Experience라고 부르는데, 이것은 사용자 로그성+ 클릭한 문서?상품의 정보로 볼 수 있을 듯 하다.
Experience duration (e.g. 1h, 2h, 3h, etc.)
Price and Price-per-hour
Category (e.g. cooking class, music, surfing, etc.)
Reviews (rating, number of reviews)
Number of bookings (last 7 days, last 30 days)
Occupancy of past and future instances (e.g. 60%)
Maximum number of seats (e.g. max 5 people can attend)
Click-through rate
binary 분류 문제로 보고, 사용자 데이터로부터 (클릭하고 예약을한것/안한것)으로 positive/negative 셋을 확보했다.( 가장 처음 시작해볼 수 있지만,,, 과연? 하지만 이런 바이너리 문제로 본다면 잘될지도 모르겠다)
GBDT모델로 바이너리 분류 모델링을 하고 AUC, NDCG로 평가함
*binary인데 ndcg로 어떻게 했을가. MAP , P@5/10 정도로 하는것도 좋을것 같다.
아래와 같은 결과(Feature의 중요도 정도를 평가한듯 보인다)
저렴한가격일수록, 높은 리뷰점수일 수록 높은 평가를 받는다는 것이다.
하지만 검색 조건(숙박인수, 장소 등과 같은 query parameter 등의 피쳐가 들어가지 않음으로 진행됨
위에서 생긴 요구를 더하기 위해 사용자의 성향을 반영하기 위해 개인화를 더한 모델을 진행했다.
아래와 같은 피쳐를 사용했고, 이전 예약에 대한 사용자로그에서 뽑아냈다.
Booked Home location
Trip dates
Trip length
Number of guests
Trip price (Below/Above Market)
Type of trip: Family, Business
First trip or returning to location
Domestic / International trip
Lead days
몇가지 중요하게 생각한 피쳐들이라고 한다.
예약한 위치와의 거리(가까울 수록, 위경도를 이용해서 계산)
예약한 일정에서 가능한 상품일 수록
사용자의 관심 카테고리 반영
category intensity
category recency
유저의 주 관심 카테고리를 반용하고자 만든듯하다.(모든 상품은 카테고리를 갖는다. 아래와 같은 수식이란다)
또 사용자의 관심도는 매번 변하는 것을 반영하기 위해 마지막 클릭한 시간을 가지고 recency를 반영한다.
마지막 클릭 관심카테고리에서 시간이 흐를수록 낮은 category intensity를 반영하는 듯 하다.
https://www.desmos.com/calculator/peukacr28d
https://medium.com/airbnb-engineering/machine-learning-powered-search-ranking-of-airbnb-experiences-110b4b1a0789?fbclid=IwAR17BvafUZXfEMtFcWOFytQzzHgn_CI51d2rGAsgcmVtP22YUPb_Psd5SGw
기계학습을 이용해서 검색 랭킹을 다룬 내용.
Experience라고 부르는데, 이것은 사용자 로그성+ 클릭한 문서?상품의 정보로 볼 수 있을 듯 하다. Experience duration (e.g. 1h, 2h, 3h, etc.) Price and Price-per-hour Category (e.g. cooking class, music, surfing, etc.) Reviews (rating, number of reviews) Number of bookings (last 7 days, last 30 days) Occupancy of past and future instances (e.g. 60%) Maximum number of seats (e.g. max 5 people can attend) Click-through rate
binary 분류 문제로 보고, 사용자 데이터로부터 (클릭하고 예약을한것/안한것)으로 positive/negative 셋을 확보했다.( 가장 처음 시작해볼 수 있지만,,, 과연? 하지만 이런 바이너리 문제로 본다면 잘될지도 모르겠다)
GBDT모델로 바이너리 분류 모델링을 하고 AUC, NDCG로 평가함 *binary인데 ndcg로 어떻게 했을가. MAP , P@5/10 정도로 하는것도 좋을것 같다.
아래와 같은 결과(Feature의 중요도 정도를 평가한듯 보인다) 저렴한가격일수록, 높은 리뷰점수일 수록 높은 평가를 받는다는 것이다. 하지만 검색 조건(숙박인수, 장소 등과 같은 query parameter 등의 피쳐가 들어가지 않음으로 진행됨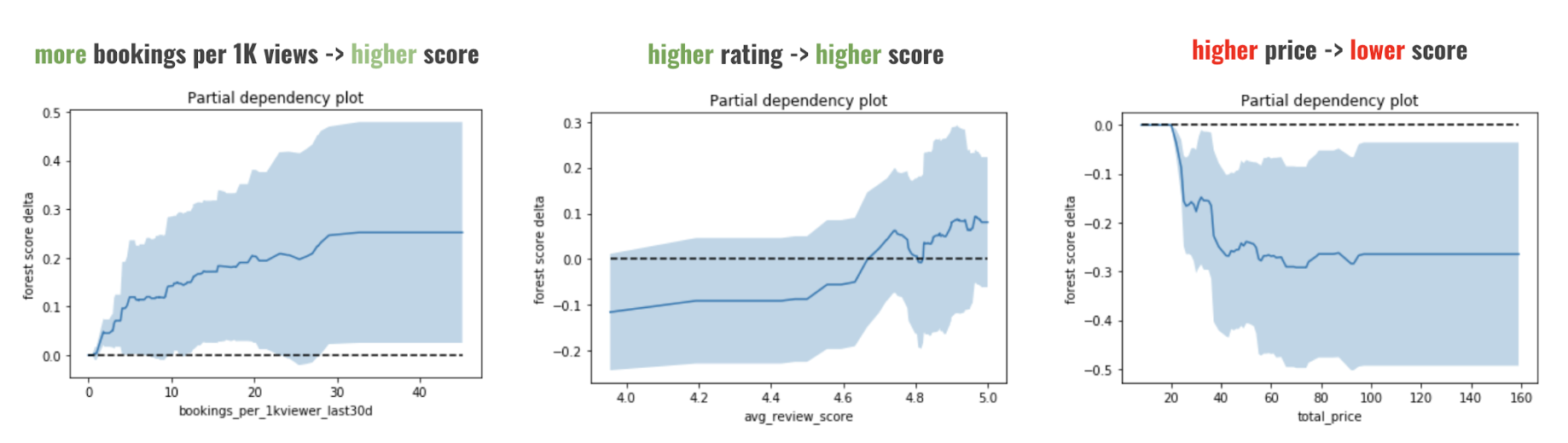
위에서 생긴 요구를 더하기 위해 사용자의 성향을 반영하기 위해 개인화를 더한 모델을 진행했다.
아래와 같은 피쳐를 사용했고, 이전 예약에 대한 사용자로그에서 뽑아냈다. Booked Home location Trip dates Trip length Number of guests Trip price (Below/Above Market) Type of trip: Family, Business First trip or returning to location Domestic / International trip Lead days
몇가지 중요하게 생각한 피쳐들이라고 한다. 예약한 위치와의 거리(가까울 수록, 위경도를 이용해서 계산) 예약한 일정에서 가능한 상품일 수록
사용자의 관심 카테고리 반영 category intensity category recency 유저의 주 관심 카테고리를 반용하고자 만든듯하다.(모든 상품은 카테고리를 갖는다. 아래와 같은 수식이란다) 또 사용자의 관심도는 매번 변하는 것을 반영하기 위해 마지막 클릭한 시간을 가지고 recency를 반영한다. 마지막 클릭 관심카테고리에서 시간이 흐를수록 낮은 category intensity를 반영하는 듯 하다. https://www.desmos.com/calculator/peukacr28d