 eupedrosa
commented
5 years ago
eupedrosa
commented
5 years ago I have an image that can help the discussing:
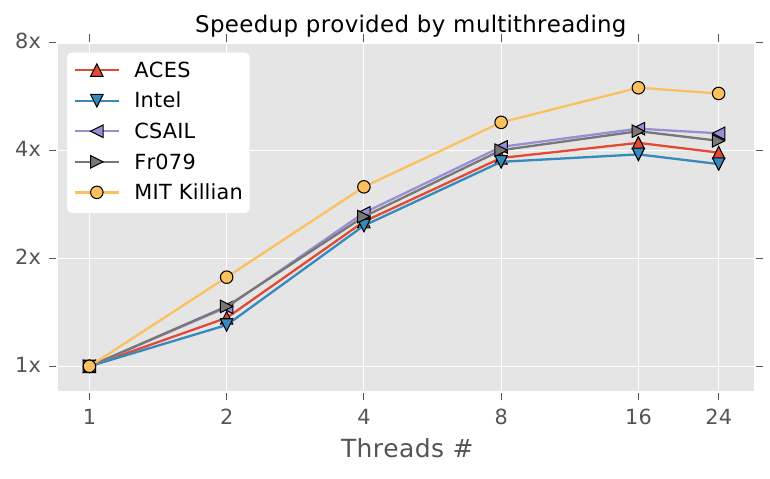 The number of particles is 30.
The number of particles is 30.
In my opinion there are a few things that can explain these behavior:
-
Multi-threading does not speedup the full execution path. It parallels scan matching and ray integration (i.e. mapping). Normalizing the weights for resampling is a sequential action. Thus doubling the threads does not provide ~2x speedup.
-
More threads can results in an execution penalty while handling the thread-pool. From the image you can see that there is an asymptotic speedup. It can even degrade performance.
-
Each particle has a map with implicit data sharing (Copy-On-Write). Writing to a map can result in concurrent access to data: mutex lock -> duplicate data -> mutex unlock. The more data is shared between particles the more times this happens.
-
CPU affinity? If I am not mistaken the linux kernel will hop logical cores when setting a process ready to run. This can result in cache misses.
 facontidavide
facontidavide
This is just a brainstorming, not really an "issue". You don't need to "solve" it, it is just an open discussion between nerds :)
I noticed that the scalability of the PF Slam is quite poor with the number of threads.
For instance, moving from 4 threads to 8 increase performance only by 50%. Note that the profiler still say that we are using 100% of 8 CPU!
I do know that there isn't such a thing as perfect scalability, but in this case I think there "might" be a bottleneck somewhere.
I inspected the code and I couldn't find any mutex or potential false sharing, but of course I haven't done an exhaustive search.