 piconti
commented
10 months ago
piconti
commented
10 months ago Small update regarding SWA:
Notes and discussions from Impresso I were found and contain the following information: (NB: it's not assured this information is still correct).
- The IIIF presentation API is at the following address: https://ub-iiifpresentation.ub.unibas.ch/impresso_sb/collection/
- From there, one can access the json manifests corresponding to specific titles:
- Within these manifests, the list of individual issues is under
manifests, where the keyidholds the link to the specific issue's JSON manifest:- https://ub-iiifpresentation.ub.unibas.ch/impresso_sb/handelsztg-0001-a-issue/manifest/
- Each issue's JSON manifest contains metadata about the issue, including iiif links to images or Alto XMLs, but none seem to work (image iiif links yield 404 errors, Alto XML links yield 403 (forbidden) errors, and "service" links are the same as the ones contained in the canonical data).
Unfortunately, the information at disposal does not mention the links not working.
We can reach another JSON manifest by adding ".tif" to the end of the current links. Adding ".jp2" or ".png" yields 403 errors again, so it's probably that only authenticated users can access them. It is still unclear if the links in the canonical data were left as-is on purpose, or were supposed to be modified to map to the JP2000.
 simon-clematide
simon-clematide e-maud
e-maud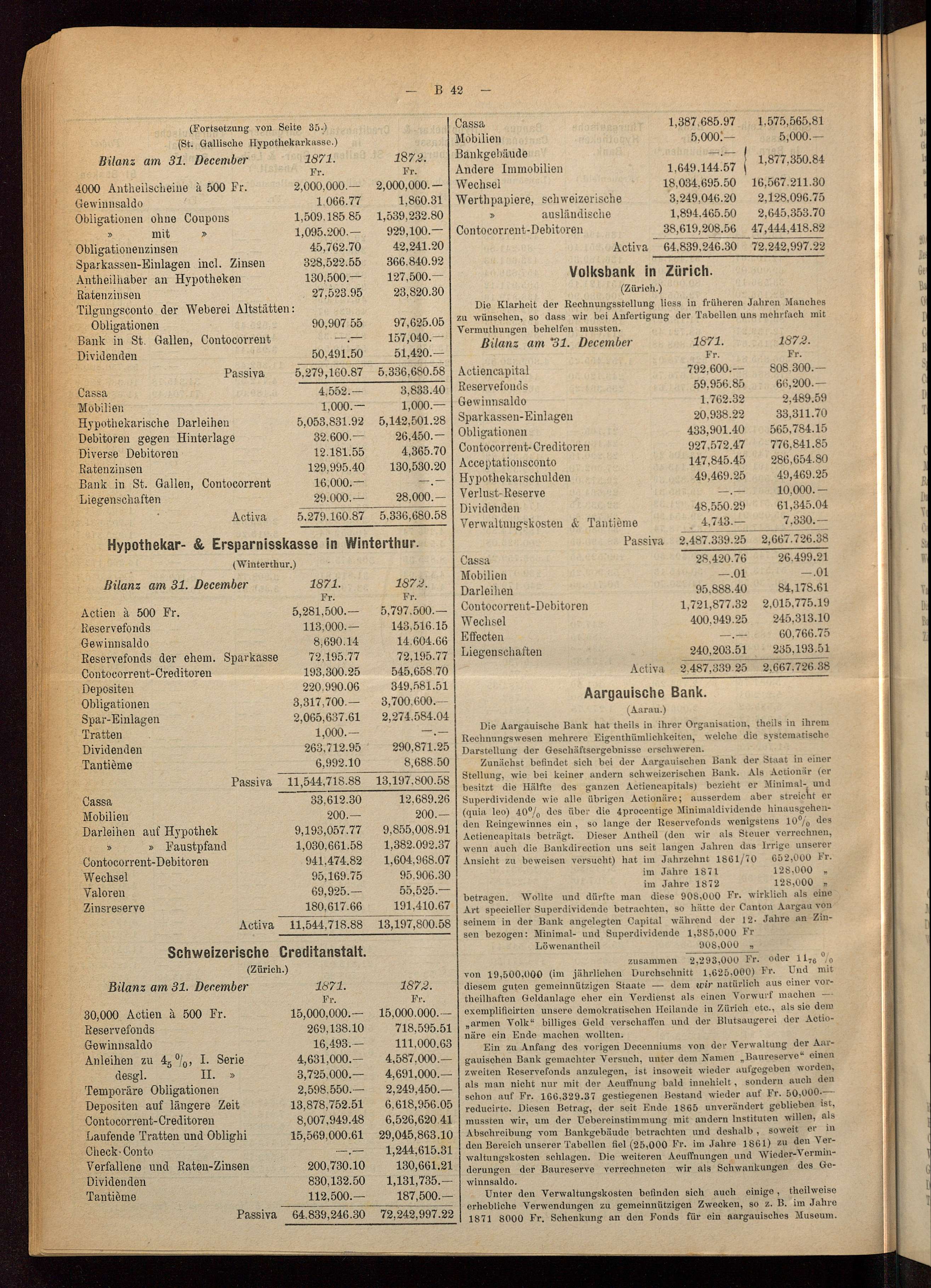{kind=link}
This issue is directly linked to issues #104 and #105, but after a first investigation about the current situation, it seems multiple importers present inconsistencies in where and how they create the iiif links and coordinates. As a result, a general issue covering all importers seemed more adapted. Sorry in advance, it is very long, but I felt that having the detailed situation somewhere would be useful to have a broader view.
Context
The two previous issues #104 and #105 highlighted that some importers generated invalid Issue JSONs for image content items. In particular the iiif-links were not correct, and depending on the importer, iiif-links or coordinates were misplaced in the content-item object in the output JSON.
Current state of the importer code and JSON files
1. BNF
iiif_linkcontains the link to the JPG image (with suffix={coords}/full/0/default.jpginstead ofinfo.json)iiif_linkis placed inside the content item's metadata (ci['m']['iiif_link'])care not present at all in the content items3://canonical-data/excelsior/issues/excelsior-1910-issues.jsonl.bz2:iiifmaps to a "full" manifest, usingIIIF_MANIFEST_SUFFIX = "full/full/0/manifest.json", (wich yields different results compared to usingIIIF_MANIFEST_SUFFIX = "info.json").s3://canonical-data/excelsior/pages/excelsior-1910/excelsior-1910-11-16-a-pages.jsonl.bz2: "iiif": "https://gallica.bnf.fr/iiif/ark:/12148/bpt6k46000007/f1/full/full/0/manifest.json" (compared to "https://gallica.bnf.fr/iiif/ark:/12148/bpt6k46000007/f1/info.json".)2. BNF-EN
iiif_linkcontains the link to the JPG image (with suffix={coords}/full/0/default.jpginstead ofinfo.json)iiif_linkis placed outside the content item's metadata (ci['iiif_link'])cis placed inside the content item's metadata (ci['m']['c'])s3://canonical-data/jdpl/issues/jdpl-1814-issues.jsonl.bz2:iiifmaps to the JPG image of the full page, usingIIIF_SUFFIX = "full/full/0/default.jpg".s3://canonical-data/jdpl/pages/jdpl-1814/jdpl-1814-05-27-a-pages.jsonl.bz2for the page corresponding to above example: "iiif": "https://gallica.bnf.fr/iiif/ark:/12148/bpt6k4209172/f4/full/full/0/default.jpg" (compared to "https://gallica.bnf.fr/iiif/ark:/12148/bpt6k4209172/f4/info.json".)3. RERO
iiif_linkcontains the link to the JPG image (with suffix={coords}/full/0/default.jpginstead ofinfo.json)iiif_linkis placed outside the content item's metadata (ci['iiif_link'])cis placed inside the content item's metadata (ci['m']['c'])s3://playground-pauline/VHT/issues/VHT-1939-issues.jsonl.bz2(recently generated canonical data using master branch):s3://canonical-datadon't have the same object structure, and no code performing a patch or correcting this issue was found. The differences are the following:iiif_linkcontains the link to the manifest (with suffix=info.json), and is placed inside the content item's metadata (ci['m']['iiif_link'])cis placed outside the content item's metadata (ci['c'])s3://canonical-data/VHT/issues/VHT-1939-issues.jsonl.bz2:iiifmaps to a manifest, using the page'sidas suffix to the impresso URL endpoint.s3://canonical-data/VHT/pages/VHT-1939/VHT-1939-01-06-a-pages.jsonl.bz2for the page corresponding to above example: "iiif": "https://impresso-project.ch/api/proxy/iiif/VHT-1939-01-06-a-p0001" (this is unchanged in the recently generated data.)4. BNL/Lux
iiif_linkcontains the link to the JSON manifest (with suffix=info.json)iiif_linkis placed inside the content item's metadata (ci['m']['iiif_link'])cis placed outside the content item's metadata (ci['c'])s3://canonical-data/tageblatt/issues/tageblatt-1913-issues.jsonl.bz2:iiifmaps to the page's JSON manifest. It should also be corrected (issue #103).s3://canonical-data/VHT/pages/VHT-1939/VHT-1939-01-06-a-pages.jsonl.bz2for the page corresponding to above example: "iiif": "https://iiif.eluxemburgensia.lu/iiif/2/ark:%2f70795%2ft8mg9c%2fpages%2f3/info.json" (corrected version: "https://iiif.eluxemburgensia.lu/image/iiif/2/ark:70795%2ft8mg9c%2fpages%2f3/info.json")5. SWA
iiifuses the filename as suffix, usingIIIF_ENDPOINT_URL = "https://ub-sipi.ub.unibas.ch/impresso", but it does not seem to work.s3://canonical-data/arbeigeber/pages/arbeitgeber-1907-01-05-a-pages.jsonl.bz2: "iiif": "https://ub-sipi.ub.unibas.ch/impresso/BAU_1_000059110_1907_0001".6. Olive
cis placed outside the content item's metadata (ci['c'])iiifmaps to a manifest, using the page'sidas suffix to the impresso URL endpoint. Same as for RERO.7. TETML (FedGaz)
iiifmaps to a manifest, using the page'sidas suffix to the impresso URL endpoint. Same as for RERO.Summary
iiif_linkplacementcplacementWhat is expected
The expected according to issues #104 and #105 output is
However, the rebuilder, and impresso-images suggests that the coordinates are expected to be outside of the content metadata in the code, ie.:
In addition, this issue suggests the coordinates should be inside the metadata, and a test was created to enforce it for RERO.
As per the Page iiif links, I have not found which module uses it, I therefore don't know if it should map to the manifest or image of the full page.
Proposed Approach
(feedback welcome)
Ideally, no canonical data that is working without issues is re-ingested, unless really necessary.
The code for all importers where relevant are matched to BNL situation, as it is the one expected in the downstream tasks. Additionally, the RERO's canonical data inside the bucket
s3://canonical-dataalready matches it and it prevents substantial re-running.s3://canonical-datafollows the same structure.A function can be implemented in the rebuilder to accommodate or check for some of the cases here, as to prevent errors.
Only BNF and BNF-EN are re-ingested to correct the various issues (in particular with the page iiif link) and unify the importers. Since they are new to this release and reprensent much less data, this should be more doable.
SWA is patched to fix the page links.
A few questions remain: @mromanello @e-maud
s3://canonical-data)?