 akaDJon
commented
6 years ago
akaDJon
commented
6 years ago Would be useful to know if it matters what plugins are enabled, or if the load occurs with any plugin so long as there is enough traffic. I think the best way to check would be to enable only a single plugin and see if the issue still occurs, if it does, enable another single plugin and retest.
I checked it already, Load average have reducing load, but same interval. If collect very little data, then load average almost invisible
 aldem
aldem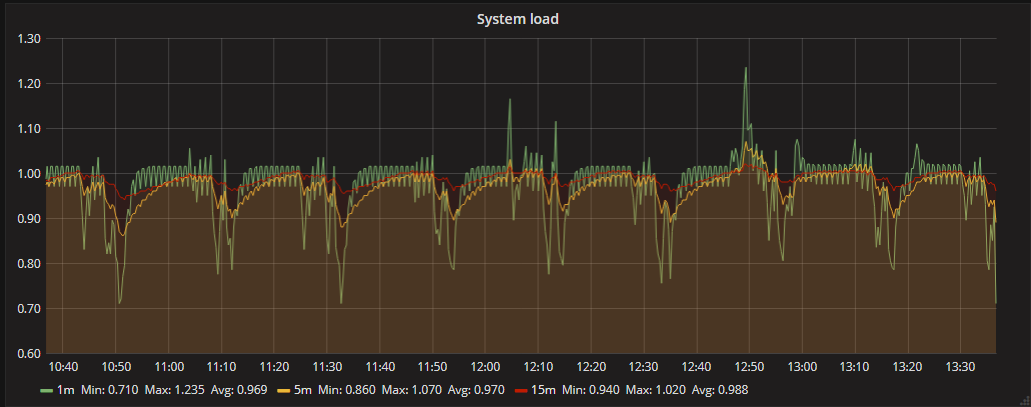
 apooniajjn
apooniajjn danielnelson
danielnelson ekeih
ekeih 8h2a
8h2a
 gentstr
gentstr Zbychad
Zbychad
 dynek
dynek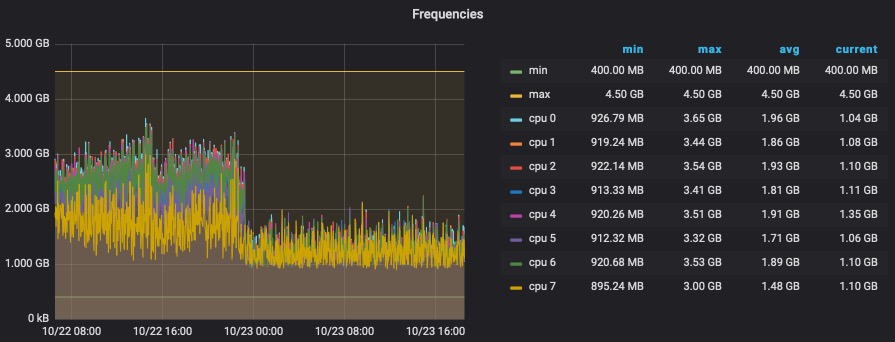
 alpiua
alpiua
every 1h 45m load average my server up to 3-4 (normal 0.2-0.5) if stop telegraf service load average dont up every 1h 45m.
Why is this happening? Is it possible to adjust the time or period?
telegraf v1.4.3 influxdb v1.3.7