 amstocker
commented
8 years ago
amstocker
commented
8 years ago I've been thinking about this a lot and one of the problems I keep running into is how to find other peers who are also running the aggregation software, which is presumably a separate app that runs on top of ipfs.
 davidar
davidar reit-c
reit-c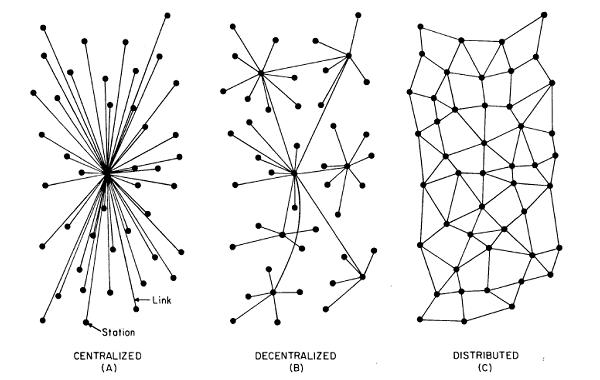
 jbenet
jbenet seidtgeist
seidtgeist sargun
sargun admiral-Guck
admiral-Guck russelldb
russelldb cmeiklejohn
cmeiklejohn brosenan
brosenan whilo
whilo daviddias
daviddias larskluge
larskluge ekmett
ekmett ion1
ion1
 haadcode
haadcode gritzko
gritzko hsribei
hsribei hackergrrl
hackergrrl Lapin0t
Lapin0t
So, a lot of the questions about "dynamic content on ipfs" seem to boil down to how to aggregate content from multiple sources. Use cases:
This should be possible with IPFS+IPNS, but it needs to be well-documented and streamlined for users.
Another issue is how to make it scale, so you're not having to aggregate millions of sources in every client (e.g. reddit on ipfs).