 irthomasthomas
commented
8 months ago
irthomasthomas
commented
8 months ago Related issues
393: llm-vscode - Visual Studio Marketplace
### Details
Similarity score: 0.9 - [ ] [llm-vscode - Visual Studio Marketplace](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode) #### LLM-powered Development for VSCode `llm-vscode` is a VSCode extension for all things LLM, built on top of the `llm-ls` backend. We also have extensions for `neovim`, `jupyter`, `intellij`, and previously `huggingface-vscode`. **Note:** When using the Inference API, you may encounter limitations. Consider subscribing to the PRO plan to avoid rate limiting on the free tier. [Hugging Face Pricing](https://huggingface.co/pricing#pro) #### 💻 Features - **Code Completion:** Supports "ghost-text" code completion, à la Copilot. - **Model Selection:** Requests for code generation are made via an HTTP request. You can use the Hugging Face Inference API or your own HTTP endpoint, as long as it adheres to the API specified [here](324: bigcode/tiny_starcoder_py · Hugging Face
### Details
Similarity score: 0.89 > **Note:** > > [bigcode/tiny_starcoder_py · Hugging Face](https://huggingface.co/bigcode/tiny_starcoder_py) > > TinyStarCoderPy > > This is a 164M parameters model with the same architecture as StarCoder (8k context length, MQA & FIM). It was trained on the Python data from StarCoderData for ~6 epochs which amounts to 100B tokens. > > Use > > Intended use > > The model was trained on GitHub code, to assist with some tasks like Assisted Generation. For pure code completion, we advise using our 15B models StarCoder or StarCoderBase. > > Generation > > ```python > # pip install -q transformers > from transformers import AutoModelForCausalLM, AutoTokenizer > > checkpoint = "bigcode/tiny_starcoder_py" > device = "cuda" # for GPU usage or "cpu" for CPU usage > > tokenizer = AutoTokenizer.from_pretrained(checkpoint) > model = AutoModelForCausalLM.from_pretrained(checkpoint).to(device) > > inputs = tokenizer.encode("def print_hello_world():", return_tensors="pt").to(device) > outputs = model.generate(inputs) > print(tokenizer.decode(outputs[0])) > ``` > > Fill-in-the-middle > > Fill-in-the-middle uses special tokens to identify the prefix/middle/suffix part of the input and output: > > ```python > input_text = "392: llm-vscode - Visual Studio Marketplace
### Details
Similarity score: 0.89 - [ ] [llm-vscode - Visual Studio Marketplace](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode) LLM Powered Development for VSCode ================================= We are excited to announce the release of `llm-vscode`, a VSCode extension for all things LLM! This extension uses [`llm-ls`](https://github.com/huggingface/llm-ls) as its backend and includes extensions for `neovim`, `jupyter`, `intellij`, and the previously known `huggingface-vscode`. **Note**: When using the Inference API, you may encounter some limitations. To avoid getting rate limited in the free tier, consider subscribing to the [PRO plan](https://huggingface.co/pricing#pro). Features -------- - **Code Completion**: This plugin supports "ghost-text" code completion, à la Copilot. - **Model Selection**: Requests for code generation are made via an HTTP request. You can use the Hugging Face Inference API or your own HTTP endpoint, provided it adheres to the API specified [here](https://github.com/huggingface/llm#api-reference) or [here](https://github.com/huggingface/llm/blob/main/docs/llm-ls.md). The list of officially supported models is located in the [config template section](https://github.com/huggingface/llm-vscode#configuration). - **Context Window**: The prompt sent to the model will always be sized to fit within the context window, with the number of tokens determined using tokenizers. - **Code Attribution**: Hit `Cmd+shift+a` to check if the generated code is in The Stack. This is a rapid first-pass attribution check using [stack.dataportraits.org](https://stack.dataportraits.org/). We check for sequences of at least 50 characters that match a Bloom filter. This means false positives are possible, and long enough surrounding context is necessary (see the [paper](https://arxiv.org/abs/2107.03374) for details on n-gram striding and sequence length). Installation ------------ Install like any other vscode extension. By default, this extension uses `bigcode/starcoder` & Hugging Face Inference API for the inference. HF API Token ------------ You can supply your HF API token (`hf.co/settings/token`) with the following steps: 1. `Cmd/Ctrl+Shift+P` to open VSCode command palette 2. Type: `Llm: Login` If you previously logged in with `huggingface-cli login` on your system, the extension will read the token from disk. Configuration ------------- You can check the full list of configuration settings by opening your settings page (`cmd+,`) and typing `Llm`. Endpoint -------- You can configure the endpoint to which requests will be sent. The request body will look like: ```json { "inputs": "{start token}import numpy as np\nimport scipy as sp\n{end token}def hello_world():\n print("Hello world"){middle token}", "parameters": { "max_new_tokens": 256 } } ``` Suggestion Behavior ------------------- You can tune the way the suggestions behave: - `llm.enableAutoSuggest` lets you choose to enable or disable "suggest-as-you-type" suggestions. - `llm.documentFilter` lets you enable suggestions only on specific files that match the pattern matching syntax you will provide. The object must be of type `DocumentFilter | DocumentFilter[]`. - `llm-vscode` sets two keybindings: - You can trigger suggestions with `Cmd+shift+l` by default, which corresponds to the `editor.action.inlineSuggest.trigger` command. - Code attribution is set to `Cmd+shift+a` by default, which corresponds to the `llm.attribution` command. For more information, see the [documentation](https://github.com/huggingface/llm-vscode#keybindings). LLM-LS ------ By default, `llm-ls` is bundled with the extension. When developing locally or if you built your own binary because your platform is not supported, you can set the `llm.lsp.binaryPath` setting to the path of the binary. Tokenizer --------- `llm-ls` uses tokenizers to make sure the prompt fits the context window. To configure it, you have a few options: - No tokenization, `llm-ls` will count the number of characters instead. - From a local file on your disk. - From a Hugging Face repository, `llm-ls` will attempt to download `tokenizer.json` at the root of the repository. - From an HTTP endpoint, `llm-ls` will attempt to download a file via an HTTP GET request. For more information, see the [documentation](https://github.com/huggingface/llm-vscode#tokenizer). Code Llama ---------- To test the `Code Llama 13B` model: 1. Make sure you have the latest version of this extension. 2. Make sure you have supplied an HF API token. 3. Open VSCode Settings (`cmd+,`) & type: `Llm: Config Template`. 4. From the dropdown menu, choose `codellama/CodeLlama-13b-hf`. Phind and WizardCoder ------------------- To test `Phind/Phind-CodeLlama-34B-v2` and/or `WizardLM/WizardCoder-Python-34B-V1.0`: 1. Make sure you have the latest version of this extension. 2. Make sure you have supplied an HF API token. 3. Open VSCode Settings (`cmd+,`) & type: `Llm: Config Template`. 4. From the dropdown menu, choose `Phind/Phind-CodeLlama-34B-v2` or `WizardLM/WizardCoder-Python-34B-V1.0`. For more information, see the [documentation](https://github.com/huggingface/llm-vscode#phind-and-wizardcoder). Developing ---------- To contribute to the development of this extension, follow these steps: 1. Clone this repo: `git clone https://github.com/huggingface/llm-vscode` 2. Install dependencies: `cd llm-vscode && npm i` 3. Open VSCode and run the extension with the `Launch Extension` command. Community --------- Join our community to contribute to other related projects: - [huggingface-vscode-endpoint-server](https://github.com/huggingface/huggingface-vscode-endpoint-server): Custom code generation endpoint for this repository. - [llm-vscode-inference-server](https://github.com/huggingface/llm-vscode-inference-server): An endpoint server for efficiently serving quantized open-source LLMs for code. For more information, see the [documentation](https://github.com/huggingface/llm-vscode#community). #### Suggested labels #### { "key": "llm-inference-engines", "value": "Software and tools for running inference on Large Language Models" } { "key": "llama", "value": "Models and tools related to Large Language Models" }658: OpenCodeInterpreter/README.md at main · OpenCodeInterpreter/OpenCodeInterpreter
### Details
Similarity score: 0.88 - [ ] [OpenCodeInterpreter/README.md at main · OpenCodeInterpreter/OpenCodeInterpreter](https://github.com/OpenCodeInterpreter/OpenCodeInterpreter/blob/main/README.md?plain=1) # OpenCodeInterpreter/README.md at main · OpenCodeInterpreter/OpenCodeInterpreter ## Description **OpenCodeInterpreter**: Integrating Code Generation with Execution and Refinement
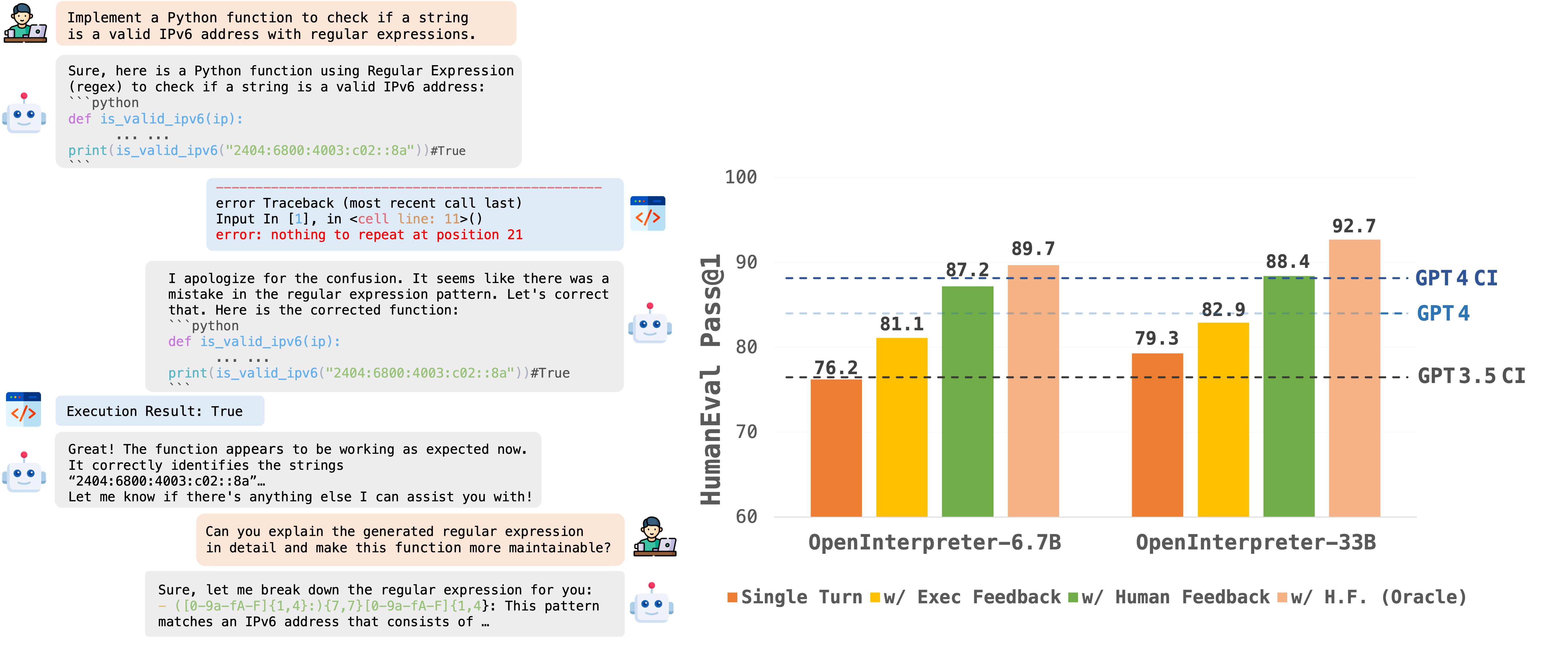
## 🌟 Upcoming Features - 💡 **Open Sourcing OpenCodeInterpreter-GM-7b Model with gemma-7b Base;** - 🚀 **Deploying Demo on HuggingFace Spaces;** ## 🔔News 🛠️[2024-02-28]: We have open-sourced the Demo Local Deployment Code with a Setup Guide. ✨[2024-02-26]: We have open-sourced the [OpenCodeInterpreter-DS-1.3b](https://huggingface.co/m-a-p/OpenCodeInterpreter-DS-1.3B) Model. 📘[2024-02-26]: We have open-sourced the [CodeFeedback-Filtered-Instruction](https://huggingface.co/datasets/m-a-p/CodeFeedback-Filtered-Instruction) Dataset. 🚀[2024-02-23]: We have open-sourced the datasets used in our project named [Code-Feedback](https://huggingface.co/datasets/m-a-p/Code-Feedback). 🔥[2024-02-19]: We have open-sourced all models in the OpenCodeInterpreter series! We welcome everyone to try out our models and look forward to your participation! 😆 ## Introduction OpenCodeInterpreter is a suite of open-source code generation systems aimed at bridging the gap between large language models and sophisticated proprietary systems like the GPT-4 Code Interpreter. It significantly enhances code generation capabilities by integrating execution and iterative refinement functionalities. ## Models All models within the OpenCodeInterpreter series have been open-sourced on Hugging Face. You can access our models via the following link: [OpenCodeInterpreter Models](https://huggingface.co/collections/m-a-p/opencodeinterpreter-65d312f6f88da990a64da456). ## Data Collection Supported by Code-Feedback, a dataset featuring 68K multi-turn interactions, OpenCodeInterpreter incorporates execution and human feedback for dynamic code refinement. For additional insights into data collection procedures, please consult the readme provided under [Data Collection](https://github.com/OpenCodeInterpreter/OpenCodeInterpreter/blob/main/data_collection/README.md). ## Evaluation Our evaluation framework primarily utilizes HumanEval and MBP, alongside their extended versions, HumanEval+ and MBPP+, leveraging the [EvalPlus framework](https://github.com/evalplus/evalplus) for a more comprehensive assessment. For specific evaluation methodologies, please refer to the [Evaluation README](https://github.com/OpenCodeInterpreter/OpenCodeInterpreter/blob/main/evaluation/README.md) for more details. ## Contact If you have any inquiries, please feel free to raise an issue or reach out to us via email at: xiangyue.work@gmail.com, zhengtianyu0428@gmail.com. We're here to assist you! [URL](https://github.com/OpenCodeInterpreter/OpenCodeInterpreter/blob/main/README.md?plain=1) #### Suggested labels #### {'label-name': 'frameworks', 'label-description': 'Frameworks and tools used for evaluation and assessment.', 'gh-repo': 'OpenCodeInterpreter/OpenCodeInterpreter', 'confidence': 58.17}
189: deepseek-coder-6.7b-instruct-8.0bpw-h8-exl2-2 · Hugging Face
### Details
Similarity score: 0.87 - [ ] I cannot get this to output anything but gibberish. - [x] [LoneStriker/deepseek-coder-6.7b-instruct-8.0bpw-h8-exl2-2 · Hugging Face](https://huggingface.co/LoneStriker/deepseek-coder-6.7b-instruct-8.0bpw-h8-exl2-2) 1. Introduction of Deepseek Coder Deepseek Coder is composed of a series of code language models, each trained from scratch on 2T tokens, with a composition of 87% code and 13% natural language in both English and Chinese. We provide various sizes of the code model, ranging from 1B to 33B versions. Each model is pre-trained on project-level code corpus by employing a window size of 16K and a extra fill-in-the-blank task, to support project-level code completion and infilling. For coding capabilities, Deepseek Coder achieves state-of-the-art performance among open-source code models on multiple programming languages and various benchmarks.628: LLaVA/README.md at main · haotian-liu/LLaVA
### Details
Similarity score: 0.87 - [ ] [LLaVA/README.md at main · haotian-liu/LLaVA](https://github.com/haotian-liu/LLaVA/blob/main/README.md?plain=1) # LLaVA/README.md at main · haotian-liu/LLaVA ## 🌋 LLaVA: Large Language and Vision Assistant *Visual instruction tuning towards large language and vision models with GPT-4 level capabilities.* [📢 LLaVA-NeXT Blog](https://llava-vl.github.io/blog/2024-01-30-llava-next/) [Project Page](https://llava-vl.github.io/) [Demo](https://llava.hliu.cc/) [Data](https://github.com/haotian-liu/LLaVA/blob/main/docs/Data.md) [Model Zoo](https://github.com/haotian-liu/LLaVA/blob/main/docs/MODEL_ZOO.md) 🤝Community Contributions: [llama.cpp](https://github.com/ggerganov/llama.cpp/pull/3436) [Colab](https://github.com/camenduru/LLaVA-colab) [🤗Space](https://huggingface.co/spaces/badayvedat/LLaVA) [Replicate](https://replicate.com/yorickvp/llava-13b) [AutoGen](https://github.com/microsoft/autogen/blob/main/notebook/agentchat_lmm_llava.ipynb) [BakLLaVA](https://github.com/SkunkworksAI/BakLLaVA) **Improved Baselines with Visual Instruction Tuning** [Paper](https://arxiv.org/abs/2310.03744) [HF](https://huggingface.co/papers/2310.03744)Haotian Liu, Chunyuan Li, Yuheng Li, Yong Jae Lee **Visual Instruction Tuning** (NeurIPS 2023, Oral) [Paper](https://arxiv.org/abs/2304.08485) [HF](https://huggingface.co/papers/2304.08485)
Haotian Liu*, Chunyuan Li*, Qingyang Wu, Yong Jae Lee (*Equal Contribution) ## Release - [1/30] 🔥 LLaVA-NeXT (LLaVA-1.6) is out! With additional scaling to LLaVA-1.5, LLaVA-NeXT-34B outperforms Gemini Pro on some benchmarks. It can now process 4x more pixels and perform more tasks/applications than before. Check out the [blog post](https://llava-vl.github.io/blog/2024-01-30-llava-next/), and explore the [demo](https://llava.hliu.cc/)! Models are available in [Model Zoo](https://github.com/haotian-liu/LLaVA/blob/main/docs/MODEL_ZOO.md). Training/eval data and scripts coming soon. - [11/10] [LLaVA-Plus](https://llava-vl.github.io/llava-plus/) is released: Learning to Use Tools for Creating Multimodal Agents, with LLaVA-Plus (LLaVA that Plug and Learn to Use Skills). [Project Page](https://llava-vl.github.io/llava-plus/) [Demo](https://llavaplus.ngrok.io/) [Code](https://github.com/LLaVA-VL/LLaVA-Plus-Codebase) [Paper](https://arxiv.org/abs/2311.05437) - [11/2] [LLaVA-Interactive](https://llava-vl.github.io/llava-interactive/) is released: Experience the future of human-AI multimodal interaction with an all-in-one demo for Image Chat, Segmentation, Generation and Editing. [Project Page](https://llava-vl.github.io/llava-interactive/) [Demo](https://llavainteractive.ngrok.io/) [Code](https://github.com/LLaVA-VL/LLaVA-Interactive-Demo) [Paper](https://arxiv.org/abs/2311.00571) - [10/26] 🔥 LLaVA-1.5 with LoRA achieves comparable performance as full-model finetuning, with a reduced GPU RAM requirement (ckpts) (script). We also provide a doc on how to finetune LLaVA-1.5 on your own dataset with LoRA. - [10/12] Check out the Korean LLaVA (Ko-LLaVA), created by ETRI, who has generously supported our research! [🤗 Demo](https://huggingface.co/spaces/etri-vilab/Ko-LLaVA) - [10/5] 🔥 LLaVA-1.5 is out! Achieving SoTA on 11 benchmarks, with just simple modifications to the original LLaVA, utilizes all public data, completes training in ~1 day on a single 8-A100 node, and surpasses methods like Qwen-VL-Chat that use billion-scale data. Check out the technical report, and explore the demo! Models are available in Model Zoo. The training data and scripts of LLaVA-1.5 are released here, and evaluation scripts are released here. - [9/26] LLaVA is improved with reinforcement learning from human feedback (RLHF) to improve fact grounding and reduce hallucination. Check out the new SFT and RLHF checkpoints at project LLavA-RLHF. - [9/22] LLaVA is accepted by NeurIPS 2023 as oral presentation, and LLaVA-Med is accepted by NeurIPS 2023 Datasets and Benchmarks Track as spotlight presentation.
More
- [11/6] Support Intel dGPU and CPU platforms. More details here. - [10/12] LLaVA is now supported in llama.cpp with 4-bit / 5-bit quantization support! - [10/11] The training data and scripts of LLaVA-1.5 are released here, and evaluation scripts are released here! - [10/10] Roboflow Deep Dive: First Impressions with LLaVA-1.5. - [9/20] We summarize our empirical study of training 33B and 65B LLaVA models in a note. Further, if you are interested in the comprehensive review, evolution and trend of multimodal foundation models, please check out our recent survey paper "Multimodal Foundation Models: From Specialists to General-Purpose Assistants".

blog/starcoder2.md at main · huggingface/blog
StarCoder2 and The Stack v2
BigCode is releasing StarCoder2 the next generation of transparently trained open code LLMs. All StarCoder2 variants were trained on The Stack v2, a new large and high quality code dataset. We release all models, datasets, and the processing as well as the training code. Check out the paper for details.
What is StarCoder2?
StarCoder2 is a family of open LLMs for code and comes in 3 different sizes with 3B, 7B and 15B parameters. StarCoder2-15B is trained on over 4 trillion tokens and 600+ programming languages from The Stack v2. All models use Grouped Query Attention, a context window of 16,384 tokens with a sliding window attention of 4,096 tokens, and were trained using the Fill-in-the-Middle.
StarCoder2 offers three model sizes: a 3 billion-parameter model trained by ServiceNow, a 7 billion-parameter model trained by Hugging Face, and a 15 billion-parameter model trained by NVIDIA with NVIDIA NeMo and trained on NVIDIA accelerated infrastructure:
StarCoder2-15B is the best in its size class and matches 33B+ models on many evaluations. StarCoder2-3B matches the performance of StarCoder1-15B:
What is The Stack v2?
The Stack v2 is the largest open code dataset suitable for LLM pretraining. The Stack v2 is larger than The Stack v1, follows an improved language and license detection procedure, and better filtering heuristics. In addition, the training dataset is grouped by repositories, allowing to train models with repository context.
This dataset is derived from the Software Heritage archive, the largest public archive of software source code and accompanying development history. Software Heritage is an open, non profit initiative to collect, preserve, and share the source code of all publicly available software, launched by Inria, in partnership with UNESCO. We thank Software Heritage for providing access to this invaluable resource. For more details, visit the Software Heritage website.
The Stack v2 can be accessed through the Hugging Face Hub.
About BigCode
BigCode is an open scientific collaboration led jointly by Hugging Face and ServiceNow that works on the responsible development of large language models for code.
Links
Models
Data & Governance
Others
You can find all the resources and links at huggingface.co/bigcode!"
URL: blog/starcoder2.md at main · huggingface/blog
Suggested labels