 Stebalien
commented
5 years ago
Stebalien
commented
5 years ago Could you cat /proc/$(pidof ipfs)/limits and the output of ipfs swarm peers | wc -l? Go-ipfs automatically raises it's limits put probably not enough to be run as a public gateway directly, assuming that's what you're doing.
Note: You may also want to consider sticking an nginx reverse proxy out in front. That should reduce the number of inbound connections.
 koalalorenzo
koalalorenzo obo20
obo20 hsanjuan
hsanjuan sanderpick
sanderpick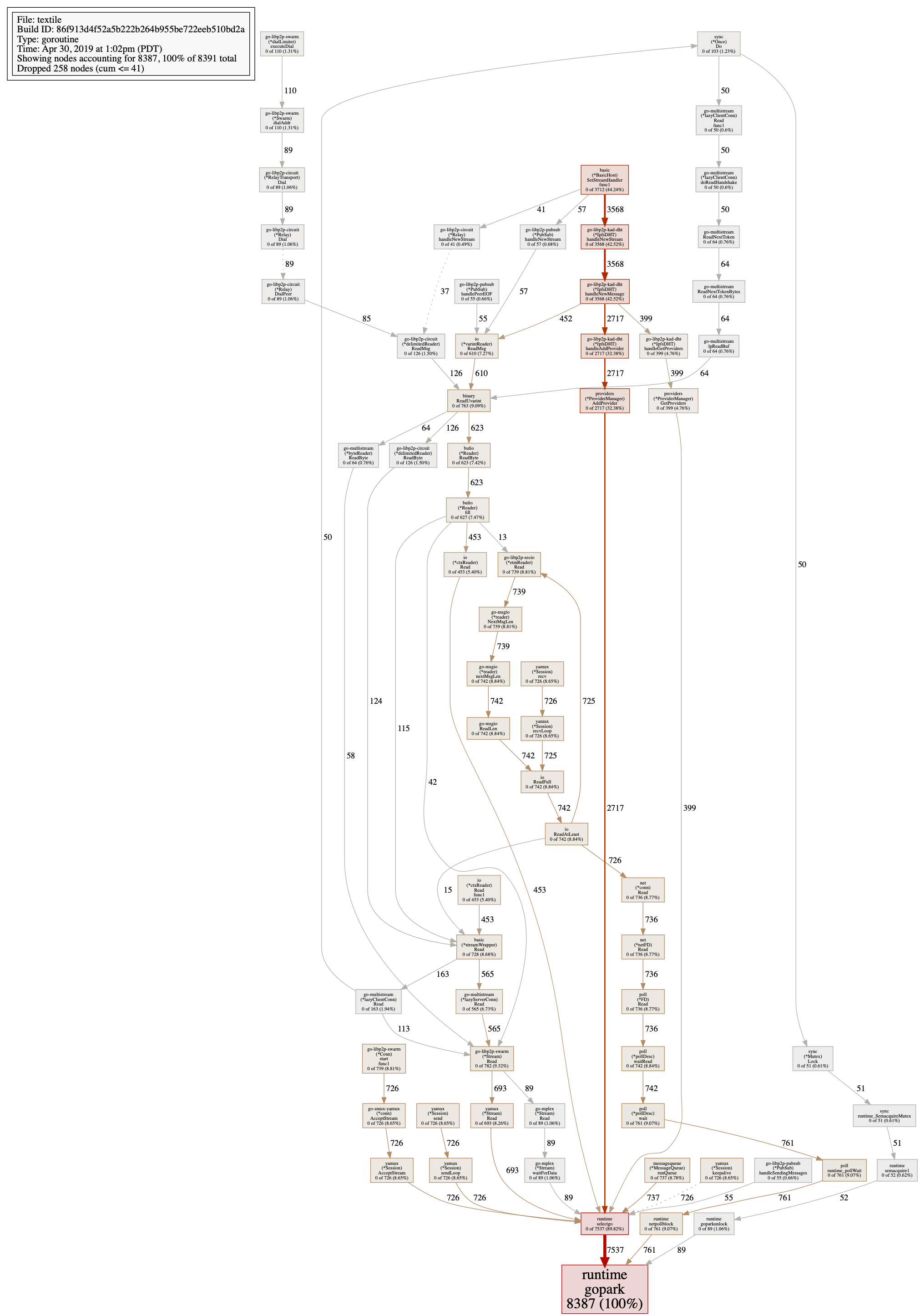
 dokterbob
dokterbob graylan0
graylan0
Version information:
Type: Bug(?)
maybe bug, maybe misconfiguration after upgrading
Description:
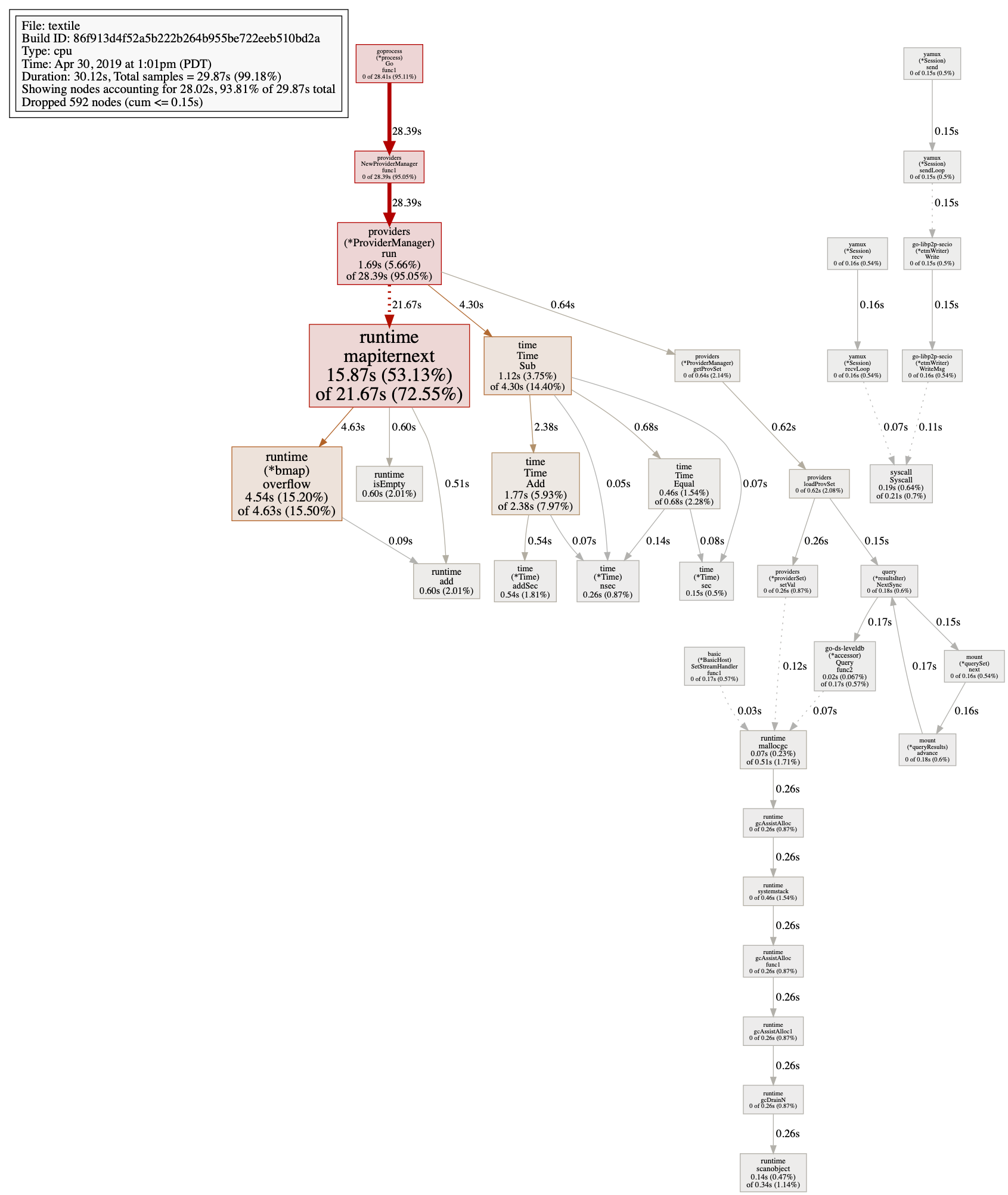
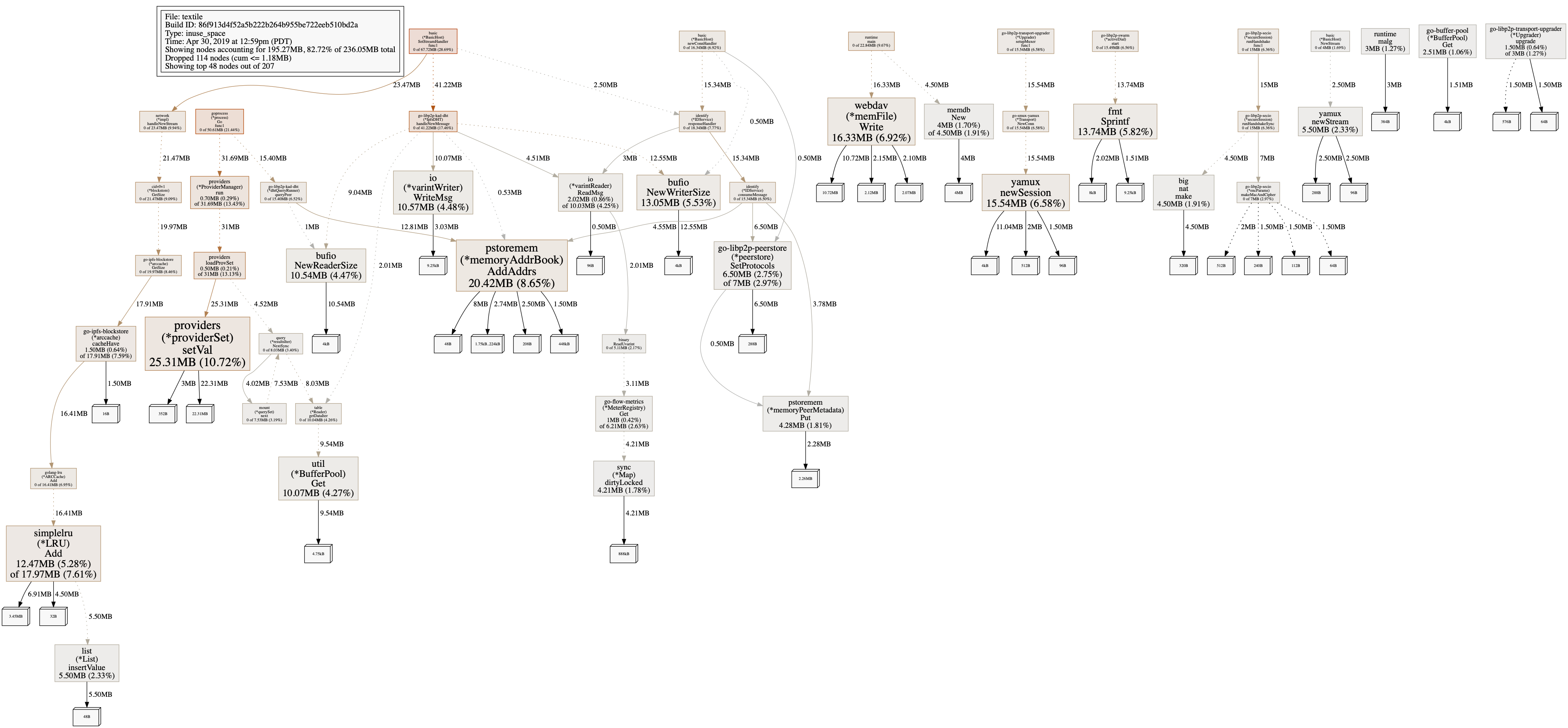
I have been meeting this issue on a set of different machines of different types with different networks and different configurations. All the nodes are providing a public writable gateway. ( https://siderus.io/ ) All of them reported this:
I found this issue after upgrading. The upgrade was executed automatically (no human touch) and all of the machines are similar with the exception of network, cpu and memory that is different based on the average traffic. Since this version we stopped using docker and started using our own Debian packages but previous tests were successful (12 hours of usage of a/b testing). The issue appeared recently and it seems that it might be caused by a set of requests from the users combined with a misconfiguration (
ulimit?)Maybe related #4102 #3792 (?)
Is this a bug or should I change the limits? How can I ensure that IPFS respects that limit?