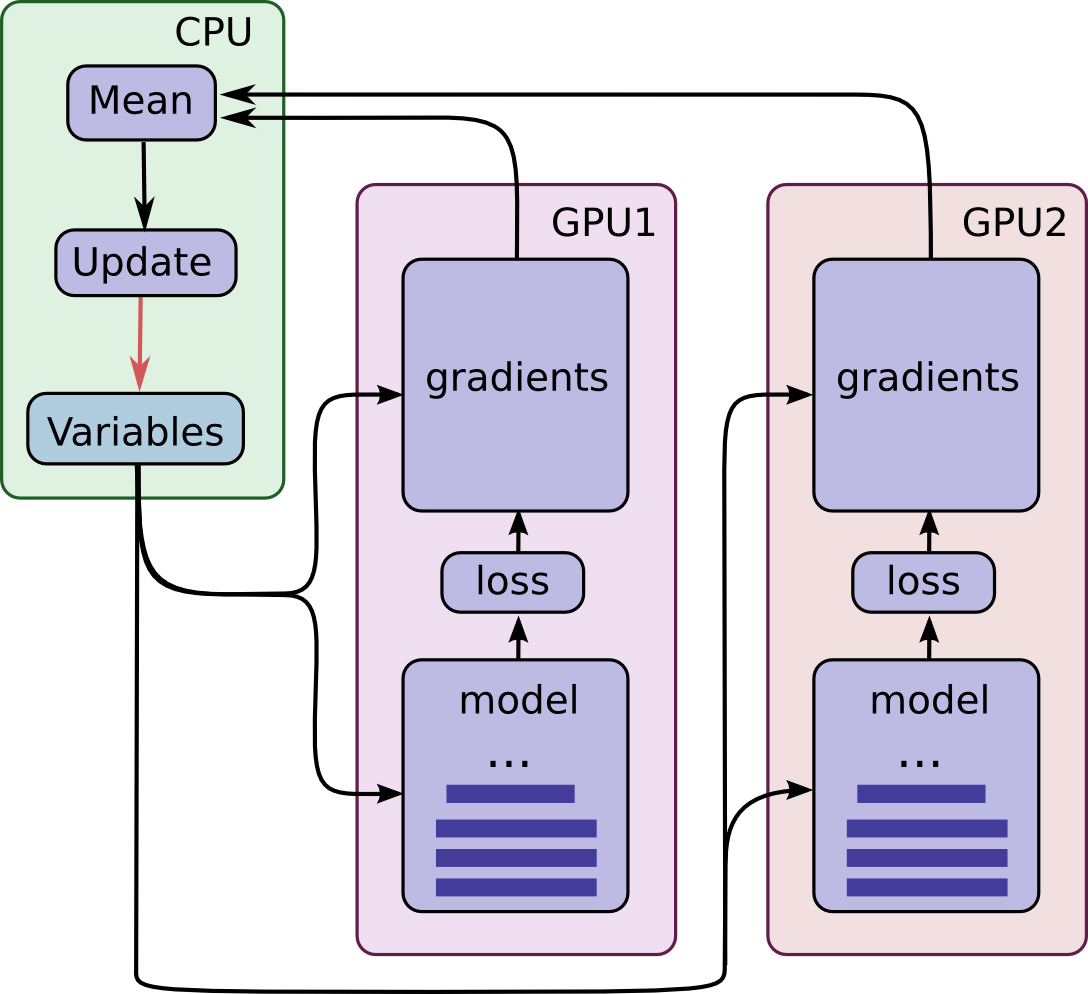{kind=link}
I used your code in my own dataset. Your code works well when gpu_num=1. But when I set gpu_num=2, I get an error:
Traceback (most recent call last): File "train_c3d_ucf101.py", line 344, in
tf.app.run()
File "/mnt/xfs1/home/zhangyifan/anaconda2/lib/python2.7/site-packages/tensorflow/python/platform/app.py", line 48, in run
_sys.exit(main(_sys.argv[:1] + flags_passthrough))
File "train_c3d_ucf101.py", line 341, in main
run_training()
File "train_c3d_ucf101.py", line 202, in run_training
labels_placeholder[gpu_index FLAGS.batch_size:(gpu_index + 1) FLAGS.batch_size]
File "train_c3d_ucf101.py", line 97, in tower_loss
loss_averages_op = loss_averages.apply(losses + [total_loss])
File "/mnt/xfs1/home/zhangyifan/anaconda2/lib/python2.7/site-packages/tensorflow/python/training/moving_averages.py", line 375, in apply
colocate_with_primary=(var.op.type in ["Variable", "VariableV2"]))
File "/mnt/xfs1/home/zhangyifan/anaconda2/lib/python2.7/site-packages/tensorflow/python/training/slot_creator.py", line 174, in create_zeros_slot
colocate_with_primary=colocate_with_primary)
File "/mnt/xfs1/home/zhangyifan/anaconda2/lib/python2.7/site-packages/tensorflow/python/training/slot_creator.py", line 149, in create_slot_with_initializer
dtype)
File "/mnt/xfs1/home/zhangyifan/anaconda2/lib/python2.7/site-packages/tensorflow/python/training/slot_creator.py", line 66, in _create_slot_var
validate_shape=validate_shape)
File "/mnt/xfs1/home/zhangyifan/anaconda2/lib/python2.7/site-packages/tensorflow/python/ops/variable_scope.py", line 1049, in get_variable
use_resource=use_resource, custom_getter=custom_getter)
File "/mnt/xfs1/home/zhangyifan/anaconda2/lib/python2.7/site-packages/tensorflow/python/ops/variable_scope.py", line 948, in get_variable
use_resource=use_resource, custom_getter=custom_getter)
File "/mnt/xfs1/home/zhangyifan/anaconda2/lib/python2.7/site-packages/tensorflow/python/ops/variable_scope.py", line 356, in get_variable
validate_shape=validate_shape, use_resource=use_resource)
File "/mnt/xfs1/home/zhangyifan/anaconda2/lib/python2.7/site-packages/tensorflow/python/ops/variable_scope.py", line 341, in _true_getter
use_resource=use_resource)
File "/mnt/xfs1/home/zhangyifan/anaconda2/lib/python2.7/site-packages/tensorflow/python/ops/variable_scope.py", line 671, in _get_single_variable
"VarScope?" % name)
ValueError: Variable IVA-research_1/var_name/weight_loss/loss/ does not exist, or was not created with tf.get_variable(). Did you mean to set reuse=None in VarScope?
I am really confused, could you please help me ? @hx173149 @frankgu