 bednar
commented
4 years ago
bednar
commented
4 years ago Hi @gefaila,
I'm quite experienced on InfluxDB and there is nothing fundamentally wrong with having _value as being int and float for different _field values.
Yes, but Google Data Studio requires static schema. The connector internally uses pivot function to determine schema for GDS.
Schema query:
from(bucket: "my-bucket")
|> range(start: time(v: 1))
|> filter(fn: (r) => r["_measurement"] == "circleci")
|> drop(columns: ["tag1", "tag2", "tag3"])
|> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value")
|> drop(columns: ["_start", "_stop", "_time", "_measurement"])
|> limit(n:1)You could prepare Task that normalize your data into new Measurement. See - https://github.com/influxdata/influxdb-gds-connector/tree/master/examples#performance
Regards
 gefaila
gefaila

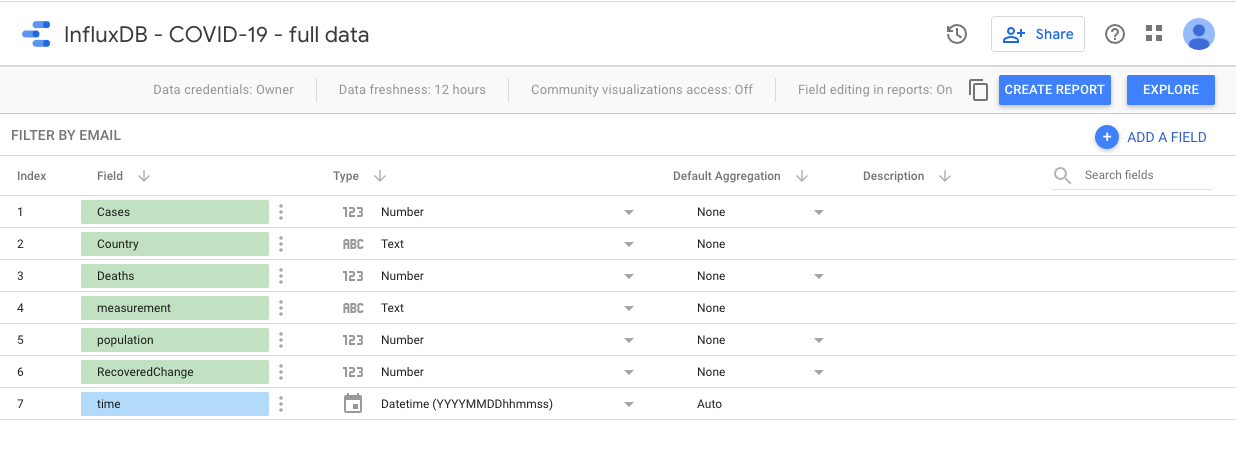

Very excited to try this connector. I have a bucket with a lot of data in. It seemed to make the connector 'fall over'
I'm quite experienced on InfluxDB and there is nothing fundamentally wrong with having _value as being int and float for different _field values. In fact it's fairly fundamental. There must be something that the connector is assuming about InfluxDB 2.0 data that is (in general) not always true.
Any ideas how I'd move forward to use this excellent tool?