 irthomasthomas
commented
4 months ago
irthomasthomas
commented
4 months ago Related issues
393: llm-vscode - Visual Studio Marketplace
### Details
Similarity score: 0.88 - [ ] [llm-vscode - Visual Studio Marketplace](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode) #### LLM-powered Development for VSCode `llm-vscode` is a VSCode extension for all things LLM, built on top of the `llm-ls` backend. We also have extensions for `neovim`, `jupyter`, `intellij`, and previously `huggingface-vscode`. **Note:** When using the Inference API, you may encounter limitations. Consider subscribing to the PRO plan to avoid rate limiting on the free tier. [Hugging Face Pricing](https://huggingface.co/pricing#pro) #### 💻 Features - **Code Completion:** Supports "ghost-text" code completion, à la Copilot. - **Model Selection:** Requests for code generation are made via an HTTP request. You can use the Hugging Face Inference API or your own HTTP endpoint, as long as it adheres to the API specified [here](498: CodeGPTPlus/deepseek-coder-1.3b-typescript · Hugging Face
### Details
Similarity score: 0.86 - [ ] [CodeGPTPlus/deepseek-coder-1.3b-typescript · Hugging Face](https://huggingface.co/CodeGPTPlus/deepseek-coder-1.3b-typescript) # CodeGPTPlus/deepseek-coder-1.3b-typescript This is a fine-tuned model by the CodeGPT team, specifically crafted for generating expert code in TypeScript. It is fine-tuned from `deepseek-ai/deepseek-coder-1.3b-base` with a dataset of 0.5B tokens, making it an excellent choice for precise and efficient TypeScript code generation. The model uses a 16K window size and an additional fill-in-the-middle task for project-level code completion. ## How to Use This model is for completion purposes only. Here are some examples of how to use the model: ### Running the model on a GPU ```python from transformers import AutoTokenizer, AutoModelForCausalLM tokenizer = AutoTokenizer.from_pretrained("CodeGPTPlus/deepseek-coder-1.3b-typescript", trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained("CodeGPTPlus/deepseek-coder-1.3b-typescript", trust_remote_code=True).cuda() input_text = """<|fim begin|>function quickSort(arr: number[]): number[] { if (arr.length <= 1) { return arr; } const pivot = arr[0]; const left = []; const right = []; <|fim hole|> return [...quickSort(left), pivot, ...quickSort(right)]; }<|fim end|>""" inputs = tokenizer(input_text, return_tensors="pt").to(model.device) outputs = model.generate(**inputs, max_length=256) print(tokenizer.decode(outputs[0], skip_special_tokens=True)) ``` ### Running with Ollama - Model: [https://ollama.ai/codegpt/deepseek-coder-1.3b-typescript](https://ollama.ai/codegpt/deepseek-coder-1.3b-typescript) - Command: `ollama run codegpt/deepseek-coder-1.3b-typescript` ### Running with Ollama and CodeGPT Autocomplete in VSCode - Documentation: [https://docs.codegpt.co/docs/tutorial-features/code\_autocompletion](https://docs.codegpt.co/docs/tutorial-features/code_autocompletion) - Select "Ollama - codegpt/deepseek-coder-1.3b-typescript" in the autocomplete model selector. ### Fill In the Middle (FIM) ```python <|fim begin|>function quickSort(arr: number[]): number[] { if (arr.length <= 1) { return arr; } const pivot = arr[0]; const left = []; const right = []; <|fim hole|> return [...quickSort(left), pivot, ...quickSort(right)]; }<|fim end|> ``` ### Training Procedure The model was trained using the following hyperparameters: - learning\_rate: 2e-05 - train\_batch\_size: 20 - eval\_batch\_size: 20 - seed: 42 - gradient\_accumulation\_steps: 2 - total\_train\_batch\_size: 40 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-06 - lr\_scheduler\_type: cosine - lr\_scheduler\_warmup\_steps: 261 - num\_epochs: 1 For more information, visit the [model page](https://huggingface.co/CodeGPTPlus/deepseek-coder-1.3b-typescript). #### Suggested labels #### { "label-name": "TypeScript-Code-Generation", "description": "Model for generating TypeScript code", "repo": "CodeGPTPlus/deepseek-coder-1.3b-typescript", "confidence": 70.59 }658: OpenCodeInterpreter/README.md at main · OpenCodeInterpreter/OpenCodeInterpreter
### Details
Similarity score: 0.86 - [ ] [OpenCodeInterpreter/README.md at main · OpenCodeInterpreter/OpenCodeInterpreter](https://github.com/OpenCodeInterpreter/OpenCodeInterpreter/blob/main/README.md?plain=1) # OpenCodeInterpreter/README.md at main · OpenCodeInterpreter/OpenCodeInterpreter ## Description **OpenCodeInterpreter**: Integrating Code Generation with Execution and Refinement
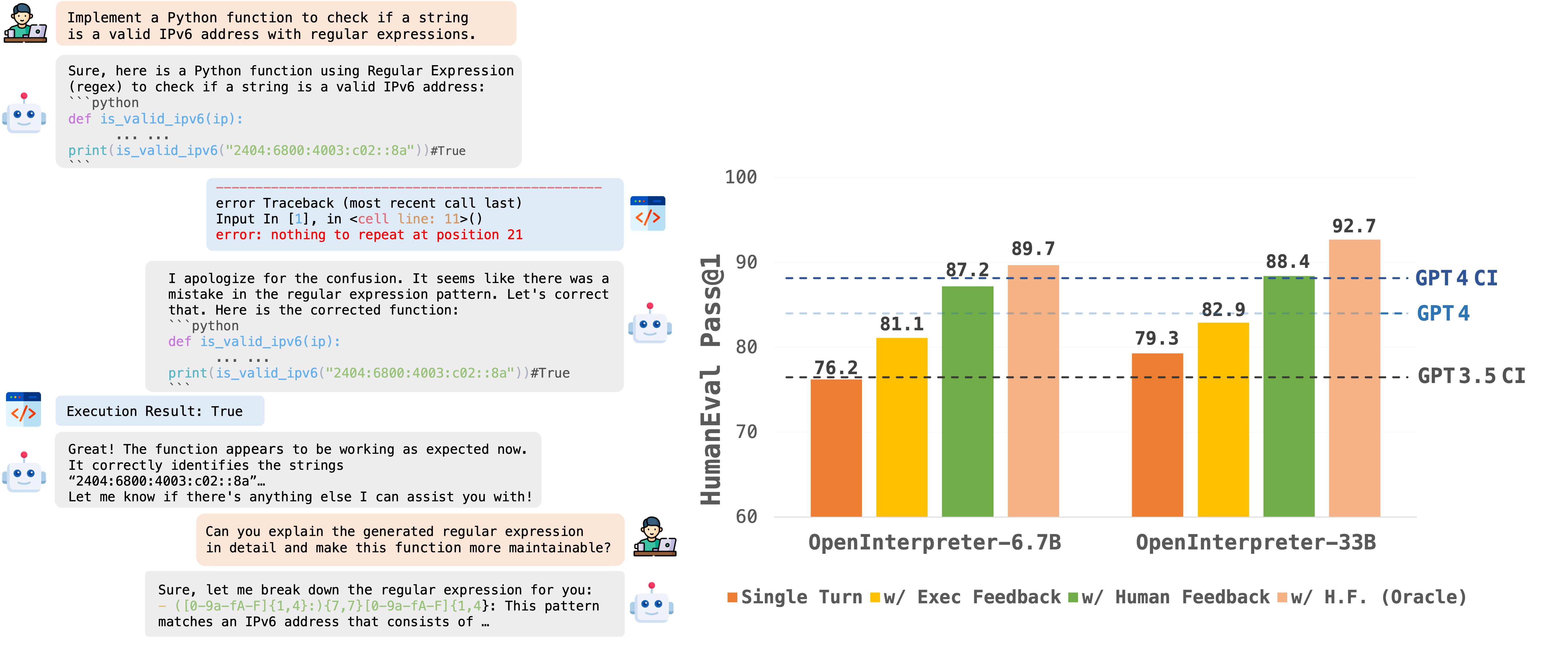
## 🌟 Upcoming Features - 💡 **Open Sourcing OpenCodeInterpreter-GM-7b Model with gemma-7b Base;** - 🚀 **Deploying Demo on HuggingFace Spaces;** ## 🔔News 🛠️[2024-02-28]: We have open-sourced the Demo Local Deployment Code with a Setup Guide. ✨[2024-02-26]: We have open-sourced the [OpenCodeInterpreter-DS-1.3b](https://huggingface.co/m-a-p/OpenCodeInterpreter-DS-1.3B) Model. 📘[2024-02-26]: We have open-sourced the [CodeFeedback-Filtered-Instruction](https://huggingface.co/datasets/m-a-p/CodeFeedback-Filtered-Instruction) Dataset. 🚀[2024-02-23]: We have open-sourced the datasets used in our project named [Code-Feedback](https://huggingface.co/datasets/m-a-p/Code-Feedback). 🔥[2024-02-19]: We have open-sourced all models in the OpenCodeInterpreter series! We welcome everyone to try out our models and look forward to your participation! 😆 ## Introduction OpenCodeInterpreter is a suite of open-source code generation systems aimed at bridging the gap between large language models and sophisticated proprietary systems like the GPT-4 Code Interpreter. It significantly enhances code generation capabilities by integrating execution and iterative refinement functionalities. ## Models All models within the OpenCodeInterpreter series have been open-sourced on Hugging Face. You can access our models via the following link: [OpenCodeInterpreter Models](https://huggingface.co/collections/m-a-p/opencodeinterpreter-65d312f6f88da990a64da456). ## Data Collection Supported by Code-Feedback, a dataset featuring 68K multi-turn interactions, OpenCodeInterpreter incorporates execution and human feedback for dynamic code refinement. For additional insights into data collection procedures, please consult the readme provided under [Data Collection](https://github.com/OpenCodeInterpreter/OpenCodeInterpreter/blob/main/data_collection/README.md). ## Evaluation Our evaluation framework primarily utilizes HumanEval and MBP, alongside their extended versions, HumanEval+ and MBPP+, leveraging the [EvalPlus framework](https://github.com/evalplus/evalplus) for a more comprehensive assessment. For specific evaluation methodologies, please refer to the [Evaluation README](https://github.com/OpenCodeInterpreter/OpenCodeInterpreter/blob/main/evaluation/README.md) for more details. ## Contact If you have any inquiries, please feel free to raise an issue or reach out to us via email at: xiangyue.work@gmail.com, zhengtianyu0428@gmail.com. We're here to assist you! [URL](https://github.com/OpenCodeInterpreter/OpenCodeInterpreter/blob/main/README.md?plain=1) #### Suggested labels #### {'label-name': 'frameworks', 'label-description': 'Frameworks and tools used for evaluation and assessment.', 'gh-repo': 'OpenCodeInterpreter/OpenCodeInterpreter', 'confidence': 58.17}
language-model.md - vscode-docs [GitHub] - Visual Studio Code - GitHub
DESCRIPTION:
DO NOT TOUCH — Managed by doc writer
ContentId: 9bdc3d4e-e6ba-43d3-bd09-2e127cb63ce7 DateApproved: 02/28/2024
Summarize the whole topic in less than 300 characters for SEO purpose
MetaDescription: A guide to adding AI-powered features to a VS Code extension by using language models and natural language understanding.
Language Model API
package.jsonto make it easy for users to find your extension. Add "AI" to thecategoriesfield in yourpackage.json. If your extension contributes a Chat Participant, add "Chat" as well.Related content
URL: language-model.md
Suggested labels
{'label-name': 'VSCode-Extension-Guide', 'label-description': 'Content related to creating VS Code extensions with language models.', 'gh-repo': 'microsoft/vscode-docs', 'confidence': 62.54}