 victor-eds
commented
1 week ago
victor-eds
commented
1 week ago
vs upstream:
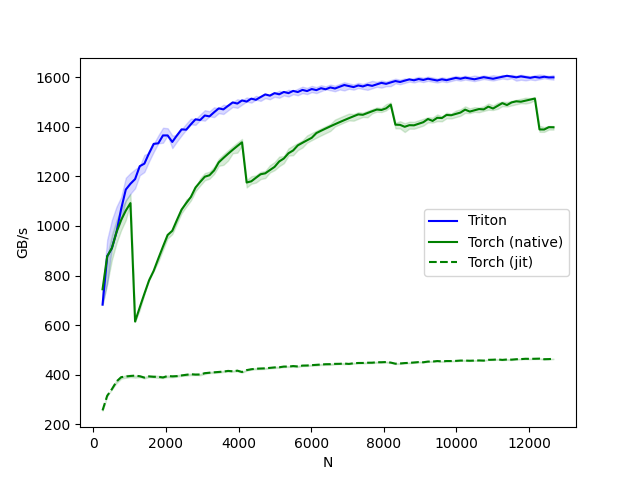
Kept subgroup size heuristics, but using 32 instead of 16 for bigger sizes as that gives better performance. Upstream constant size did not give good results at all. No need to fine tune too much as, according to the tutorial:
# You will see in the next tutorial how to auto-tune this value in a more natural
# way so you don't have to come up with manual heuristics yourself.
Reland 01c3e984490cbff3164ef97bf79cbd36628281dc, a263360050e1887a2cda0c2cac811ddd3ccaab1e, a5b32a8718b64786290a030c289c899554364e53 and 8ffdec13e6c36e12c378c3e4ffb6df5ef27150e5.
These commits introduce tuning for NVIDIA GPUs. Modify for better tuning for XPU devices:
n_rowsprograms otherwisenum_warpsdepending onBLOCK_SIZEaiming for 4 elements per work-item.num_stagesargument as we don't use that for nowCode calculating occupancy based on https://oneapi-src.github.io/oneAPI-samples/Tools/GPU-Occupancy-Calculator/
Closes #1099